


TL;DR
중국 AI 스타트업 DeepSeek이 GPT-4를 넘어서는 오픈소스 AI 모델을 개발해 많은 관심을 받고 있습니다.
특히, DeepSeek만의 혁신적인 MoE 기법, 그리고 MLA (Multi-Head Latent Attention) 구조를 통해서 높은 성능과 효율을 동시에 잡아, 향후 주시할 만한 AI 모델 개발의 사례로 인식되고 있습니다.
특히 DeepSeek-Coder-V2 모델은 코딩 분야에서 최고의 성능과 비용 경쟁력으로 개발자들의 주목을 받고 있습니다.
글을 시작하며

Image Credit: DeepSeek 웹사이트
‘DeepSeek’은 오늘 이야기할 생성형 AI 모델 패밀리의 이름이자 이 모델을 만들고 있는 스타트업의 이름이기도 합니다. 이 회사의 소개를 보면, ‘Making AGI a Reality’, ‘Unravel the Mystery of AGI with Curiosity’, ‘Answer the Essential Question with Long-termism’과 같은 표현들이 있는데요. ‘장기적인 관점에서 현재의 생성형 AI 기술을 바탕으로 AGI로 가는 길을 찾아보겠다’는 꿈이 엿보이는 듯합니다.
Moonshot AI 같은 중국의 생성형 AI 유니콘을 이전에 튜링 포스트 코리아에서도 소개한 적이 있는데요.

역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다.
DeepSeek의 오픈소스 모델 DeepSeek-V2, 그리고 DeepSeek-Coder-V2 모델은 독자적인 ‘어텐션 메커니즘’과 ‘MoE 기법’을 개발, 활용해서 LLM의 성능을 효율적으로 향상시킨 결과물로 평가받고 있고, 특히 DeepSeek-Coder-V2는 현재 기준 가장 강력한 오픈소스 코딩 모델 중 하나로 알려져 있습니다. 또 한 가지 주목할 점은, DeepSeek의 소형 모델이 수많은 대형 언어모델보다 상당히 좋은 성능을 보여준다는 점입니다.
DeepSeek 모델 패밀리는, 특히 오픈소스 기반의 LLM 분야의 관점에서 흥미로운 사례라고 할 수 있습니다. AI 커뮤니티의 관심은 - 어찌보면 당연하게도 - Llama나 Mistral 같은 모델에 집중될 수 밖에 없지만, DeepSeek이라는 스타트업 자체, 이 회사의 연구 방향과 출시하는 모델의 흐름은 한 번 살펴볼 만한 중요한 대상이라고 생각합니다.
AI 학계와 업계를 선도하는 미국의 그늘에 가려 아주 큰 관심을 받지는 못하고 있는 것으로 보이지만, 분명한 것은 생성형 AI의 혁신에 중국도 강력한 연구와 스타트업 생태계를 바탕으로 그 역할을 계속해서 확대하고 있고, 특히 중국의 연구자, 개발자, 그리고 스타트업들은 ‘나름의’ 어려운 환경에도 불구하고, ‘모방하는 중국’이라는 통념에 도전하고 있다는 겁니다. 시장의 규모, 경제적/산업적 환경, 정치적 안정성 측면에서 우리나라와는 많은 차이가 있기는 하지만, 과연 우리나라의 생성형 AI 생태계가 어떤 도전을 해야 할지에 대한 하나의 시금석이 될 수도 있다고 생각합니다.
다시 DeepSeek 이야기로 돌아와서, DeepSeek 모델은 그 성능도 우수하지만 ‘가격도 상당히 저렴’한 편인, 꼭 한 번 살펴봐야 할 모델 중의 하나인데요. DeepSeek 모델 패밀리의 면면을 한 번 살펴볼까요?
이 글은 아래 목차로 구성되어 있습니다:
‘벤치마크 경쟁’으로 출발하다
DeepSeek 모델은 처음 2023년 하반기에 출시된 후에 빠르게 AI 커뮤니티의 많은 관심을 받으면서 유명세를 탄 편이라고 할 수 있는데요. 처음에는 Llama 2를 기반으로 다양한 벤치마크에서 주요 모델들을 고르게 앞서나가겠다는 목표로 모델을 개발, 개선하기 시작했습니다. 이렇게 한 번 고르게 높은 성능을 보이는 모델로 기반을 만들어놓은 후, 아주 빠르게 새로운 모델, 개선된 버전을 내놓기 시작했습니다. 허깅페이스 기준으로 지금까지 DeepSeek이 출시한 모델이 48개인데, 2023년 DeepSeek과 비슷한 시기에 설립된 미스트랄AI가 총 15개의 모델을 내놓았고, 2019년에 설립된 독일의 알레프 알파가 6개 모델을 내놓았거든요. 물론 허깅페이스에 올라와 있는 모델의 수가 전체적인 회사의 역량이나 모델의 수준에 대한 직접적인 지표가 될 수는 없겠지만, DeepSeek이라는 회사가 ‘무엇을 해야 하는가에 대한 어느 정도 명확한 그림을 가지고 빠르게 실험을 반복해 가면서 모델을 출시’하는구나 짐작할 수는 있습니다.
