

2025년 새해 인사 드린지가 얼마 안 지났지만, 진짜 우리 새해 명절, 설날이 다가왔네요 ^.^ 구독자 여러분, 항상 건강하고 즐거운 일만 가득한 을사년 되시기 기원하겠습니다!
작년 중순 이후, 지금까지도 계속해서, 거침없이 ‘Super Intelligence (초지능)’, 그리고 ‘생각하는 컴퓨터’, 궁극적으로 AGI를 향해 박차를 가하는 수많은 아이디어, 그리고 스타트업들의 경쟁을 눈 앞에서 보고 있는데요.
튜링 포스트 코리아의 여러 글에서 말씀드렸다시피, AGI가 무엇인지 정의 자체도 아직 명확히 합의된 바 없고, 다소 형이상학적으로 흐르기 쉬운 AGI에 대한 논의보다 구체적으로 오늘날의 AI로 무엇을 할 수 있고 어떻게 써야 하는지에 대해 이야기하는게 훨씬 더 영양가 있다고 생각하는 입장이기는 합니다…
…만, 역시 AGI에 관심을 가진 분들도 많으시고, 실질적으로 AGI에 한 발 한 발 다가가기 위한 의미있는 연구가 점점 많이 등장하는 현 시점이니, 그에 관한 글도 계속해서 쓰게 되네요. ^.^;
금주 FOD에서는, 작년 말 오픈AI에서 발표한 o3를 통해서 비교적 널리 알려졌다고 할 수 있는, ‘프로그램 합성 (Program Synthesis; 편의상 이 글에서는 Program Synthesis로 표기하겠습니다)’이 AGI라는 그림을 맞추는데 필요한 하나의 퍼즐 조각이 될 수 있을지, 한 번 함께 생각할 기회를 가져볼까 합니다.
‘Program Synthesis’는 직접 코드를 모두 작성하지 않고도 원하는 결과나 의도를 설명하면 누군가가 자동으로 그에 맞는 프로그램을 만들어주는 기술이라고 할 수 있을 겁니다. 여기서 ‘결과나 의도’를 Program++, ‘누군가’를 Synthesizer - 사람이든 AI든요 - 라고 한다면 아래와 같은 개념도가 될 거구요.
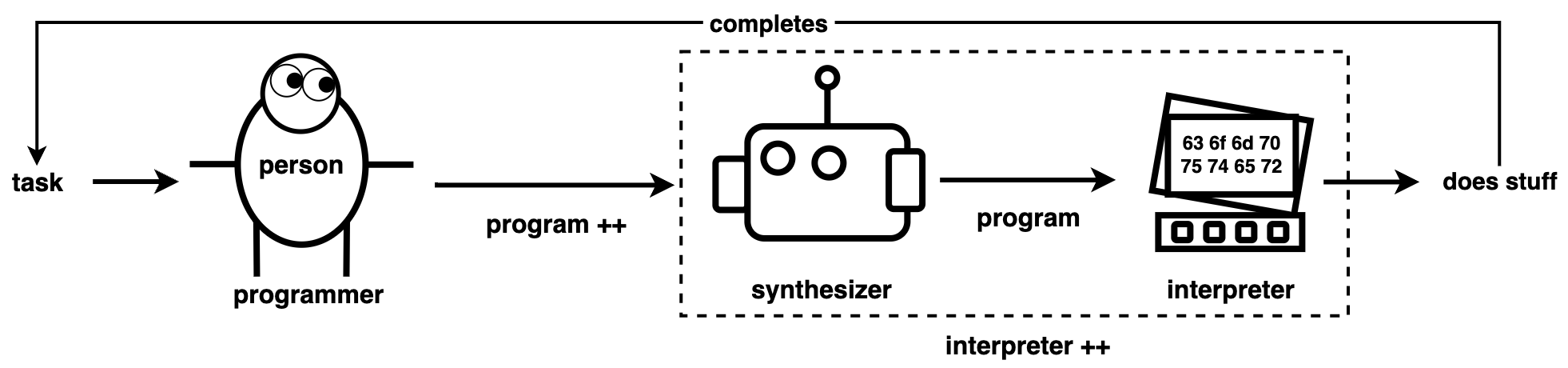
Program Synthesis 개념. Image Credit: A Minimalist Guide to Program Synthesis
아주 간단한 예시를 들어보면:
엑셀에서 "이 열의 모든 이메일 주소에서 도메인만 추출해줘" 라고 하면, 자동으로 필요한 함수를 만들어주는 것
"두 숫자를 입력받아서 최대공약수를 구하는 프로그램을 만들어줘" 라고 하면, AI가 알아서 적절한 알고리즘을 선택해서 코드를 작성해주는 것
등이 모두 Program Synthesis - 간단한 형태긴 해도 - 의 종류라고 할 수 있겠죠.
