


글을 시작하며
며칠 전에 튜링 포스트 코리아의 ‘AI 에이전트’ 섹션에서 ‘에이전틱 AI와 물리적 AI를 망라해서 달성하려고 하는, 젠슨 황의 비전’에 대해서 간략히 이야기를 했는데요.
물리적 AI (Physical AI)의 핵심은, 센서 기반의 에이전트, 로봇 공학, 물리적인 시뮬레이션 플랫폼 등의 첨단 기술을 활용해서, ‘물리적인 세계를 이해하고 상호작용할 수 있는 시스템’에 있다고 할 수 있습니다. 아직은 한창 발전하는 단계이지만, 에이전트와 로봇 공학에 대해 폭발적으로 증가하는 관심, 그 자체가 이 비전을 향해 세상이 조금씩, 그러나 의미있는 걸음을 내딛고 있다는 뜻이겠죠.
이 한 걸음 한 걸음이 제대로 된 진전을 만들어낼 것이냐를 좌우하는 중요한 요소 중에 하나가 바로, WFM (World Foundation Model; 월드 파운데이션 모델)입니다. WFM은 실제의 환경을 시뮬레이션하고 텍스트, 이미지, 비디오 입력 등으로부터 그 결과를 예측하도록 훈련된 AI 시스템입니다. WFM이 있어야 물리적 특성을 인식하고 합치시키는 비디오를 만들고, AI가 물리적인 세계를 더 잘 이해하고 상호작용을 할 수 있겠죠?
지난 1월 9일, 엔비디아가 이와 관련해서 ‘단순한 모델 하나가 아닌 전체 생태계’를 공개했고, 이걸 Cosmos (코스모스)라고 이름지었습니다.

CES 2025에서 젠슨 황의 Cosmos 발표. Image Credit: CES
세 개의 WFM을 포함한 이 새로운 플랫폼은 오픈소스로 공개되기도 했는데요 - 좀 더 정확히는, 엔비디아 오픈모델 라이센스 하에 사용 가능한 거기는 합니다.
꼭 로봇을 만드는 경우가 아니라도, 엔비디아의 Cosmos 같은 물리적 AI를 형성하는 기술을 이해하는 건 중요하다고 생각해요. 이런 혁신적인 기술이 결국 AI 시스템이 학습하고, 상호작용하고, 실제 세계의 문제를 해결하는 방식을 재정의하고 있기 때문이죠. 더 스마트한 자동화에서부터 차세대 시뮬레이션까지, 그 파급 효과는 AI의 전 영역에 영향을 미치게 될 겁니다.
자, 그럼 Cosmos의 구성요소를 한 번 살펴보고, Cosmos가 AI 연구와 산업 전반, 특히 물리적 AI 영역에 가져올 임팩트를 한 번 생각해 보시죠. (오늘의 글은 조금 길고 살짝 기술적인 내용들이 있지만, 분명히 가치가 있는 내용이라고 생각하구요, 가급적 쉽게 풀었습니다. 그리고 모든 내용을 다 이해하지 않으셔도 좋으니 한 번 전체를 조망하실 수 있다면 좋겠습니다.)
오늘 에피소드에서는 아래와 같은 내용을 다룹니다:
‘물리적 AI’란 무엇인가, 빠르게 되짚어 봅시다
Cosmos WFM 플랫폼을 이해하기 위해서, 우선 기본 개념부터 살짝 되짚어 볼까요? ’물리적 AI’는, 환경을 감지하는 센서, 그리고 환경과 상호작용하고 환경을 변화시키는 액추에이터를 갖춘 AI 시스템을 말합니다. ‘Embodied AI’ 에이전트라든가 아니면 로봇, 이런 것들이 바로 ‘사람에게 위험하거나, 힘들거나, 반복적인’ 작업을 처리하게끔 설계된 이 분야의 대표적인 예시라고 할 수 있죠.
지금까지 AI의 많은 영역에서 엄청나게 빨리 발전이 이어져 왔지만, 상대적으로 ‘물리적 AI’ 영역은 뒤처져 있다고 할까요? 물리적인 현실의 복잡성을 숙지하고 이해하는 건, AI에게 여전히 특별한 도전 과제로 남아있고, 이 과제를 극복하려면 방대한 센서 데이터를 처리할 수 있을 뿐만 아니라 다이나믹한 환경에서 지능적인 결정을 내릴 수 있는 시스템이 필요합니다.
