


글을 시작하며
아무래도, 올 초 ‘DeekSeek’ 사태 이후 모두가 DeepSeek, 그리고 DeepSeek-R1 모델의 마일스톤에 큰 관심을 가지게 되었죠. 그 동안, DeepSeek처럼 중국의 모델(?)이지만 알리바바로부터 나온 Qwen 모델들은 아주 흥미로운 오픈소스 모델임에도 불구하고 상대적으로 좀 덜 주목받고 있는 것 같습니다.
Qwen - 즉 알리바바 - 은, 처음부터 ‘도구 사용 (Tool Use)’ 같이 ‘에이전트 기능’을 갖춘 고도화된 모델을 만드는데 집중해 왔고, 이들의 이전 모델들도 이런 기능을 열심히 활용했습니다.
오늘은, Qwen 모델이 오픈AI라든가 DeepSeek의 최첨단 모델들과 비슷하거나 더 우수한, 강력한 추론 능력을 갖게 된, 그 시작부터 지금까지의 여정에 대해서 한 번 알아보려고 합니다. 그리고 - AI와 ML 커뮤니티 뿐 아니라 시장 전체가 AI 생태계와 에이전트에 큰 관심을 두고 있는 만큼 - Qwen-Agent 프레임웍에 대해서도 알아보겠습니다. Qwen-Agent 프레임웍은 Qwen 모델이 즉각적으로 활용하도록 만들어진, 자율적인 계획 수립, 함수 호출, 복잡한 멀티 스텝의 작업을 실행하게끔 하는 완전한 에이전트 프레임웍입니다.
자, 그럼 여러분의 충분한 관심을 받을만한 Qwen 모델 패밀리와 에이전트 프레임웍, 한 번 알아볼까요?
오늘 에피소드에서는 다음과 같은 내용을 다룹니다:
이 모든 것의 시작: Qwen 1.0과 Qwen 2
본격적으로 이야기를 하기 전에, ‘알리바바’라는 회사 - 그룹이죠 - 의 규모를 이해하기 위해서 잠깐 알아볼께요.
1999년에 중국 항저우에서 마윈이 설립한 알리바바 그룹은 전자상거래와 기술 분야에서 글로벌 리더가 되었는데요. 2024년 4분기에 2,802억 위안 (미화 383.8억 달러)의 매출을 기록했는데, 이건 1년 만에 8% 성장한 수치입니다. 2025년 3월 기준 회사의 시가총액은 미화 약 3,286.3억 달러로, 세계에서 가장 높은 가치를 인정받는 기업 중 하나이기도 합니다.

중국 저장성 항저우시에 있는 알리바바그룹 항저우 시시 캠퍼스 전경. 중국 내 알리바바 캠퍼스 중 최대 규모로, 4만 명이 근무하고 로봇 경찰이 순찰을 한다고 합니다. Image Credit: 알리익스프레스
알리바바는 AI 기반의 혁신을 위해서 자사의 다양한 사업 전반에 걸쳐 엄청난 투자와 AI 기술 기반의 통합을 하고 있는데요. 향후 3년 동안 AI와 클라우드 컴퓨팅 인프라에 3,800억 위안 (미화 약 530억 달러) 이상을 투자하겠다고 발표했습니다 - 이건 지난 10년간 AI와 클라우드 분야에 사용한 금액 전체를 넘어서는 수준입니다.
바로 알리바바의 AI 투자계획, 여기서, Qwen 모델이 중요한 역할을 하게 됩니다.
Qwen 모델 개발 초기에서부터, 알리바바가 Qwen 모델을 중심으로 도구 사용, 심층 추론을 포함한 강력한 에이전트 생태계를 만들고자 했다는 걸 알 수 있는데요. 한 번 타임라인을 중심으로 알리바바 클라우드가 만들어 온 주요 모델과 에이전트 생태계의 변화를 살펴보도록 하죠.