Program Synthesis가 최근 AI의 맥락에서 주목을 받은 건, 아무래도 2019년, Francois Chollet가 논문 ‘On the Measure of Intelligence’를 발표했을 때였다고 생각합니다. 이 논문의 내용과 의의에 대해서 아주 간단히 튜링 포스트 코리아에서 커버한 적도 있는데요:

어쨌든, Francois는 이 논문에서 사람과 같은 수준의 일반 지능을 평가하겠다는 목적으로 설계한 벤치마크, ARC (Abstraction and Reasoning Corpus)를 소개했습니다. Francois는 딥러닝만으로는 ‘추론’, ‘일반화’에 있어서 벽에 부딪힐 수 밖에 없다고 하면서, ‘Program Synthesis’가 진정한 지능 시스템을 만드는 핵심 단계가 될 거라고 주장했습니다. AI가 특정한 작업에 맞춤화된 작은 프로그램들을 작성하면서 다이나믹하게 해결책을 생성할 수 있게 하는 방법으로, Program Synthesis는 기존의 ‘정적 (Static)’인 작업 수행 패러다임에서 ‘적응성 (Adaptability)’, 그리고 ‘추론 (Reasoning)’ 쪽으로 그 무게 중심을 옮깁니다.
그리고 2025년 현재, ARC-AGI는 AGI를 목표로 하는 모델들을 평가하는 중요한 벤치마크 중 하나가 되었습니다. Francois는 최근 자신의 아이디어를 더 발전시켜서 Ndea라는 연구소를 설립했는데요, 이 조직을 통해서 딥러닝과 Program Synthesis를 어떻게 결합하면 좋을지 탐구해서 AGI를 발전시키는데 전념하겠다고 하네요. 아무래도 Francois는 이 두 가지 - 딥러닝과 Program Synthesis - 의 결합이 ‘AI가 추상적으로 추론하고, 최소한의 데이터로부터도 잘 학습해서, 이전보다 더 광범위한 문제들을 해결할 수 있게 하는 길’이 될 거라고 믿는 것 같습니다.
그럼 이제, Program Synthesis가 어디에서 왔는지, 그리고 어떻게 딥러닝과 결합할 수 있는지 한 번 살펴보죠.
Program Synthesis의 발자취
거슬러 올라가면, Program Synthesis의 연원도 우리 모두가 애정하는 (^.^) 앨런 튜링에 가 닿습니다
초기 아이디어
1945년, 앨런 튜링은 ‘자율적으로 프로그램을 생성할 수 있는 기계’를 구상했는데요. 그렇지만 공식적인 근원은 1957년 알론조 처치 (Alonzo Church)가 수학적인 요구사항 (Mathematical Requirements)로부터 회로를 합성하는 아이디어를 제안하면서 시작되었다는게 중론인 듯 합니다. 이걸 지금은 ‘Church 문제’라고 부릅니다.