2023년 11월 2일부터 DeepSeek의 연이은 모델 출시가 시작되는데, 그 첫 타자는 DeepSeek Coder였습니다. DeepSeek Coder는 Llama 2의 아키텍처를 기본으로 하지만, 트레이닝 데이터 준비, 파라미터 설정을 포함해서 처음부터 별도로 구축한 모델로, ‘완전한 오픈소스’로서 모든 방식의 상업적 이용까지 가능한 모델입니다.
바로 직후인 2023년 11월 29일, DeepSeek LLM 모델을 발표했는데, 이 모델을 ‘차세대의 오픈소스 LLM’이라고 불렀습니다.
당시에 출시되었던 모든 다른 LLM과 동등하거나 앞선 성능을 보여주겠다는 목표로 만든 모델인만큼 ‘고르게 좋은’ 성능을 보여주었습니다. (아래의 스파이더차트는 DeepSeek LLM 67B Base 모델의 점수를 상대적인 100점으로 놓고 Llama 2 70B Base 모델의 성능을 표시한 것이니, DeepSeek LLM의 모델이 ‘고르게 만점에 가깝다’는 오해는 없으시기 바랍니다 ^.^)

Image Credit: Ollama Web Site
이렇게 ‘준수한’ 성능을 보여주기는 했지만, 다른 모델들과 마찬가지로 ‘연산의 효율성 (Computational Efficiency)’이라든가’ 확장성 (Scalability)’라는 측면에서는 여전히 문제가 있었죠. 그래서, DeepSeek 팀은 이런 근본적인 문제들을 해결하기 위한 자기들만의 접근법, 전략을 개발하면서 혁신을 한층 가속화하기 시작합니다.
새로운 도전: ‘높은 벤치마크 점수’가 아니라 ‘진짜 난제를 해결’하자
불과 두 달 만에, DeepSeek는 뭔가 새롭고 흥미로운 것을 들고 나오게 됩니다: 바로 2024년 1월, 고도화된 MoE (Mixture-of-Experts) 아키텍처를 앞세운 DeepSeekMoE와, 새로운 버전의 코딩 모델인 DeepSeek-Coder-v1.5 등 더욱 발전되었을 뿐 아니라 매우 효율적인 모델을 개발, 공개한 겁니다. 더 적은 수의 활성화된 파라미터를 가지고도 DeepSeekMoE는 Llama 2 7B와 비슷한 성능을 달성할 수 있었습니다.
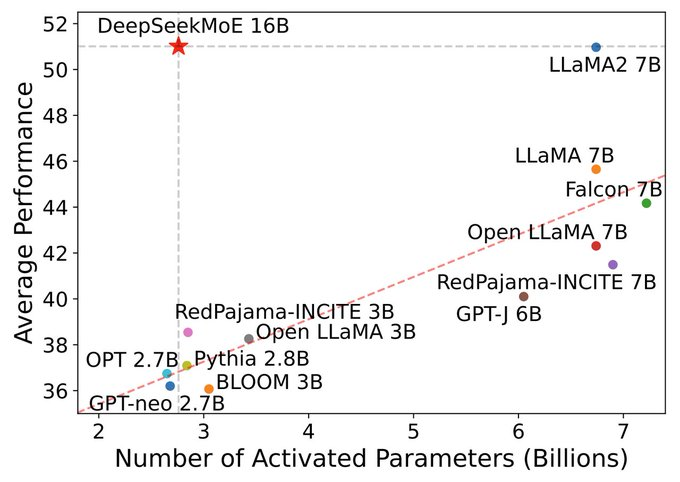
Image Credit: DeepSeek AI 트위터
바로 이어서 2024년 2월, 파라미터 7B개의 전문화 모델, DeepSeekMath를 출시했습니다. 이 소형 모델은 GPT-4의 수학적 추론 능력에 근접하는 성능을 보여줬을 뿐 아니라 또 다른, 우리에게도 널리 알려진 중국의 모델, Qwen-72B보다도 뛰어난 성능을 보여주었습니다.