2023년 중반
2023년 중반, 알리바바 클라우드의 Qwen 팀은 Qwen 1.0이라 불리는 LLM(Large Language Model) 제품군을 처음으로 오픈소스화했습니다. 여기에는 1.8B, 7B, 14B, 72B 파라미터를 가진 기본 LLM이 포함되었고, 중국어와 영어를 주로 중점적으로 다룬, 최대 3조 개의 다국어 데이터 토큰으로 사전 훈련을 했습니다. Qwen 1.0 모델은 최대 32K 토큰의 컨텍스트 윈도우를 제공했고, 일부 초기 변형 모델은 8K를 제공했습니다.
베이스 모델과 함께, 알리바바는 SFT (지도학습 파인튜닝)와 RLHF (Reinforcement Learning from Human Feedback)를 통해 정렬한 (Aligned) Qwen-Chat 모델을 출시했습니다. 초기 단계이긴 하지만, 이 변형 모델도 이미 폭넓은 스킬셋을 보여줬는데요 - 대화를 나누고, 컨텐츠를 생성하고, 번역하고, 코딩하고, 수학 문제를 풀고, 게다가 적절하게 프롬프팅을 하게 되면 도구를 사용하거나 에이전트로서 작동을 하도록 할 수도 있었습니다. 첫 번째 모델부터, Qwen 팀은 에이전트로서의 활용을 염두에 두고 효과적으로 도구를 사용할 수 있는 모델을 설계한 겁니다.
2024년 2월
2024년 2월, Qwen 팀은 Qwen-1.5라는 이름의 업그레이드 버전을 발표했습니다. 이번에는 모델의 사이즈에 상관없이 동일한 32K 컨텍스트 길이를 지원하고, 모델의 라인업을 확장해서 0.5B, 4B, 32B, 110B 파라미터를 가진 모델까지 만들었습니다. 다국어를 이해한다든가, Long Context 추론이라든가 하는 일반적인 스킬셋 뿐 아니라, 에이전트 기능도 향상시켜서, 도구 사용 (Tool Use) 벤치마크에서 GPT-4 모델의 수준에 도달하기도 했습니다 - 이 때 테스트를 한 결과에 따르면, 대부분 95% 이상의 정확도로 필요한 도구를 올바르게 선택하고 사용하는 모습을 볼 수 있었습니다.
2024년 6월
2024년 6월에는 Qwen 2가 출시되었는데, 이전 모델의 ‘트랜스포머 기반 아키텍처’를 계승하면서도, Qwen-1.5 대비해서 더 추론 (Inference) 속도도 빠르고, 메모리도 더 적게 사용하도록 한다는 목표를 가지고 모든 사이즈의 모델에 GQA(Grouped Query Attention) 기법을 적용했습니다.

2024년 8월
같은 해 8월, Qwen2-Math, Qwen2-Audio (오디오 입력을 이해하고 요약하는 Audio-Text 모델), Qwen2-VL이 등장했습니다.
Qwen2-VL은 알리바바의 AI 모델 개발 역사에서 중요한 이정표라고 할 수 있습니다.
DeepSeek이 자사 모델 기능을 최적화하기 위해서 자기만의 기법을 만들어서 적용하는 것과 마찬가지로, Qwen 팀도 자체 모델을 개선하기 위해서 자기만의 고유한 기술을 개발합니다. Qwen2-VL의 경우에는, 그 예시로 Native Dynamic Resolution과 같은 혁신적인 기법을 도입했는데, 이 기법은 해상도와 상관없이 모든 이미지를 잘 처리하면서 다이나믹하게 가변 숫자의 시각적 토큰으로 변환할 수 있게 해 줍니다.

Qwen2-VL 아키텍처. Image Credit: 오리지널 논문
‘Native Dynamic Resolution’에 대해 간단히만 짚고 넘어가겠습니다.
이 기법은 전통적으로 이미지를 처리할 때 사용하는 ‘고정 해상도’ 개념에서 벗어나서, 다양한 크기와 비율의 이미지를 원본 해상도 그대로 처리할 수 있게 해 줍니다. 이미지를 정규화하지 않기 때문에 공간의 관계를 왜곡하지 않고 원본 차원을 그대로 사용, 경계 상자도 정확히 잡고 표현도 정확한 위치에 할 수 있게 해 줍니다. 문서, 차트, 다이어그램 등 복잡한 시각 자료를 모델이 더 잘 이해할 수 있도록 하는 기반이 되기도 하구요.