결국, ‘물리적 AI’를 달성하기 위해서 반드시 필요한 단계는, 바로 ‘Embodied AI’를 구동하는 데 필요한 ‘인지 및 의사결정 능력’을 갖춘 자율 시스템인 에이전트 AI의 개발입니다. 이러한 기술은 ‘인식’과 ‘행동’ 사이의 갭을 채우면서 물리적인 세계와 시스템이 더 정교하게 상호작용할 있도록 하는 매개체입니다.
이 과정에서 한 가지 큰 장애물이 바로 ‘물리적 AI를 위한 학습 데이터를 수집’하는 건데요. 실제 세계에서 이런저런 실험을 한다고 하면 비용도 비용이거니와 위험할 때도 많고, 상세한 관찰로 행동의 순서를 정리해야 하니 시간도 오래 걸릴 겁니다. 이런 학습 데이터를 만들고 수집하는데 있어서의 어려움을 바로 WFM이 해결해 줍니다.
WFM (월드 파운데이션 모델)
WFM (월드 파운데이션 모델)은, 물리적 AI가 ‘안전하게 학습하고 연습할 수 있는, 물리적 세계의 디지털 복제본’이라고 설명하면 되지 않을까 합니다.
구글 딥마인드의 Genie 2, 또 페이페이 리 교수가 공동 창업한 월드 랩스 (World Labs)가 만들고 있는 AI 시스템 - 이전에 소라 (Sora)가 공개되었을 때 FOD에서 간단히 소개한 적이 있죠 - 같은 일부 WFM들은 주로 이미지, 텍스트로 작동하죠. 즉, 단일 이미지나 텍스트 프롬프트로부터 3D 환경을 생성할 수 있다는 얘깁니다. 이 모델 안에서, 환경과 객체들이 상호작용할 수 있고, 심지어는 물리적인 효과도 추가할 수가 있습니다.
반면에, Cosmos WFM은 AI 시스템을 시뮬레이션하고 훈련하기 위해서 비디오를 다루는, 시각적인 WFM (Visual WFM)에 집중하는 모델인데요.
Cosmos WFM에 대해서 더 깊은 이야기를 하기 전에, 그럼 WFM은 일반적으로 어떻게 작동할까요?
WFM은 기본적으로 그 ‘세계’에서 ‘다음에 일어날 일을 예측’합니다 - 과거의 관찰 (Past Observation; Cosmos WFM의 경우, 비디오가 되겠죠) xo:t, 그리고 Perturbation이라고 부르는 변화나 행동 ct를 가지고 미래의 관찰 (Future Observation) xt+1을 예측한다고 표현할 수 있습니다. 예를 들어서, 모델에 공이 굴러가는 영상 (과거의 관찰)을 보여주고 누군가가 공을 밀 거라고 말하면 (Perturbation), 모델은 공이 다음에 어떻게 움직일지 예측합니다.

Image Credit: 오리지널 논문
일반적으로 이야기하는 WFM의 필요성은 다음과 같습니다:
트레이닝에 필요한 시간과 자원을 절약해 줍니다.
AI 시스템이 다양한 상황에서 행동하는 방식을 학습할 수 있는, 안전하고 효율적인 훈련 환경을 제공합니다.
AI 시스템이 광범위한 행동을 훈련할 수 있도록 현실적인 합성 데이터를 생성합니다.
자, 그럼 Cosmos WFM 플랫폼으로 돌아가서 그 특징과 기능을 살펴볼까요?
Cosmos WFM 플랫폼은 어떻게 작동하나?
아래는 엔비디아에서 제공하는, Cosmos 플랫폼의 구성에 대한 개념도인데요. 물리적 AI를 위한 WFM을 만들고, 훈련하고, 사용하는데 필요한 도구들, 모델들이 다 포함되어 있습니다.