공식적인 토대의 확립 (1960년대 ~ 1980년대)
이 Program Synthesis 분야는 Büchi와 Landweber (1969)의 ‘오토마타 이론’ 접근법, 그리고 Manna와 Waldinger (1980년경)의 연구 등에 힘입어서 더 강력한 이론적인 기반을 얻게 되었는데요. 이 시기에는 주로 논리적 추론과 연역적 기법에 기반해서 프로그램을 합성할 수 있게 해 주는 형식적 방법론을 개발하는 데 초점을 맞췄습니다.실용적인 진화 (1990년대 ~ 2010년대)
이 시기에는 Program Synthesis를 더 실용적 관점에서 접근했는데요. 프로그래머가 ‘자동으로 채워질 수 있도록 남겨진 빈 칸이 있는 프로그램 일부를 제공해서 시스템이 완성’하도록 하는 스케칭 (2006년 Armando Solar-Lezama의 SKETCH 시스템으로 도입)이라든가, 사용자가 제공한 입출력 예시들을 보고 패턴을 학습해서 데이터 변환을 자동화하는 예시 기반 프로그래밍(Programming by Example; PBE) (2010년대 Sumit Gulwani가 개발한 엑셀의 Flash Fill과 같은 도구로 대중화됨) 등을 포함합니다.현대적인 부활 (2010년대 ~ 2020년대)
21세기에는, 특히 ‘형식 검증 커뮤니티’ 내에서 Program Synthesis에 대한 관심이 다시 부활했는데요. 이런 흐름이 ‘논리적 명세 (Logical Specifications)’와 ‘문법적 제약(Grammatical Constraints)’을 결합해서 합성 과정을 가이드하는 SyGuS(Syntax-guided Synthesis)과 같은 발전으로 이어졌습니다.
오랜 시간 Program Synthesis와 머신러닝, 즉 AI는 각자 독립적인 발전 경로를 걸어왔지만, 이제 이 두 주제 간의 협업과 교류 활동이 탄력을 받고 있는 걸 볼 수 있습니다. 이런 적극적인 통합이 가능하게 된, 그리고 유망하다고 믿게 된 몇 가지 요인이 있는데요:
거대해진 컴퓨팅 파워
GPU의 발전을 떼놓을 수 없죠. Program Synthesis와 머신러닝 알고리즘의 복잡성을 처리할 수 있는 충분한, 그리고 계속해서 강력해지는 컴퓨팅 자원을 확보하는 건, 연구자들이 더 정교하게 기술을 탐구하고 더 큰 문제들을 다루는데 핵심적 요인입니다.거대한 데이터셋을 사용할 수 있게 됨
빅데이터의 부상, 그리고 온라인 코드 리포지토리의 확산, 이 두 가지 요소가 바로 Program Synthesis에 적용할 수 있는 머신로닝 모델을 훈련시키기 위한 원천이 됩니다. 이런 데이터셋을 활용해서 검색 과정을 가이드하고, 예시로부터 패턴을 학습하고, 새로운 상황이 닥치더라도 적응할 수 있는 접근 방식을 발전시키는 원동력이 되었습니다.다양한 아이디어의 교차 발전
머신러닝 분야로 전환한 소프트웨어 개발자들이, 자신들의 전문 지식과 열정을 Program Synthesis를 포함한 다양한 분야에 적용하기 좋은 환경이 되었습니다.
하나의 예시로, 2023년 MIT에서 ‘Introduction to Program Synthesis’라는 강좌를 개설했는데, 이 강좌를 ‘프로그래밍 언어, 형식 방법론, 그리고 AI가 만나는 새로운 분야’라고 소개하고 있습니다.
Francois Chollet의 비전: Program Synthesis은 ‘지능’으로 가는 핵심 요소
Francois는 오랫동안 Program Synthesis가 AGI를 달성하기 위한 중요한 단계이자 요소라고 주장해 왔는데요. Francois의 2020년 NeurIPS Talk에서도 딥러닝만의 접근법으로부터 오는 한계 - 거대한 데이터셋에 대한 의존성, 추론과 일반화의 어려움 - 때문에, AI가 추상적인 추론을 통해서 해결책을 생성할 수 있게 하려면 ‘Program Synthesis’가 핵심적인 요소가 될 수 있고, 딥러닝과 Program Synthesis를 결합하면 더 적응력있게, 새로운 문제에 잘 대응하는 확장 가능한 시스템을 만들 수 있다고 주장합니다.
Francois는 특히 그의 논문 ‘On the Measure of Intellgience’에서 ‘지능이라는 과정 (Process of Intelligence)’ - 해결책을 생성하는 체계로서의 과정이죠 - 과 특정 문제에 대한 해결책 그 자체인 ‘출력 (Output)’을 구분해야 한다고 강조했죠. 그러면서, Program Synthesis를 ‘AI가 특정한 작업에 특화된, 작은 프로그램을 만드는 방법’이고, 이게 바로 ‘지능을 평가하는 이상적인 방법’이라고 주장했습니다. 반복해서 말씀드리지만, 이런 접근방식이 기존의 ‘정적 (Static)’인 작업 수행 패러다임에서 ‘적응성 (Adaptability)’, 그리고 ‘추론 (Reasoning)’ 쪽으로 그 무게 중심을 옮기게 되는 관점의 전환을 만들어 냅니다.