Qwen2.5-VL에서는 이 기법을 더 발전시켜서, ‘시간적 차원’까지 확장을 해서, 다이나믹한 FPS (Frames Per Second) 훈련, 절대 시간 인코딩 등을 도입해서 모델이 시간의 흐름을 직접 학습할 수 있게 했고, Window Attention을 통해서 원본 해상도를 유지하면서도 계산 부하를 효과적으로 줄였습니다.
이 기법은, Qwen 모델이 다양한 해상도의 이미지, 비디오를 효과적으로 처리하게 하는 핵심 기술로, 문서 이해, 객체 위치 파악, 비디오 분석 작업에서 뛰어난 성능을 보이게 하는 기초가 됩니다.
그리고, 다양한 모달리티 - 텍스트, 이미지, 비디오 - 에 걸쳐서 위치 정보를 더 잘 정렬하기 위해서 MRoPE (Multimodal Rotary Position Embedding) 기법을 사용했습니다.
결과적으로, Qwen2-VL은 20분 이상의 비디오를 잘 처리할 수 있고, 휴대폰, 로봇 같은 기기에 통합할 수 있습니다.
DeepSeek-R1과 경쟁한다 - Qwen2.5, QwQ-32B
바야흐로 2024년 9월, DeepSeek 같은 새로운 경쟁자들이 엄청난 기세로 치고 올라오던 시점에, 알리바바는 Qwen2.5를 출시했습니다. 5억에서 720억 개의 파라미터까지 포함하는 모델 다수가 포함되어 있는데, 최대 18조 토큰에 달하는 대규모의 데이터셋으로 사전 훈련을 했고, 언어, 오디오, 비전, 코딩 및 수학 분야의 응용 프로그램을 다룹니다. 이 모델들은 29개 이상의 언어를 지원하고, 128K 토큰에 달하는 초장문의 컨텍스트를 처리할 수 있고, 최대 8K 토큰 길이의 출력을 생성할 수 있습니다.
하지만 이 컨텍스트 길이가 Qwen2.5의 한계점은 아닙니다 – 2025년 1월에 출시된 Qwen2.5-1M 모델은 최대 100만 토큰의 아주 긴 컨텍스트를 처리할 수 있는데, 그럼에도 불구하고 속도는 3~7배 향상되었습니다.
2.5 버전 모델들 중에 가장 인상적인 건 2025년 1월에 출시된 Qwen2.5-VL입니다.
이 Qwen2.5-VL 모델은, 디지털 환경에서 ’비쥬얼 에이전트’ 역할을 할 수 있는 모델입니다 – 단순히 이미지를 설명하거나 하는 것이 아니라, 이미지 등의 시각 자료와 ‘상호작용’할 수 있습니다. Qwen2.5-VL은 시각적 입력을 기반으로 ‘추론하고 도구를 다이나믹하게 사용’할 수 있도록 설계되었습니다. 그리고, 이전 모델과 같이 (이미지를 위한) Native Dynamic Resolution, (비디오를 위한) Dynamic Frame Rate Training과 Absolute Time Encoding 기법을 활용해서, 다양한 크기의 이미지, 그리고 최대 몇 시간까지 이르는 긴 비디오를 처리할 수 있습니다. 긴 비디오를 효과적으로 처리하기 위해서 Qwen2-VL MRoPE의 시간적 구성 요소를 절대적 시간과 정렬하는 방식으로 개선했다고 합니다.
더욱 흥미로운 것은, Qwen2.5-VL이 컴퓨터나 휴대폰 같은 장치를 제어할 수 있다는 겁니다. 바로 이 멀티모달 모델이 오픈AI의 Operator와 유사하게 작동한다는 뜻이죠. 이 모델로 항공편 예약, 날씨 정보 검색, 이미지 편집, 소프트웨어 확장 프로그램 설치 등 에이전트 시스템이 일반적으로 수행하는 작업들을 할 수 있습니다.