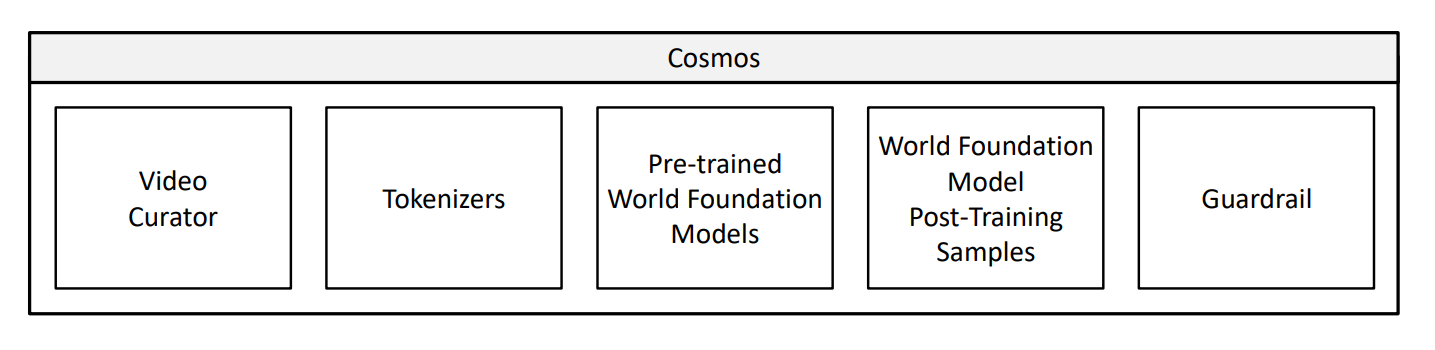
Image Credit: 오리지널 논문
Video Curator (비디오 큐레이터)
WFM의 트레이닝을 위해서, 대규모의 데이터셋에서 높은 품질의 다이나믹한 비디오 클립을 추출합니다. 중복된 것들을 제거해서, 다양하면서도 간결한 트레이닝 데이터셋이 만들어지도록 합니다.
Tokenizer (토크나이저)
비디오의 필수적인 세부 사항은 유지하면서도, 비디오 데이터를 ‘토큰’ (작고 관리하기 쉬운 단위)으로 압축합니다. 이렇게 해서, 트레이닝이 더 빠르고 효율적으로 이루어지도록 합니다.
사전 훈련된 WFM (Pre-trained WFM)
여기는 크게 두 가지 계열의 모델이 포함됩니다.
디퓨전 (Diffusion) 모델
노이즈가 있는 비디오 시뮬레이션으로부터 시작해서, 점진적으로 현실적인 모델로 만들어 갑니다..자기회귀 (Autoregressive) 모델
비디오 시퀀스를 단계별로 구축하는 방식으로 만들어지는 이 모델들은, 세상이 어떻게 움직이는지에 대한 일반적인 패턴을 학습하기 위해서 거대한 규모의 비디오 데이터셋을 가지고 훈련합니다.
사후 훈련 WFM (WFM Post-Training Samples)
사전 훈련된 WFM을 기본으로 해서, 로봇의 움직임을 시뮬레이션한다든가, 가상 세계를 탐색한다든가, 또는 자율 주행을 한다든가 하는 특정한 작업에 맞춰서 파인튜닝합니다.
가드레일:
이 시스템은 WFM이 유해한 입력을 피하고 잘못된 출력을 하지 않도록 통제해서, 이 모델의 사용 중에 개발자 및 시스템, 그리고 사용자를 보호하도록 합니다.
이들 중에 중요한 내용 몇 가지를 순서대로 살펴볼까요?
Video Curator (비디오 큐레이터)
앞에서 말씀드린 바와 같이, WFM의 중요한 목적이 바로 ‘고품질의 트레이닝 데이터를 만드는 것’입니다. 때문에, ‘비디오 큐레이션’ 단계는 전체 시스템에서도 아주 중요한 요소죠. 엔비디아는 모델을 훈련하기 위해서 2천만 시간의 비디오로부터 1억 개의 클립을 고품질로 추출하는 파이프라인을 개발했습니다.