딥러닝, Program Synthesis와 만나다
물론, Program Synthesis는 딥러닝의 대체재가 아닌 보완을 해 주는 도구입니다. 딥러닝 모델이 검색 공간 (Search Space)을 좁히고 대규모 패턴 인식을 처리하면서 Program Synthesis를 가이드하는 역할을 하고, Program Synthesis는 추론, 그리고 추상화 작업을 해 줍니다. 이런 하이브리드 접근 방식은 현재 AI가 다루지 못하는 - 또는 다루기 힘들어하는 - 문제들을 해결할 수 있는 방법을 만들어낼 수 있습니다.
서두에 말씀드린 대로, 이런 비전을 더 잘 추구하기 위해서 Francois Chollet와 Mike Knoop이 새로운 AI 연구소 Ndea를 설립한 겁니다. 바로 ‘추상화가 지능의 핵심’이라고 하는, Francois의 믿음에 뿌리를 둔 Ndea는, 유연한 추론과 일반화 (Generalization)를 잘 하기 위해서 기호 조작 (Symbolic Manipulation), 코드 생성 등을 활용해서 딥러닝만의 한계를 극복하는 적응형 AI 시스템을 개발하는 것을 그 목표로 하고 있습니다.
AGI라는 건 어떤 한 가지 방법이나 생각만으로 달성할 수 있는게 아닌 만큼, 앞으로 튜링 포스트 코리아에서는 Ndea의 움직임을 주시해 볼 생각입니다. Ndea의 새로운 소식과 결과물을 가지고 구독자 분과 공유할 날이 곧 오기를 바래 봅니다.
트위터 라이브러리 (Twitter Library) 🐦
복잡한 수학적 계산은 고도의 다단계 추론을 필요로 합니다. 따라서 ‘수학’이라는 영역 자체가 모델의 강력한 ‘사고’ 능력을 보여주기 위해서 아주 이상적인 분야가 됩니다. 또, AI 모델들은 대규모의 수학 문제를 해결하기 위해서 ‘Symbolic Solver’라든가 ‘연산 엔진’ 같은 외부 도구들을 통합해야 할 때도 있는데, 이 때도 마찬가지로 꽤 높은 수준의 수학적 추론 능력이 필요하겠죠.
여기에 최근 ‘수학적 추론’ 영역의 큰 발전과 관련된 10개의 논문을 모아 봤습니다:

*아직 튜링 포스트 코리아 구독 안 하셨나요? 구독해 주시면 매주 중요한 AI 뉴스를 정리한 다이제스트를 받으실 수 있습니다!
금주의 주목할 만한 업계 동향 📰
구글, AI 혁신을 리드하는 발표 지속
구글의 ‘Titans’ 아키텍처, AI에게 ‘기억’ 기능을 제공한다
구글 리서치가 다이나믹한 ‘장기 기억 (Long-term Memory)’을 가진 AI 모델이자 아키텍처, Titans를 공개했습니다. 입력값이 길더라도 이에 대해서 선형적 확장이 가능하다고 하는 이 아키텍처는, 트랜스포머가 가진 내재적인 제약 조건을 깨고 AI에게 마치 ‘사람과 같은 방식으로 작동하는 기억’ 기능을 제공한다고 하는데요. 이 아키텍처에 따라오는 연산 비용이나 메모리 병목현상에 대해서 걱정하는 의견도 있지만, 많은 연구자들이 벤치마크 결과를 기다리는 중입니다. 어쩌면 Titans가 ‘Attention’의 의미를 재정의하게 될지도 모르겠네요.구글 딥마인드, 계획 및 추론 작업을 혁신적으로 개선하는 ‘Mind Evolution’ 기법 개발
LLM이 더 계획과 추론 작업을 잘 응답할 수 있도록 하는 ‘Mind Evolution’ 기법에 관한 논문을 구글 딥마인드에서 공개했습니다. 이 기법은 ‘탐색’, 그리고 ‘유전 알고리즘’의 두 가지 요소를 기반으로 하는데, 여러 해결책을 탐색하기 위해 ‘아일랜드(Island)’라는 방식을 사용합니다. 각 단계에서 알고리즘이 해결책을 여러 그룹으로 나누고, 각 그룹에서 해결책을 발전시킨 다음, 가장 좋은 해결책을 다음 그룹으로 옮겨서 결합하고 새로운 해결책을 만들어내는 식으로, 전역적이고 전체적인 맥락을 반영하는 해결책을 ‘진화적’으로 만들어냅니다. 평가 함수의 적용에 있어서도 ‘자연어’를 기반으로 한다는 특징도 눈에 띄네요. 1-Pass, Best-of-N, Sequential Revisions+ 같은 기존 기법들과 비교해서 높은 성공률을 보이는 것으로 나타나고 있습니다.