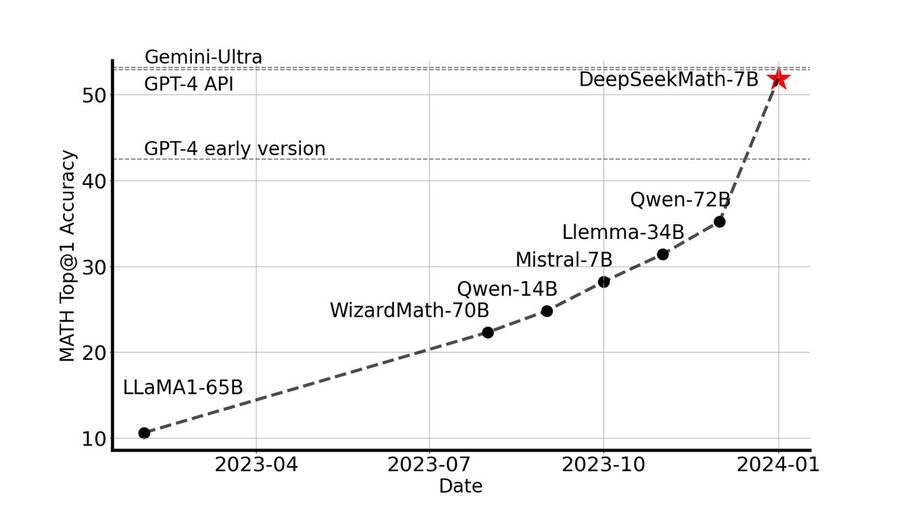
Image Credit: DeepSeekMath 논문
그리고 2024년 3월 말, DeepSeek는 비전 모델에 도전해서 고품질의 비전-언어 이해를 하는 모델 DeepSeek-VL을 출시했습니다. 대부분의 오픈소스 비전-언어 모델이 ‘Instruction Tuning’에 집중하는 것과 달리, 시각-언어데이터를 활용해서 Pretraining (사전 훈련)에 더 많은 자원을 투입하고, 고해상도/저해상도 이미지를 처리하는 두 개의 비전 인코더를 사용하는 하이브리드 비전 인코더 (Hybrid Vision Encoder) 구조를 도입해서 성능과 효율성의 차별화를 꾀했습니다. 그 결과, DeepSeek는 정해진 토큰 예산 안에서 고해상도 이미지 (1024X1024)를 효율적으로 처리하면서도 계산의 오버헤드를 낮게 유지할 수 있다는 걸 보여줬습니다 - 바로 DeepSeek가 해결하고자 했던, 계산 효율성 (Computational Efficiency) 문제를 성공적으로 극복했다는 의미죠.
그 이후 2024년 5월부터는 DeepSeek-V2와 DeepSeek-Coder-V2 모델의 개발, 성공적인 출시가 이어집니다. 두 모델 모두 DeepSeekMoE에서 시도했던, DeepSeek만의 업그레이드된 MoE 방식을 기반으로 구축되었는데요. 특히 DeepSeek-V2는 더 적은 메모리를 사용하면서도 더 빠르게 정보를 처리하는 또 하나의 혁신적 기법, MLA (Multi-Head Latent Attention)을 도입했습니다.
DeepSeek-Coder-V2는 코딩과 수학 분야에서 GPT4-Turbo를 능가하는 최초의 오픈 소스 AI 모델로, 가장 좋은 평가를 받고 있는 새로운 모델 중 하나입니다. 이전의 버전 1.5와 비교해서 버전 2는 338개의 프로그래밍 언어와 128K의 컨텍스트 길이를 지원합니다.

Image Credit: DeekSeek 깃헙. 오픈소스 모델로는 최초로 GPT-4-Turbo 모델을 수학, 코딩 등에서 능가하는 성능을 보여줌
자, 그리고 2024년 8월, 바로 며칠 전 가장 따끈따끈한 신상 모델이 출시되었는데요. 바로 DeepSeek-Prover-V1.5의 최적화 버전입니다. 이게 무슨 모델인지 아주 간단히 이야기한다면, 우선 ‘Lean’이라는 ‘ 기능적 (Functional) 프로그래밍 언어’이자 ‘증명 보조기 (Theorem Prover)’가 있습니다. 마이크로소프트 리서치에서 개발한 것인데, 주로 수학 이론을 형식화하는데 많이 쓰인다고 합니다. 이 Lean 4 환경에서 각종 정리의 증명을 하는데 사용할 수 있는 최신 오픈소스 모델이 DeepSeek-Prover-V1.5입니다.
DeepSeek-Prover-V1.5는 이전 버전에서 세 가지 테크닉:
SFT (Supervised Fine-Tuning; 지도학습 미세조정)
RLPAF (RL from Proof Assistant Feedback; 증명 보조기를 통한 강화학습)
RMaxTS (몬테카를로 트리 서치의 변형)
을 조합해서 개선함으로써 수학 관련 벤치마크에서의 성능을 상당히 개선했습니다 - 고등학교 수준의 miniF2F 테스트에서 63.5%, 학부 수준의 ProofNet 테스트에서 25.3%의 합격률을 나타내고 있습니다.