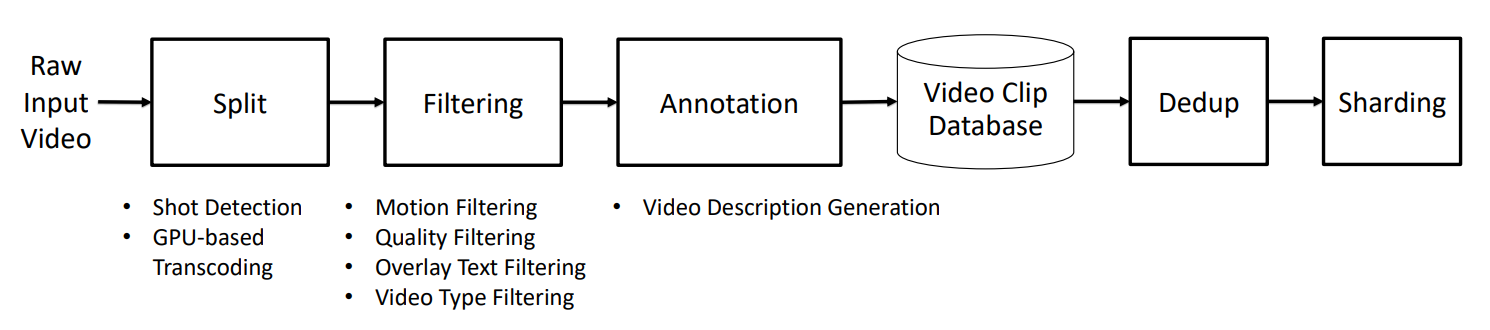
Image Credit: 오리지널 논문
위 그림에서 보듯이, 파이프라인은 이렇게 작동합니다:
시작은 당연히 원본 비디오 수집이겠죠. 독점적인 비디오 데이터 컬렉션, 그리고 공개되어 있는 인터넷 상의 비디오들을 수집하는데, 운전 비디오, 손과 물체의 상호작용, 사람의 다양한 움직임과 활동, 내비게이션, 자연 등 다양한 품질과 형식의 컨텐츠를 포함합니다.
비디오 분할 (Split) 단계에서, 알고리즘이 색상이나 움직임 등과 같은 시각적 특징을 사용해서 장면의 변화를 감지합니다. 2초 미만의 클립은 제거하고, 60초 이상의 클립은 최대 60초로 분할합니다. 그리고 비디오를 고품질 MP4 형식으로 다시 인코딩합니다.
필터링 단계는 데이터셋의 품질을 향상시키는 단계인데요:
모션 필터링: 정적인, 또는 불규칙하게 움직이는 클립을 제거하고, 카메라 패닝이나 줌을 기준으로 클립에 태그를 지정합니다.
품질 필터링: 흐릿하거나 과다한 노출이 되어 있는 등, 즉 품질이 좋지 않은 비디오를 제거하고, 시각적으로 매력적인 컨텐츠만 유지합니다.
오버레이 텍스트 필터링: 학습을 방해할 수 있는 추가된 텍스트 (자막이나 그래픽 등이죠)가 있는 비디오를 제거합니다.
비디오 유형 필터링: 애니메이션이나 추상적 시각 자료 같은, 관련성이 적은 카테고리를 피하고, 사람의 행동 같은 유용한 컨텐츠가 데이터셋에 더 많이 포함되게 합니다.
그 다음으로 주석을 추가하는데, 이 단계는 비디오의 내용에 대한 설명을 추가해서 AI 모델이 데이터를 이해하고 학습하는 데 도움을 줍니다. 이 작업을 위해서 VIVA 13B VLM을 사용해서 각 클립의 캡션 (자막)을 생성합니다.
중복 컨텐츠 제거 단계에서 비디오를 시각적인 컨텐츠 별로 클러스터링해서, 각각 클립의 가장 고품질 버전만 유지하고 중복된 걸로 판단되는 클립은 제거합니다.
샤딩 (Sharding) 단계에서는, 지금까지 처리된 클립들을 해상도, 그리고 길이에 따라서 ‘샤드’, 즉 데이터의 번들로 그룹화합니다. 이렇게 처리해서 데이터셋을 트레이닝에 쉽게 사용할 수 있게 마무리합니다.
위의 모든 단계를 거친 최종적인 결과물로, 사전 훈련 데이터 (광범위하게 모델을 훈련하기 위한 일반용 클립), 그리고 파인튜닝용 데이터 (특수 작업을 위한 고품질 클립)를 포함하는, 큐레이팅된 다양하고 깨끗한 데이터셋이 나오게 됩니다.
Cosmos Tokenizer (코스모스 토크나이저)
엔비디아에서는 이미지와 비디오 데이터를 연속적 토큰화, 이산적 토큰화 방식으로 모두 처리할 수 있도록 Cosmos Tokenizer를 별도로 설계했는데, 이 Tokenizer는 인코더-디코더 디자인을 따릅니다.