Image Credit: 오리지널 논문
오픈AI, 역시 변화하는 환경에서도 주도권을 놓치지 않는다
“새로운 대통령 시대의 시작과 함께하겠다”는 의지를 보여주다
트럼프 대통령 취임식 며칠 전, 오픈AI는 마치 ‘선언문’과 같은 청사진을 공개하고, 민주주의를 보호하면서 AI 기반의 성장을 추진하기 위한 칩, 에너지, 인재에 대한 투자를 촉구했습니다. 아무래도 오픈AI의 영향력을 유지하기 위해서 새로운 대통령의 노선에 맞춰가려는 노력이겠죠.소프트뱅크, 오라클과 함께 데이터센터 합작회사 ‘스타게이트’ 설립 발표
오픈AI가 AI 개발에 최적화된 데이터센터 구축을 위한 합작사 '스타게이트'를 소프트뱅크, 오라클과 함께 설립하겠다고 발표했네요. 향후 4년간 총 5천억 달러 (약 700조원)를 투자해서, 미국 내 AI 인프라 확충 및 일자리 창출에 기여할 계획이라고 합니다. 소프트뱅크는 재정적인 관점에서, 오픈AI는 운영을 담당하는 역할로 알려져 있고 손정의 회장이 전체 의장이 될 거라고 합니다. 텍사스주에 첫 데이터센터 건설을 시작했고 이후 추가 건설이 이어질 예정인데, 초기 단계에만 약 1천억 달러가 투입됩니다. 아마 미국 정부와의 협업 영역이 있으리라 보이는데, 자세한 진척 상황과 그 의미는, 후속으로 팔로우업을 해 보아야 하겠습니다.웹브라우저 AI 에이전트, ‘오퍼레이터’ 프리뷰 공개
1월 23일, 오픈AI가 사용자를 대신해서 웹 브라우저를 제어하고 특정한 작업을 독립적으로 수행하는 GUI 에이전트, ‘오퍼레이터 (Operator)’를 프리뷰 공개했습니다. 월 200불의 ‘챗GPT 프로’ 요금제를 사용하는 미국 사용자에게 우선 공개되고, 이후 유료 요금제 챗GPT 플러스, 팀, 엔터프라이즈 등으로 확대된다고 합니다. 현재 온라인 쇼핑, 식사 배달, 레스토랑 예약, 여행 숙박 예약 등을 자동화하는데, 오퍼레이터 전용 웹브라우저, 에이전트 작업에 대한 설명 창을 통해서 작업을 진행하고, 오퍼레이터가 작업하는 동안에도 사용자가 화면 제어 가능합니다. 오퍼레이터는 GPT-4o와 비전과 추론 능력을 결합한 CUA (Computer Use Agent) 모델로 구동되는데, 개발자용 API가 없이도 다양한 서비스가 가능하다고 합니다. 단, 은행 거래와 같은 민감한 작업 등에는 사람이 개입하도록 한다고 하네요. 공식 유튜브는 많이들 보셨을 것 같고, 유튜버 JM님이 자그마치 약 32만원 (챗GPT 프로 요금 + VPN 요금)을 들여 테스트해 본 영상, 한 번 보시죠 ^.^
마이크로소프트, “우리도 있다는 걸 잊지 마”
MatterGen, 연구실을 위한 AI를 지속적으로 혁신한다
MatterGen은 처음부터 새로운 물질을 설계하는데 특화된 생성형 AI 모델입니다. 기존의 선별 과정을 건너뛰고, 자성이라든가 내구성 등의 특성을 가진 안정적인 화합물을 이미 만들어내고 있습니다. 배터리, 태양전지, 이산화탄소 포집 등 특히 지속 가능한 기술의 영역에서 MatterGen이 혁신의 열쇠가 될 수 있을 것으로 기대합니다.AutoGen 0.4 릴리즈, ‘더 똑똑한 에이전트의 시대를 위하여!’