Qwen2.5-VL의 성능을 보여주는 예시를 몇 개 가져와 봤습니다:

향상된 객체 인식 능력. Image Credit: 파이토치 KUG

다중 객체 인식 능력. Image Credit: 파이토치 KUG

시각적으로 표현된 정보를 논리적으로 해석하고 이를 바탕으로 답을 생성. Image Credit: 파이토치 KUG

라이브 채팅 기능. 개인 비서로서의 가능성. Image Credit: 파이토치 KUG
Qwen2.5의 출시 시점이 지난 1월 26일 - 중국의 음력 설 연휴였습니다 - 이었고, 바로 그 일주일 전 (1월 20일)에는 AI 커뮤니티를 충격에 빠뜨린 DeepSeek-R1 모델의 공개되었죠. Qwen2.5 모델 출시도, 이런 DeepSeek 같은 강력한 경쟁자가 급속하게 부상하는 상황에 대한 대응책 일환으로 보였습니다.
동시에, Qwen 팀은 더 복잡한 모델인 Qwen2.5-Max, 거대 전문가 혼합(Mixture-of-Experts, MoE) 모델도 개발했습니다. 이 모델들은 20조 개 이상의 토큰으로 훈련했고, 지도학습 파인튜닝 (Supervised Fine-Tuning, SFT)과 RLHF (Reinforcement Learning from Human Feedback)기법으로 추가적인 개선을 했습니다. 이를 계기로, Qwen 모델이 DeepSeek-V3, Llama3.1-405B, GPT-4o 및 Claude3.5-Sonnet 같은 최상위 수준의 거대 모델들과 경쟁하고 심지어 능가할 수도 있다는 것을 보여주게 되었죠.
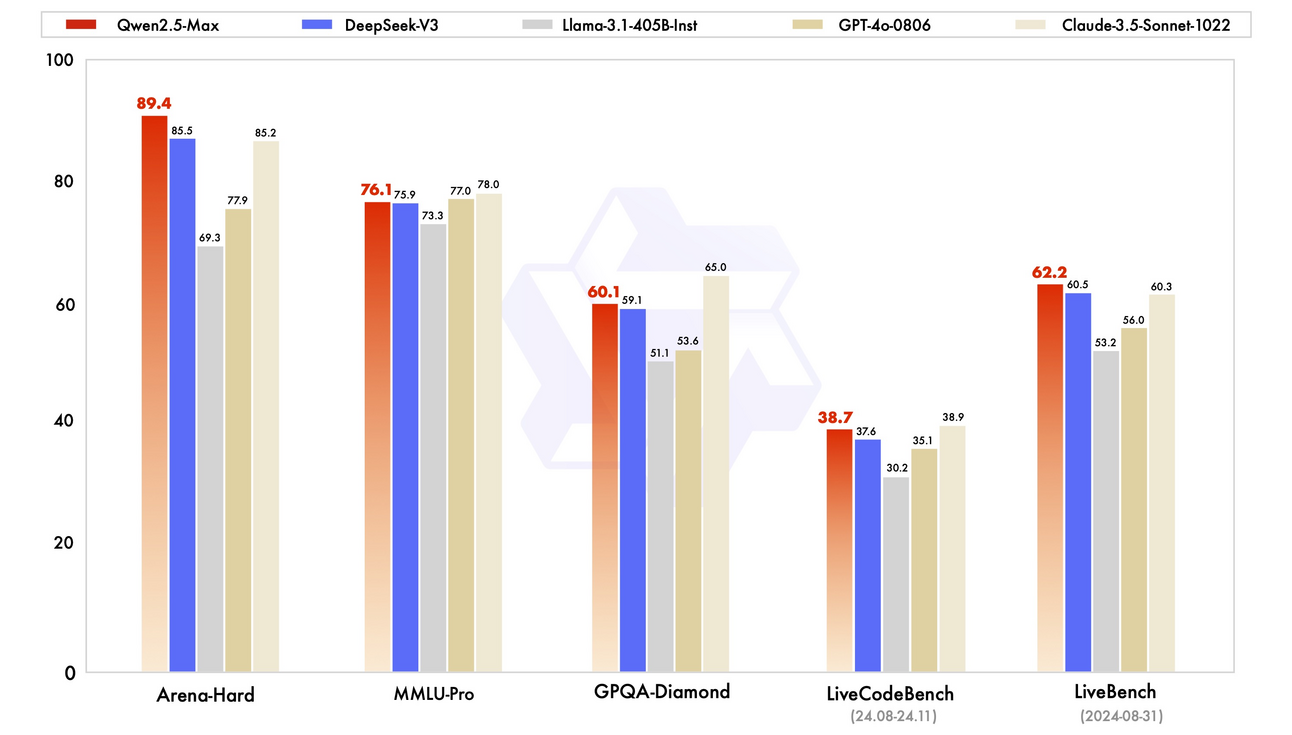