Image Credit: DeepSeek-Prover-V1.5 논문
자, 이렇게 창업한지 겨우 반년 남짓한 기간동안 스타트업 DeepSeek가 숨가쁘게 달려온 모델 개발, 출시, 개선의 역사(?)를 흝어봤는데요. 거의 한 달에 한 번 꼴로 새로운 모델 아니면 메이저 업그레이드를 출시한 셈이니, 정말 놀라운 속도라고 할 수 있습니다. 이제 이 최신 모델들의 기반이 된 혁신적인 아키텍처를 한 번 살펴볼까요?
다 같은 MoE가 아니다: DeepSeek의 ‘MoE’ 접근법
DeepSeekMoE 아키텍처는 DeepSeek의 가장 강력한 모델이라고 할 수 있는 DeepSeek V2와 DeepSeek-Coder-V2을 구현하는데 기초가 되는 아키텍처입니다. 과연 DeepSeekMoE는 거대언어모델의 어떤 문제, 어떤 한계를 해결하도록 설계된 걸까요?
먼저 기본적인 MoE (Mixture of Experts) 아키텍처를 생각해 보죠.

기존의 MoE 아키텍처는 게이팅 메커니즘 (Sparse Gating)을 사용해서 각각의 입력에 가장 관련성이 높은 전문가 모델을 선택하는 방식으로 여러 전문가 모델 간에 작업을 분할합니다. 이렇게 하면, 모델이 데이터의 다양한 측면을 좀 더 효과적으로 처리할 수 있어서, 대규모 작업의 효율성, 확장성이 개선되죠. 하지만 각 전문가가 ‘고유한 자신만의 영역’에 효과적으로 집중할 수 있도록 하는데는 난점이 있다는 문제 역시 있습니다.
DeepSeekMoE는 LLM이 복잡한 작업을 더 잘 처리할 수 있도록 위와 같은 문제를 개선하는 방향으로 설계된 MoE의 고도화된 버전이라고 할 수 있습니다. 이 아키텍처에는 두 가지 기법이 채택되는데요:
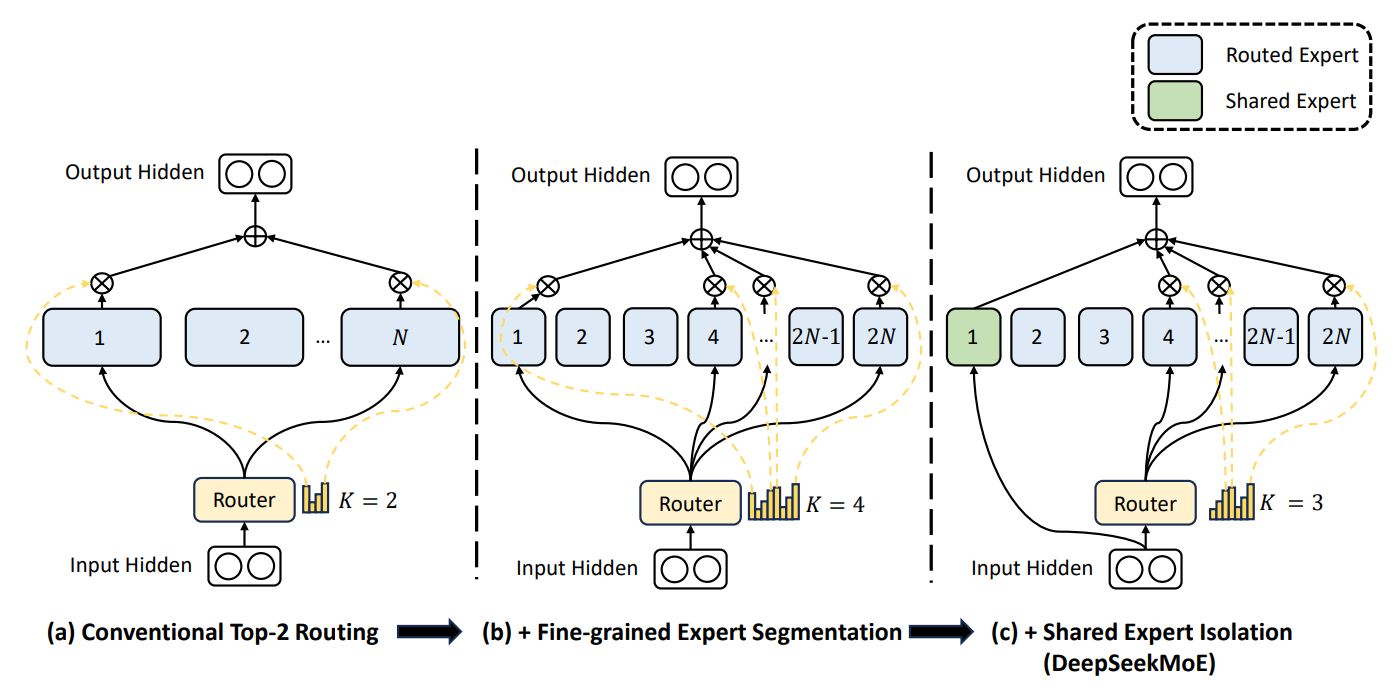
Image Credit: DeepSeekMoE 논문
더 세분화된 (Fine-grained) 전문가 모델 분류
DeepSeekMoE는 각 전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화합니다. MoE에서 ‘라우터’는 특정한 정보, 작업을 처리할 전문가(들)를 결정하는 메커니즘인데, 가장 적합한 전문가에게 데이터를 전달해서 각 작업이 모델의 가장 적합한 부분에 의해서 처리되도록 하는 것이죠.공유 전문가 (Shared Expert)의 분리
‘공유 전문가’는 위에 설명한 라우터의 결정에 상관없이 ‘항상 활성화’되는 특정한 전문가를 말하는데요, 여러 가지의 작업에 필요할 수 있는 ‘공통 지식’을 처리합니다. 공유 전문가가 있다면, 모델이 구조 상의 중복성을 줄일 수 있고 동일한 정보를 여러 곳에 저장할 필요가 없어지게 되죠. 따라서 각각의 전문가가 자기만의 고유하고 전문화된 영역에 집중할 수 있습니다.