기존 AutoGen 아키텍처를 재설계한 AutoGen v0.4를 공개했는데요. 이 새로운 버전은 AutoGen 라이브러리를 완전히 재설계해서 에이전트 워크플로우와 관련된 코드의 품질, 강건성 (Robustness), 사용성, 확장성 모두에 큰 개선을 이뤄내기 위한 목표로 만들어졌다고 합니다. 개발 도구와 1st Party 어플리케이션, 그리고 3rd Party 어플리케이션을 만들고 연동하기 쉬운 계층적 아키텍처로 구성되어 있습니다.

Image Credit: 마이크로소프트
‘AI 엔지니어링’ 부문 신설
전 메타의 핵심 인력이었던 Jay Parikh를 영입, 새로운 ‘AI 엔지니어링’ 부문을 이끌게 한다고 합니다. Parikh는 슈퍼컴퓨터와 플랫폼 확장 영역을 담당하게 되는데,, 이건 사티아 나델라의 미션인 ‘30년의 변화를 3년 안에 이루겠다’는 목표를 달성하기 위한 포석입니다.
계속해서 혁신을 추진해 나가는 스타트업들
Sakana AI, 재훈련 없이도 실시간으로 파인튜닝 가능한 새로운 트랜스포머 발표
2024년 일본에서 설립, 빠르게 유니콘으로 올라서서 큰 화제가 된 바 있는 Sakana AI에서 ‘새로운 Self-Adaptive AI 모델’인 ‘트랜스포머²(Transformer²)’ 논문을 발표했습니다. 이 모델은 수학, 코딩, 추론, 시각적 이해 등 다양한 작업에서 LoRA 등 여러 가지 PEFT 기법보다 더 작은 파라미터로도 높은 효율과 뛰어난 성능, 그리고 다양한 작업에 자연스럽게 적응하는 능력을 보여준다고 합니다.
저널리즘과 AI, 새로운 베프가 되나
Mistral AI는 AFP와 파트너십을 맺고 Mistral AI 챗봇을 통해 공급할 40년 이상의 기사 아카이브를 확보했고, 오픈AI도 이에 뒤질새라 Axios와 협업해서 지역 뉴스들이 미국의 도시들에 확산, 공급될 수 있도록 한다고 합니다. 또, 구글의 Gemini 앱에서는 AP 통신의 실시간 피드에 기반한 정보를 제공할 수 있도록 협의 중이라고 하네요. 얼마 전까지 뉴스 등을 비롯한 컨텐츠 제공자들과 거대 AI 서비스 공급자들 간의 힘겨루기가 결국은 양 당사자들간 협업을 통해 이슈를 해결하는 방향으로 가닥을 잡는 모양새입니다. 다만, 이 가운데 이런 파트너십에 끼기 어려운 수준의 규모인 컨텐츠 공급사들은 생존을 위한 또 다른 전략이 필요할 것 같습니다 - 어쩌면 AI의 발전이 의도치 않게 컨텐츠 산업의 구조 변화에도 영향을 주고 있는 것 같네요.
튜링 포스트 코리아팀이 읽고 있는 것들
작년 말 DeepSeek V3, 그리고 얼마 전 추론 능력에 집중한 모델 DeepSeek R1을 공개한 중국의 AI 스타트업 DeepSeek. 현 시점 그 어떤 회사보다도 화제가 되고 있는 - 여러 가지 이유로요 - AI 스타트업이라고 해도 과언이 아니겠죠? The Sequence에서 DeepSeek의 다양한 모델들과 그 히스토리, DeepSeek의 최신 모델들이 가지는 의미와 DeepSeek을 둘러싼 몇 가지 소란과 이슈에 대해서 커버학 있습니다.