Image Credit: Qwen2.5-Max 블로그
누가 뭐래도 알리바바의 2025년 주력 AI 모델, Qwen2.5 패밀리는 심화된 지식을 보유하고, 도구를 사용할 수도 있고, 여러 다양한 도메인의 전문성을 보유한, 확장된 컨텍스트를 처리할 수 있도록 만들어진 AI 모델입니다. 그리고 ‘에이전트’ 기능에 초점을 맞춰서, 누구나 Qwen 백본을 사용해서 AI 에이전트 시스템을 구축할 수 있도록 하는 기반을 마련했습니다.
주력 모델 Qwen2.5 외에도, 2025년 발표한 모델들 중에 주목할 만한 게 또 하나 있습니다 - 바로 QwQ-32B 추론 모델입니다. 이 모델은 2024년 11월에 실험적 미리보기 (Experimental Preview) 모델로 처음 공개되었지만, 최근인 2025년 3월 초에 본격적으로 그 능력을 인정받고 있는데요.
QwQ-32B 모델 역시, 강화학습 (RL; Reinforcement Learning)에 대한 ‘집착’에 가까운 노력의 결과물이라고 할 수 있을 것 같습니다 - 강화학습을 효과적으로 스케일링해서, 소형 모델을 더 큰 모델에 필적하게 유능하게 만들었으니까요: QwQ의 파라미터는 320억개에 불과하지만, 훨씬 더 큰 DeepSeek-R1 (파라미터 6,710억 개, 370억 활성화)에 견줄 만한 성능을 보여줍니다. 물론 더 작은 o1-mini보다도 뛰어난 성능을 보여주고요. 이렇게 QwQ가 보여주는 ‘인상적인 추론 능력’, 바로 도구를 사용하고 과제에 다이나믹하게 적응할 수 있는 AI 에이전트의 새로운 세계를 엿볼 수 있게 해 줍니다.