이런 두 가지의 기법을 기반으로, DeepSeekMoE는 모델의 효율성을 한층 개선, 특히 대규모의 데이터셋을 처리할 때 다른 MoE 모델보다도 더 좋은 성능을 달성할 수 있습니다.
DeepSeek-V2: DeepSeek의 혁신적 기법의 집합체
DeepSeek-V2는 위에서 설명한 혁신적인 MoE 기법과 더불어 DeepSeek 연구진이 고안한 MLA (Multi-Head Latent Attention)라는 구조를 결합한 트랜스포머 아키텍처를 사용하는 최첨단 언어 모델입니다.

Image Credit: DeepSeek-V2 논문
위 그림의 세 부분이 아래와 같이 구성되어 작동합니다:
트랜스포머 아키텍처
텍스트를 단어나 형태소 등의 ‘토큰’으로 분리해서 처리한 후 수많은 계층의 계산을 해서 이 토큰들 간의 관계를 이해하는 ‘트랜스포머 아키텍처’가 DeepSeek-V2의 핵심으로 근간에 자리하고 있습니다.
Mixture-of-Experts (MoE)
모든 태스크를 대상으로 전체 2,360억개의 파라미터를 다 사용하는 대신에, DeepSeek-V2는 작업에 따라서 일부 (210억 개)의 파라미터만 활성화해서 사용합니다. 이렇게 하면 불필요한 계산에 자원을 낭비하지 않으니 효율이 높아지죠. DeepSeek-V2의 MoE는 위에서 살펴본 DeepSeekMoE와 같이 작동합니다.
MLA (Multi-Head Latent Attention)
트랜스포머에서는 ‘어텐션 메커니즘’을 사용해서 모델이 입력 텍스트에서 가장 ‘유의미한’ - 관련성이 높은 - 부분에 집중할 수 있게 하죠. 조금만 더 이야기해 보면, 어텐션의 기본 아이디어가 ‘디코더가 출력 단어를 예측하는 각 시점마다 인코더에서의 전체 입력을 다시 한 번 참고하는 건데, 이 때 모든 입력 단어를 동일한 비중으로 고려하지 않고 해당 시점에서 예측해야 할 단어와 관련있는 입력 단어 부분에 더 집중하겠다’는 겁니다. 이렇게 하는 과정에서, 모든 시점의 은닉 상태들과 그것들의 계산값을 ‘KV 캐시 (Key-Value Cache)’라는 이름으로 저장하게 되는데, 이게 아주 메모리가 많이 필요하고 느린 작업이예요. DeepSeek-V2에서 도입한 MLA라는 구조는 이 어텐션 메커니즘을 변형해서 KV 캐시를 아주 작게 압축할 수 있게 한 거고, 그 결과 모델이 정확성을 유지하면서도 정보를 훨씬 빠르게, 더 적은 메모리를 가지고 처리할 수 있게 되는 거죠.
DeepSeek 연구진이 고안한 이런 독자적이고 혁신적인 접근법들을 결합해서, DeepSeek-V2가 다른 오픈소스 모델들을 앞서는 높은 성능과 효율성을 달성할 수 있게 되었습니다. 자, 이제 DeepSeek-V2의 장점, 그리고 남아있는 한계들을 알아보죠.