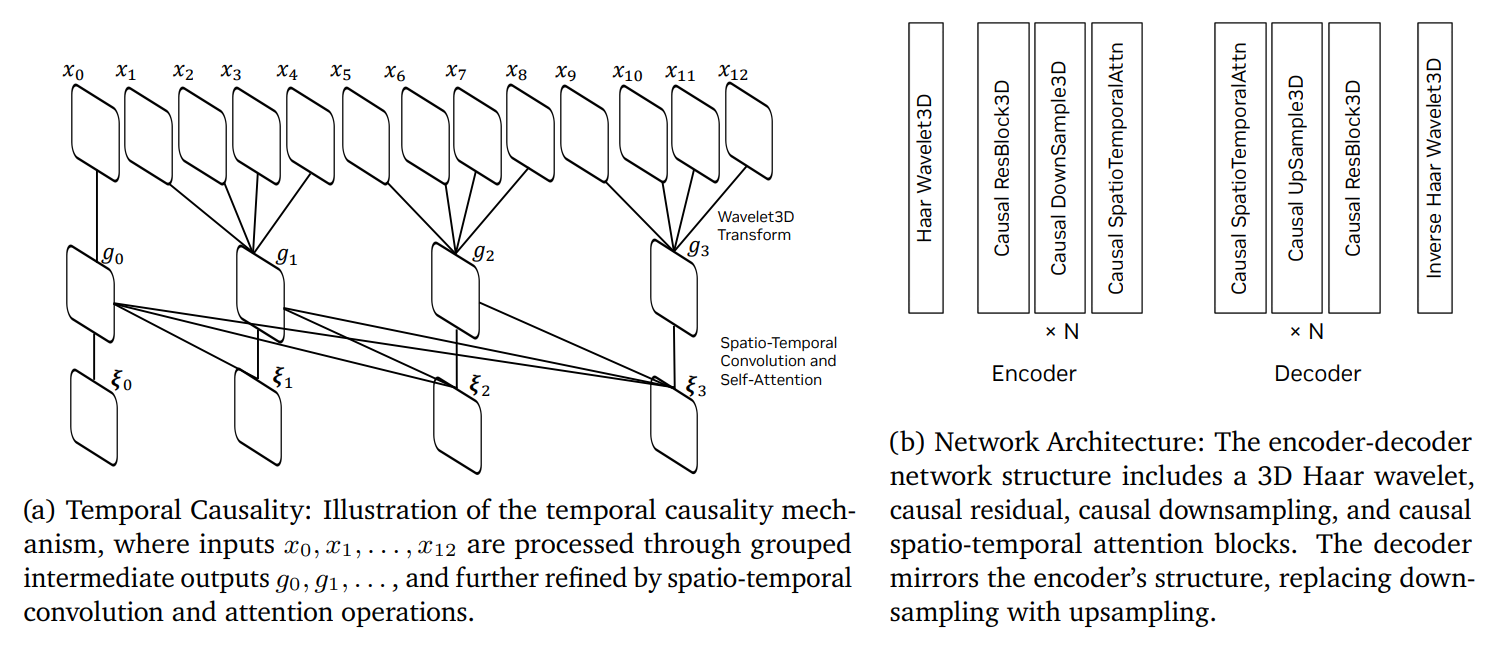
Image Credit: 오리지널 논문
Cosmos Tokenizer의 특별한 점은 무엇일까요?
압축 방식
데이터를 공간적으로(해상도 감소) 그리고 시간적으로(프레임 수 감소) 모두 압축합니다.웨이블릿 (Wavelet) 변환
중복되는 픽셀 정보를 제거해서 비디오의 입력을 단순화하는데, 이 덕분에 ‘인과적 다운샘플링 (Causal Downsampling; 비디오나 실시간 신호를 처리할 때 더 적합한 다운샘플링 방식)’을 할 때의 데이터 처리가 더 쉬워집니다.인과적 다운샘플링 (Causal Downsampling)
미래의 프레임에 의존하지 않고 과거와 현재 데이터를 가지고 순차적으로 프레임을 처리하는데, 이 방식은 실제 비디오나 실시간 신호를 처리해야 하는 AI 어플리케이션에서 상당히 중요합니다.고급 레이어 (Advanced Layers)
이 구조는, 인코딩과 디코딩 과정에서 비디오 프레임의 자연스러운 순서를 유지하기 위해서 ‘인과적 시간 컨볼루션’과 ‘어텐션 레이어’를 사용합니다.시공간 컨볼루션 (Spatio-Temporal Convolution)
데이터로부터 공간적(이미지) 패턴과 시간적(시간) 패턴을 모두 포착하게끔 합니다.셀프 어텐션 메커니즘
모델이 프레임의 전반에 걸쳐서 ‘중요한 세부 사항’에 집중 (Attention)할 수 있도록 돕습니다.잔차 블록 (Residual Block)
입력과 출력 토큰 사이에 ‘지름길 (Shortcut)’ 연결을 추가해서, 그래디언트 흐름 (Gradient Flow)과 훈련의 안정성을 개선합니다.