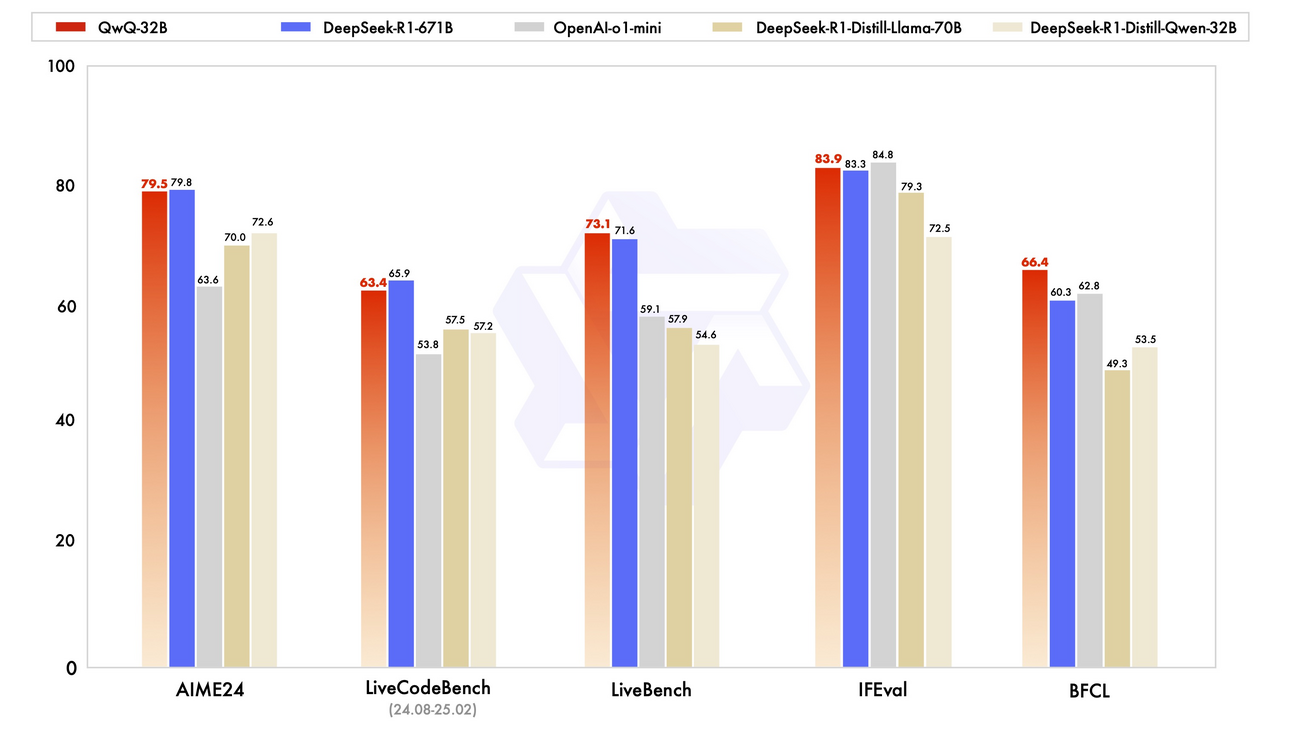
Image Credit: QwQ-32B 블로그
자, 그렇습니다. 여기까지 Qwen 팀이 2023년부터 진행해 온 모델 개발사의 간략한 요약이었구요. 다음에는 Qwen 모델을 활용해서 AI 에이전트와 앱을 구축할 수 있게 해 주는, 바로 Qwen-Agent 프레임웍에 대해 알아보려고 합니다. 지금 AI 개발 커뮤니티가 ‘에이전트 개발을 위한 생태계’에 엄청난 관심을 보여주고 있는 만큼, 이 Qwen-Agent 프레임웍의 중요성은 더 커지고 있다고 생각합니다.
Qwen-Agent 프레임웍은 무엇인가?
Qwen-Agent 프레임웍은, Qwen 모델을 활용한 애플리케이션 개발을 지원하기 위해 만들어진 프레임웍으로, Qwen모델이 실제 환경에서 에이전트로 작동할 수 있도록 도와줍니다.

이 프레임웍은 Qwen 모델이 가지고 있는 지시 수행 (Instruction Following), 도구 통합 (Tool Integration), 다단계의 계획 수립, 장기 메모리 처리 등의 강점을 바탕으로 하면서, 함수 호출 기능을 내장해서 지원하는 거대 언어 모델 (LLM)과 외부의 다양한 도구를 결합해서 ‘에이전트’로 만들기 쉽게 ‘모듈식’ 접근 방법으로 구성되어 있습니다.
Qwen-Agent 프레임웍의 중요한 특징들을 좀 살펴보죠:
도구 통합 (Tool Integration) 및 함수 호출 (Function Calling)
이 Qwen-Agent 프레임웍은 쉽게 Qwen 모델이 호출할 수 있는 도구 (함수, API)를 정의할 수 있게 해 줍니다. 오픈AI의 함수 호출 스펙과 유사한 ‘함수 호출용’ JSON 형식 구문을 처리해서, 모델이 호출을 출력하고 도구로부터 결과를 받을 수 있게 합니다. Qwen-Agent는 웹 브라우징, 코드 실행, 데이터베이스 쿼리 등을 위해서 미리 만들어진 도구 플러그인과 함께 제공됩니다.