DeepSeek-V2의 장점, 그리고 한계
위에 설명한 내용에서 짐작하시겠지만, DeepSeek-V2는 아래와 같은 많은 장점들을 가지고 있습니다:
MoE를 활용해서 연산의 부담이 줄어들고 효율이 높아집니다
MLA를 활용해서 추론 (Inference) 속도가 아주 빨라집니다
트레이닝 비용이 줄어듭니다: DeepSeek-V2는 DeepSeek 67B와 비교해서 트레이닝 비용이 약 42.5% 절감됩니다
높은 처리량 (Throughput)을 보여줍니다: DeepSeek-V2는 DeepSeek 67B 대비 5.76배 높은 처리량을 자랑하고, 표준 하드웨어에서 초당 50,000개 이상의 토큰을 생성할 수 있습니다
128,000 토큰에 달하는 아주 긴 텍스트를 효율적으로 처리합니다
영어, 중국어를 다 잘 하고, 코딩과 수학적 추론에서 특히 높은 성능을 보여줍니다
물론, 세상 만물이 그렇듯이 완벽한 건 없죠 ^.^ 모델이 꽤 복잡한 만큼, 아래와 같은 한계점도 여전히 가지고 있습니다:
MLA에서 데이터를 압축하는 과정에서 정보가 손실될 위험이 있습니다
대규모의 데이터셋으로 트레이닝하는데 상당한 수준의 컴퓨팅 자원이 필요합니다
인터넷의 방대한 데이터를 가지고 학습하는데서 오는 편향 위험이 있습니다
자, 이제 이 글에서 다룰 마지막 모델, DeepSeek-Coder-V2를 살펴볼까요?
DeepSeek-Coder-V2: 높은 효율성의 코딩 모델
위에서 ‘DeepSeek-Coder-V2가 코딩과 수학 분야에서 GPT4-Turbo를 능가한 최초의 오픈소스 모델’이라고 말씀드렸는데요. 이 DeepSeek-Coder-V2 모델에는 어떤 비밀이 숨어있길래 GPT4-Turbo 뿐 아니라 Claude-3-Opus, Gemini-1.5-Pro, Llama-3-70B 등 널리 알려진 모델들까지도 앞서는 성능과 효율성을 달성할 수 있었을까요?
이전 버전인 DeepSeek-Coder의 메이저 업그레이드 버전이라고 할 수 있는 DeepSeek-Coder-V2는 이전 버전 대비 더 광범위한 트레이닝 데이터를 사용해서 훈련했고, ‘Fill-In-The-Middle’이라든가 ‘강화학습’ 같은 기법을 결합해서 사이즈는 크지만 높은 효율을 보여주고, 컨텍스트도 더 잘 다루는 모델입니다. 다른 모델들 대비 비용도 2~5% 수준입니다. DeepSeek-Coder-V2의 특징을 하나씩 살펴보죠:
트레이닝 데이터
DeepSeek-Coder-V2는 이전 버전 모델에 비교해서 6조 개의 토큰을 추가해서 트레이닝 데이터를 대폭 확충, 총 10조 2천억 개의 토큰으로 학습했습니다. 소스 코드 60%, 수학 코퍼스 (말뭉치) 10%, 자연어 30%의 비중으로 학습했는데, 약 1조 2천억 개의 코드 토큰은 깃허브와 CommonCrawl로부터 수집했다고 합니다. DeepSeek-Coder-V2의 파이프라인은 DeepSeekMath와 동일합니다.
확장된 프로그래밍 언어 지원
DeepSeek-Coder-V2는 총 338개의 프로그래밍 언어를 지원합니다.
모델 사이즈와 아키텍처
DeepSeek-Coder-V2 모델은 16B 파라미터의 소형 모델, 236B 파라미터의 대형 모델의 두 가지가 있습니다. 236B 모델은 210억 개의 활성 파라미터를 포함하는 DeepSeek의 MoE 기법을 활용해서, 큰 사이즈에도 불구하고 모델이 빠르고 효율적입니다.
Long-Context 처리
DeepSeek-Coder-V2는 컨텍스트 길이를 16,000개에서 128,000개로 확장, 훨씬 더 크고 복잡한 프로젝트도 작업할 수 있습니다 - 즉, 더 광범위한 코드 베이스를 더 잘 이해하고 관리할 수 있습니다.
Fill-In-The-Middle (FIM)
DeepSeek-Coder-V2 모델의 특별한 기능 중 하나가 바로 ‘코드의 누락된 부분을 채워준다’는 건데요. 예를 들어 중간에 누락된 코드가 있는 경우, 이 모델은 주변의 코드를 기반으로 어떤 내용이 빈 곳에 들어가야 하는지 예측할 수 있습니다.
강화학습 (Reinforcement Learning)
DeepSeek-Coder-V2 모델은 컴파일러와 테스트 케이스의 피드백을 활용하는 GRPO (Group Relative Policy Optimization), 코더를 파인튜닝하는 학습된 리워드 모델 등을 포함해서 ‘정교한 강화학습’ 기법을 활용합니다. 이런 방식으로 코딩 작업에 있어서 개발자가 선호하는 방식에 더 정교하게 맞추어 작업할 수 있습니다.