위와 같은 기능과 그걸 지원하는 구조 덕분에, Cosmos Tokenizer는 높은 효율을 보여줍니다:
더 높은 압축률( 8 × 8 × 8, 8 × 16 × 16) 하에서도 다른 토크나이저들과 비교했을 때 우수한 품질을 유지할 수 있습니다. 16 × 16의 예를 들면, 대체로 경쟁 토크나이저의 8 × 8 이미지 품질과 비슷하거나 더 뛰어납니다.
다른 토크나이저들보다 2~12배 더 빠릅니다.
더 적은 매개변수를 사용해서 가볍고 효율적입니다.
Cosmos 토크나이저는 이미지와 비디오 데이터 모두의 경우에 ‘세부 사항 (Details)’, 그리고 ‘부드러움 (Smoothness)’을 잘 유지한다는 점에서 이전의 다른 토크나이저들보다 뛰어납니다.
자, 이제 이 Cosmos WFM 플랫폼의 진짜 핵심 부분, WFM을 살펴볼까요?
Pre-trained WFMs (사전 훈련된 WFM)
Cosmos 플랫폼에 있는 ‘사전 훈련된 WFM들’은, 비디오를 생성하고 예측하는 아주 강력한 도구예요. 각각의 장점을 활용하기 위해서, 디퓨전 (Diffusion)과 자기 회귀 (Autoregressive) 모델링이라는 두 가지 고급 기술을 모두 사용합니다.
Diffusion WFMs (디퓨젼 WFM)
디퓨전 WFM은 ‘부드럽게 전환’하는, 고품질의 아주 현실성이 높은 출력물을 - 비디오죠 - 생성하는데 탁월한 성능을 보여줍니다. Cosmos Diffusion WFM의 구성 요소들은 아래와 같이 단계별로 함께 작동하게 됩니다.
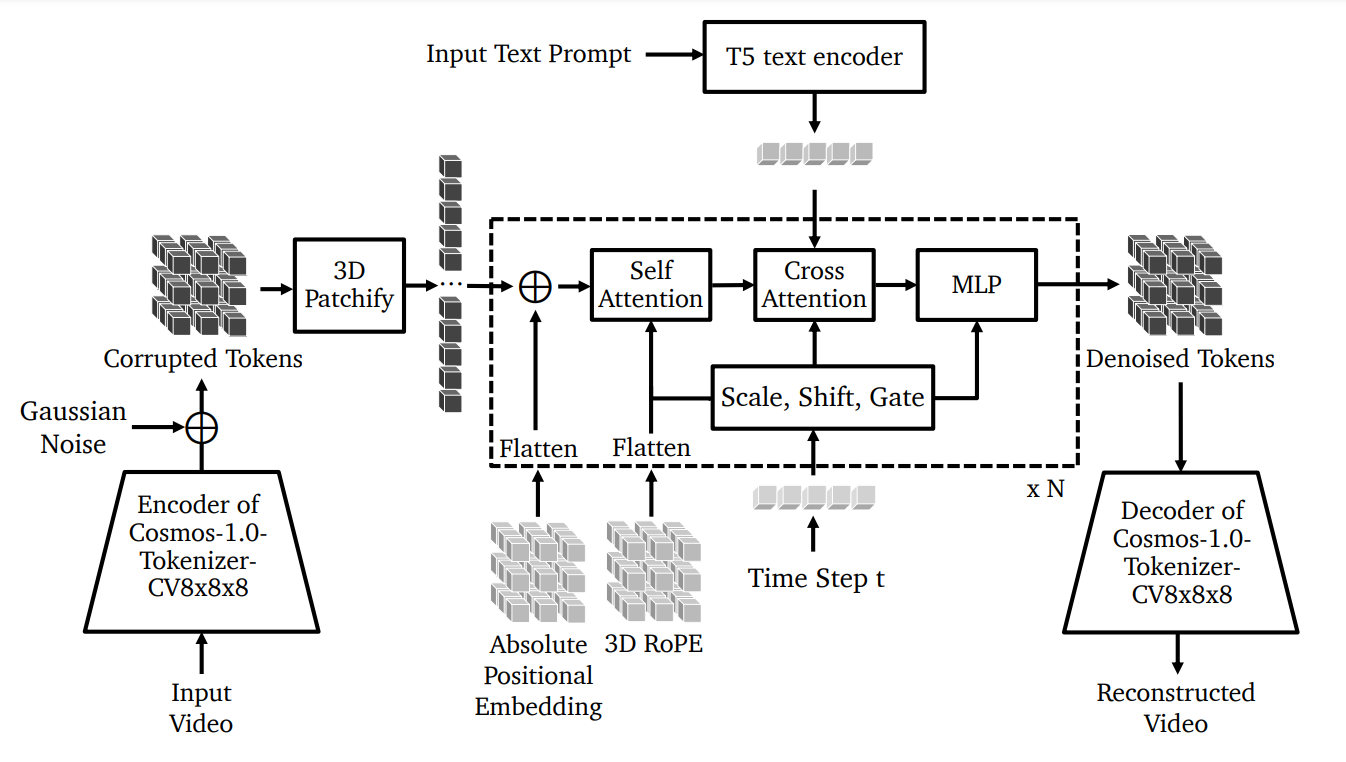
Image Credit: 오리지널 논문, Cosmos-1.0-Diffusion World Foundation Model 아키텍처
모델이 Cosmos Tokenizer를 사용해서 입력 비디오를 압축하는 것에서부터 작업이 시작됩니다. 이 작업을 통해서 비디오를 비교적 단순한 ‘Latent Representation’으로 변환합니다.
Latent Representation에다가, 이후에 모델이 ‘제거’하고 ‘개선’할 대상인 가우시안 노이즈를 추가합니다.
3D 패치화 (Patchification) - 노이즈가 추가된 Latent Representation을, 처리 작업을 단순화하기 위해서 더 작은 3D 패치 (데이터 큐브)로 나눕니다.