튜링 포스트 코리아에서도 이전부터 DeepSeek을 주목하고 이 회사의 모델 개발 접근법에 대해 분석한 글이 있으니 관심있으신 분은 한 번 참고해 보시기 바라구요:

메타의 생성AI 조직에서도, 달랑 5.5M USD 정도의 트레이닝 예산으로 Llama 4의 성능을 빠르게 만들어낸 이 중국의 스타트업 때문에 내부적으로 난리 (?)가 났다는 이야기가 돌고 있는데요. 어느 정도 믿을만한 이야기인지는 모르지만, 어쨌든 전세계 개발자들의 주목과 관심을 받고 있는 건 틀림없는 듯 합니다.

새로 나온, 주목할 만한 연구 논문
금주의 Top Pick!
Transformer2: Self-Adaptive LLMs
AI의 성능을 실시간으로 높이기 위해 가중치를 정교하게 조정하고, 작업별 전문성을 갖춰 새로운 상황에도 잘 대응하는 모델, Transformer2를 소개합니다. 앞에서 말씀드린 Sakana AI의 논문입니다.Tensor Product Attention Is All You Need
어텐션 구조에서 텐서를 효율적으로 압축해서 메모리 사용량을 줄이고, 더 광범위한 맥락에서도 성능을 높일 수 있게끔 해 줍니다.MiniMax-01: Scaling Foundation Models with Lightning Attention
빠른 어텐션 기술과 전문가 시스템을 섞어서, 긴 문맥도 잘 처리하고 다양한 형태의 데이터도 함께 다룰 수 있게 되어서, 광범위한 작업에서 모델의 성능을 향상시켜 줍니다.
추론, 사고 및 지식의 확장
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
강화학습과 Test-time Scaling 같은 기술로 LLM의 구조적 문제 해결 능력을 향상시켜 줍니다.In-situ Graph Reasoning and Knowledge Expansion Using Graph-PReFLexOR
그래프 기반 추론과 기호 추상화 (Symbolic Abstraction)를 통합해서 적응력을 높이고 여러 분야의 문제를 더 잘 해결하게끔 해 줍니다.OmniThink: Expanding Knowledge Boundaries in Machine Writing Through Thinking
기계가 글을 쓸 때 사람의 사고 과정을 모방해서, 지식을 동적으로 찾고 확장하면서 풍부한 콘텐츠를 생성하게 해 줍니다.
파운데이션 모델의 확장성
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
비전 트랜스포머를 효율적으로 확장해서, 적은 연산 비용으로도 이미지와 영상 처리에서 최고 수준의 결과를 달성하게 해 줍니다.Inference-Time Scaling for Diffusion Models Beyond Scaling Denoising Steps
노이즈 선택을 최적화해서, 생성형 확산 모델의 이미지 품질과 다양성을 개선해 줍니다.
벤치마크와 평가
HALOGEN: Fantastic LLM Hallucinations and Where to Find Them
아주 디테일한 벤치마크로 LLM의 환각 현상 패턴을 분석하고 오류를 분류, 개선 전략을 수립하게 해 줍니다.PokerBench: Training Large Language Models to Become Professional Poker Players
LLM이 전략적 게임을 수행하는 능력을 평가해서, 불완전한 정보 상황에서의 복잡한 과제 처리 능력을 파악하게 해 줍니다.
트레이닝 및 해석 가능성의 개선
SPAM: Spike-Aware Adam With Momentum Reset for Stable LLM Training
스파이크를 고려한 최적화로 학습 안정성을 높이고 급격한 그래디언트 변화에 대응해서 효율성과 성능을 개선해 줍니다.Enhancing Automated Interpretability with Output-Centric Feature Descriptions
출력 기반의 특성 (Feature) 분석에 중점을 두어서 해석 가능성을 높이고, 활용도가 낮은 신경망의 특성 (Feature)을 되살리게 해 줍니다.
읽어주셔서 감사합니다. 프리미엄 구독자가 되어주시면 튜링 포스트 코리아의 제작에 큰 도움이 됩니다!