DeepSeek-Coder-V2 모델은 수학과 코딩 작업에서 대부분의 모델을 능가하는 성능을 보여주는데, Qwen이나 Moonshot 같은 중국계 모델들도 크게 앞섭니다.
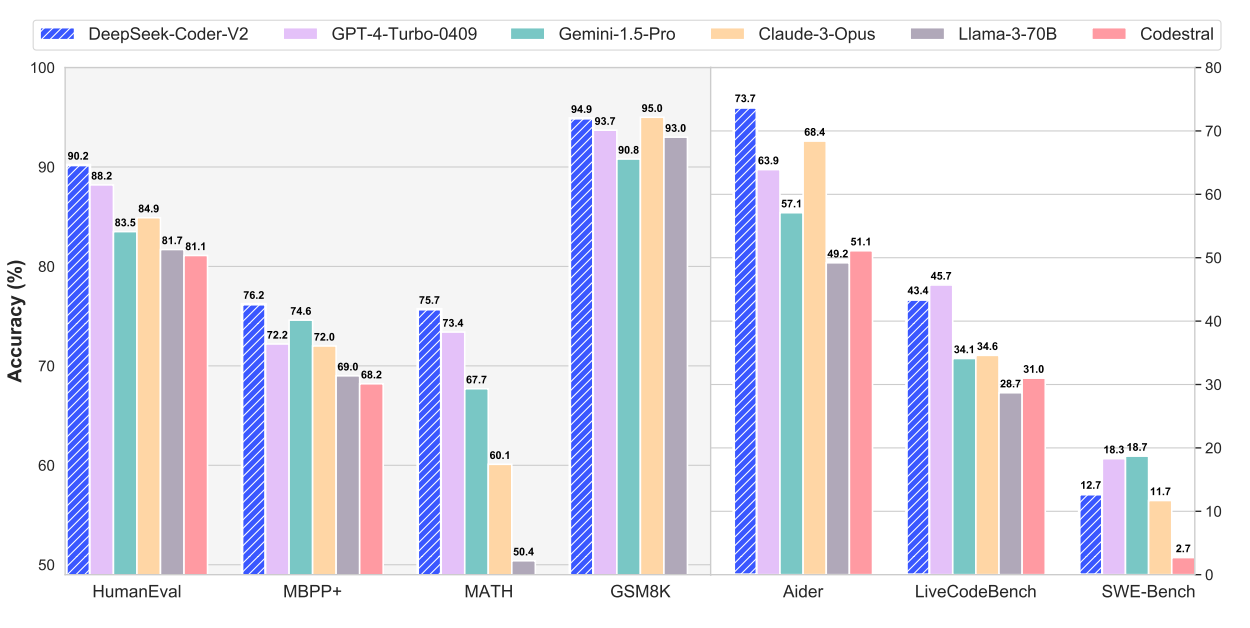
수학과 코딩 벤치마크에서 DeepSeek-Coder-V2의 성능. Image Credit: Original 논문
‘코드 편집’ 능력에서는 DeepSeek-Coder-V2 0724 모델이 최신의 GPT-4o 모델과 동등하고 Claude-3.5-Sonnet의 77.4%에만 살짝 뒤지는 72.9%를 기록했습니다. 대단하죠?
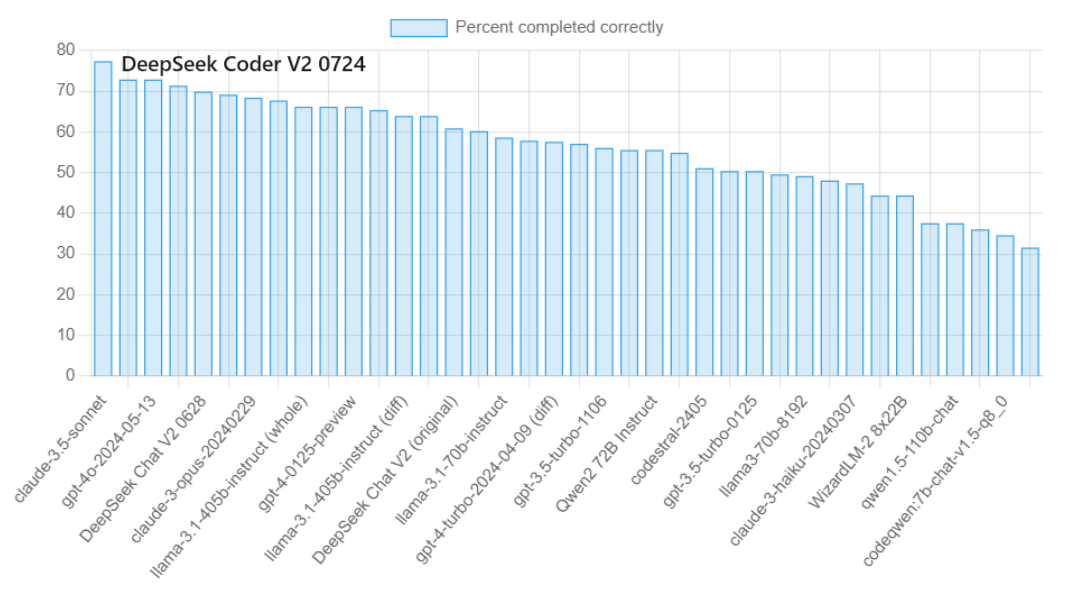
코드 편집 성능 비교. Claude-3.5-sonnet 다음이 DeepSeek Coder V2. Image Credit: Aider Leaderboard
비용 경쟁력은?