이렇게 만들어진 ‘패치들’을, 모델이 아래를 포함하는 여러 가지의 레이어 (계층)을 통해서 처리합니다:
셀프 어텐션: 모델이 비디오 내의 중요한 세부 사항에 집중할 수 있도록 합니다.
크로스 어텐션: 이후의 비디오 생성 과정을 가이드하기 위해서 ‘입력 테스트’로부터 정보를 통합합니다.
순방향 (Feed-forward) MLP 레이어: 각 단계바다 Representation을 정교하게 다듬어 갑니다.
적응형 레이어 정규화 (Adaptive Layer Normalization): 데이터의 스케일 (Scale), 시프트 (Shift), 게이팅 (Gating)을 조정해 가면서 학습이 안정적으로, 그리고 효율적으로 이루어지도록 합니다.
처리가 된 후에, 변화된 - 개선된 - Latent Representation은 토크나이저의 디코더를 통해서 전달, 최종적인 고품질 비디오를 재구성하게 됩니다.
또, Diffusion WFM은 3D RoPE (Rotary Positional Embedding; 회전 위치 임베딩)을 사용하는데, 간단히 말씀드리면 ‘모델이 다양한 길이, 다양한 해상도, 다양한 종횡비를 가진 비디오를 잘 처리’할 수 있게 해 줍니다.
Prompt Upsampler (프롬프트 업샘플러)는 간단한 프롬프트를 상세한 설명으로 변환해서, 생성된 비디오가 사용자의 의도와 일치하고 시각적인 세부 사항을 향상시킬 수 있도록 보장해 줍니다.
Cosmos Diffusion WFM은 ‘두 가지’의 세팅 (Configuration)으로 되어 있는데요:
Text2World 모델
크로스 어텐션 레이어를 사용해서, 텍스트 프롬프트를 기반으로 비디오를 생성합니다.Video2World 모델
기존의 비디오를 확장하거나 미래의 프레임을 예측합니다. 더 풍부한 예측을 할 수 있도록, 초기 비디오와 설명으로 되어 있는 프롬프트를 결합합니다.
그리고, Cosmos Diffusion WFM은 두 가지 사이즈로 출시되어 있습니다 - 바로 Cosmos-1.0-Diffusion-7B, 그리고 Cosmos-1.0-Diffusion-15B 모델입니다. 두 가지 모델 모두 고품질의 현실적인 비디오를 생성하지만, 14B 모델은 7B 모델과 비교해서 더 복잡한 장면을 포착하고 동작의 안정성을 유지하는 데 탁월합니다.