계획 (Planning)과 메모리 (Memory)
Qwen-Agent 에이전트 프레임웍은 모델에 ‘작업 메모리’, 그리고 ‘플래너’를 더해서 다단계의 작업을 자율적으로 처리하도록 합니다. 사용자가 작업 완료에 필요한 각 단계를 일일이 지시할 필요없이 내부적으로 행동을 계획, 실행할 수 있는 것이죠.
예를 들어, 복잡한 검색이 필요한 쿼리가 있다면, 모델이 웹을 검색하고, 결과를 요약하고, 답변을 작성한다는 계획을 세우는 겁니다. Qwen-Agent는 이전 단계의 기억을 유지하도록 되어 있어서, 모델이 어떤 도구가 어떤 결과를 반환했는지 기억하고, 그 정보를 다음 단계 프롬프트에 전달해 줍니다.
그렇다면, 실제로 Qwen-Agent로 할 수 있는 건 어떤 것들이 있을까요?
Qwen-Agent 응용 예시
자, 그럼 Qwen-Agent로 구축할 수 있는 어플리케이션 사례를 살펴봅시다.
코드 인터프리터 기반의 데이터 분석, 시각화
Qwen-Agent는 모델이 데이터 분석, 계산 및 시각화 작업을 하기 위해서 Python 코드를 실행하는 내장 코드 인터프리터를 갖고 있습니다. 마치 오픈AI의 코드 인터프리터와 비슷한 샌드박스 같은 코드 실행 기능이죠. 사용자가 파일을 업로드하든지 데이터를 코드 인터프리터에 주면, Qwen은 이걸 분석하거나 그래프를 생성하기 위해서 Python 코드를 만들고 실행합니다.
브라우저 어시스턴트 (BrowserQwen 크롬 확장 프로그램)
브라우저 어시스턴트는 Qwen 모델을 사용해서 사용자 브라우저에서 웹, 문서를 탐색하고, 실시간의 정보로 쿼리에 답변하도록 해 주는 도구입니다. BrowerQwen이라는 크롬 확장 프로그램으로 제공되는데, 지금 있는 웹페이지나 PDF에 대해서 이야기를 나누거나 질문 답변을 할 수 있습니다.
BrowserQwen은 ‘플러그인 통합’ 기능도 지원해서, 예를 들어서, 앞에서 언급한 코드 인터프리터 도구를 활용해서 브라우저에서 바로 수학 문제를 해결한다든가, 데이터를 시각화한다든가 할 수 있습니다.

Image Credit: Qwen-Agent 깃헙 문서
그런데, 만약 엄청나게 긴 문서 - 1백만 토큰 정도 된다고 치죠 - 를 가지고 Q&A를 해야 한다고 하면 어떻게 될까요? 이런 경우에도 Qwen-Agent가 도움이 될 수 있습니다.
‘검색 (Retrieval)’으로 1백만 토큰으로 맥락 확장
Qwen-Agent은, ‘검색’을 활용해서 컨텍스트 길이를 실질적으로 확장하는 접근법을 택하고 있습니다. Qwen-Agent의 연구자들은, 표준의 8k 컨텍스트 채팅 모델에서 시작해서, 세 가지 단계를 통해서 ‘전체 책’ 정도에 해당하는 대량의 정보를 읽고 처리하는 작업을 하기 위해서 1백만개 토큰 정도의 문서까지도 처리할 수 있게 만들었습니다:
아주 긴 컨텍스트를 처리할 수 있는 강력한 에이전트를 구축합니다.
이 에이전트를 사용해서 고품질의 훈련 데이터를 생성합니다.
합성 데이터로 모델을 파인튜닝해서 강력한 장문 Long-Context AI를 만듭니다.
위에서 이야기한 세 가지 레벨을 아래에 설명해 보겠습니다:

레벨 1 이미지.