DeepSeek-Coder-V2 모델을 기준으로 볼 때, Artificial Analysis의 분석에 따르면 이 모델은 최상급의 품질 대비 비용 경쟁력을 보여줍니다. 다른 오픈소스 모델은 압도하는 품질 대비 비용 경쟁력이라고 봐야 할 거 같고, 빅테크와 거대 스타트업들에 밀리지 않습니다.

Image Credit: Artificial Analysis
다만, DeepSeek-Coder-V2 모델이 Latency라든가 Speed 관점에서는 다른 모델 대비 열위로 나타나고 있어서, 해당하는 유즈케이스의 특성을 고려해서 그에 부합하는 모델을 골라야 합니다. 어쨌든 범용의 코딩 프로젝트에 활용하기에 최적의 모델 후보 중 하나임에는 분명해 보입니다. 자세한 분석 내용은 Artificial Analysis를 한 번 참조해 보시기 바랍니다.
맺으며
자, 지금까지 고도화된 오픈소스 생성형 AI 모델을 만들어가는 DeepSeek의 접근 방법과 그 대표적인 모델들을 살펴봤는데요.
처음에는 경쟁 모델보다 우수한 벤치마크 기록을 달성하려는 목적에서 출발, 다른 기업과 비슷하게 다소 평범한(?) 모델을 만들었는데요. 하지만 곧 ‘벤치마크’가 목적이 아니라 ‘근본적인 도전 과제’를 해결하겠다는 방향으로 전환했고, 이 결정이 결실을 맺어 현재 DeepSeek LLM, DeepSeekMoE, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, DeepSeek-Prover-V1.5 등 다양한 용도에 활용할 수 있는 최고 수준의 모델들을 빠르게 연이어 출시했습니다.
특히, DeepSeek만의 독자적인 MoE 아키텍처, 그리고 어텐션 메커니즘의 변형 MLA (Multi-Head Latent Attention)를 고안해서 LLM을 더 다양하게, 비용 효율적인 구조로 만들어서 좋은 성능을 보여주도록 만든 점이 아주 흥미로웠습니다.
현재 출시한 모델들 중 가장 인기있다고 할 수 있는 DeepSeek-Coder-V2는 코딩 작업에서 최고 수준의 성능과 비용 경쟁력을 보여주고 있고, Ollama와 함께 실행할 수 있어서 인디 개발자나 엔지니어들에게 아주 매력적인 옵션입니다.
글을 시작하면서 말씀드린 것처럼, DeepSeek이라는 스타트업 자체, 이 회사의 연구 방향과 출시하는 모델의 흐름은 계속해서 주시할 만한 대상이라고 생각합니다. 우리나라의 LLM 스타트업들도, 알게 모르게 그저 받아들이고만 있는 통념이 있다면 그에 도전하면서, 독특한 고유의 기술을 계속해서 쌓고 글로벌 AI 생태계에 크게 기여할 수 있는 기업들이 더 많이 등장하기를 기대합니다.
보너스: 각종 자료 소스
DeepSeek 웹사이트: https://www.deepseek.com/
DeepSeek LLM Scaling Open-Source Language Models with Longtermism https://arxiv.org/pdf/2401.02954
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models https://arxiv.org/pdf/2401.06066
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model https://arxiv.org/pdf/2405.04434
DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence https://arxiv.org/pdf/2401.14196
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence https://arxiv.org/pdf/2406.11931
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models https://arxiv.org/abs/2402.03300
DeepSeek-VL: Towards Real-World Vision-Language Understanding https://arxiv.org/pdf/2403.05525
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data https://arxiv.org/pdf/2405.14333
DeepSeek-V2-Chat Performance Analysis by Artificial Analysis https://artificialanalysis.ai/models/deepseek-v2
DeepSeek-Coder-V2 Performance Analysis by Artificial Analylsis https://artificialanalysis.ai/models/deepseek-coder-v2
*읽어주셔서 감사합니다. 주위 분들께도 튜링 포스트 코리아 뉴스레터 구독 추천 부탁드립니다!