Image Credit: ‘Generalizing an LLM from 8k to 1M Context using Qwen-Agent’ 블로그
레벨 1: RAG (Retrieval-Augmented Generation)
긴 문서를 더 작은 청크로 나눕니다(예: 512 토큰을 기준으로 청킹).
키워드 기반 검색으로 가장 관련성이 높은 (Relevant) 부분을 찾습니다.
효율성을 위해 복잡한 임베딩 모델 대신 전통적인 BM25 검색을 사용합니다.
레벨 2: 청크별로 개별적으로 읽기
단순히 키워드 오버랩에만 의존하지 않고, 각각의 청크를 개별적으로 스캔합니다.
청크가 관련이 있는 걸로 판단된다면, 핵심적인 문장을 추출하고 다시 가다듬어서 검색을 합니다 - 이렇게 해서, 중요한 세부 사항을 잡아내지 못하는 걸 방지합니다.
레벨 3: 단계별로 추론 (Reading)
복잡한 질문에 답을 해야 하기 때문에, 다단계의 프로세스를 적용합니다.
쿼리를 더 작은 하위 쿼리로 나누고 단계별로 답변하는 작업을 반복합니다. 예를 들어, "베토벤의 5번 교향곡과 같은 세기에 발명된 차량은 무엇인가요?"라는 질문에 답하기 위해서, 시스템은 먼저 그 교향곡이 19세기에 작곡되었다는 사실을 찾고, 그 다음 그 시대에 발명된 차량을 검색하는 식입니다.

레벨 2, 레벨 3 이미지.
Image Credit: ‘Generalizing an LLM from 8k to 1M Context using Qwen-Agent’ 블로그
이렇게 해서 Qwen-Agent가 8k 컨텍스트에서 1백만 토큰까지 확장해서 지원할 수 있는 에이전트 프레임웍이 되었고, 이 과정은 LLM을 에이전트 오케스트레이터와 결합, 도구를 지원하는 방식을 기본 모델의 한계를 극복하는 방법을 보여줍니다.
맺으며: 왜 Qwen 모델 패밀리에 주목해야 하는가
Qwen 모델은 다국어 성능, 오픈소스로서의 접근성, 기업 환경에 적용할 만한 부분과 도구 사용 지원, 계획 수립 능력, 함수 호출 지원 같은 ‘에이전트 기능’에 중점을 둔 개발 전략으로 만들어졌습니다. 그래서 DeepSeek-R1이라든가 오픈AI의 모델 같은 경쟁 모델들과 대등한 비교를 할 수 있는, 그리고 두각을 나타내는 모델입니다.
아직 진짜 제대로 자율적인 AI 에이전트를 만들기까지는 시간이 좀 걸릴 것으로 보이지만, 지금도 Qwen-Agent 프레임웍 같은 도구들로 PDF를 읽고 내용을 상호작용하면서 이해하거나, 도구를 원활하게 사용한다거나, 맞춤형의 기능을 수행하도록 하는 등 꽤 복잡한 작업을 하는 에이전트를 만들 수 있습니다.
주목해야 할 것은, ‘접근성’과 ‘좋은 성능’ 간의 균형을 잘 맞춘 Qwen 모델에 대해 연구자들의 관심이 점점 커지고 있다는 겁니다. 과연 Qwen의 다음 모습은 어떤 거일까요? 현재의 트렌드에 맞추어, 느린 사고방식, 즉 추론 (Reasoning)에 초점을 맞추게 될까요, 아니면 AGI로 가는 자신만의 길을 찾아 가게 될까요?
보너스: 참고자료
Qwen 모델:
더 읽어볼 만한 추가 자료:
Qwen Technical Report by Jinze Bai et al.
Qwen2 Technical Report by An Yang et al.
Qwen2-Audio Technical Report by Junyang Lin, Yunfei Chu et al.
Qwen2.5 Technical Report by Binyuan Hui et al.
Qwen2.5-VL Technical Report by Keqin Chen et al.
Qwen2.5-1M Technical Report by Dayiheng Liu et al.
BrowserQwen on GitHub
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!