WFM의 Diffusion 기반 버전은, 1) 사실적인 비디오를 생성해 주고, 2) 부드러운 동작 다이나믹스와 텍스트 프롬프트와의 훌륭한 정합성을 보여줍니다.

Image Credit: 오리지널 논문
Autoregressive WFMs (자기 회귀 WFM)
Autoregressive (자기 회귀) 모델은, 단계별 예측에 더 강점을 보여서 ‘순차적인 작업’에 유용한 모델입니다. Cosmos-1.0-Autoregressive-Video2World 모델은, 입력 비디오와 텍스트 프롬프트를 결합해서 미래의 비디오 프레임을 생성합니다.
작동 방식은 다음과 같습니다:
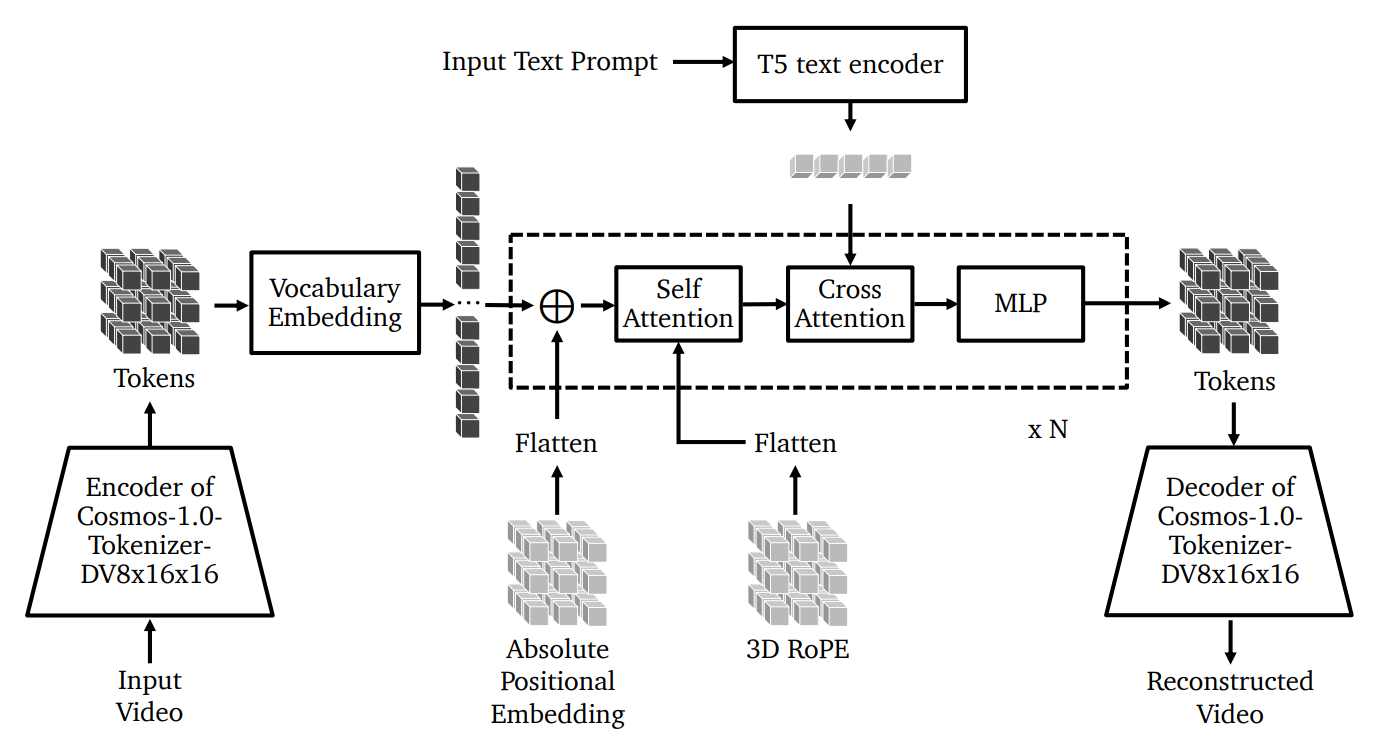
Image Credit: 오리지널 논문, Cosmos-1.0-Diffusion World Foundation Model 아키텍처
입력 비디오를 Cosmos Tokenizer의 인코더를 사용해서 ‘이산 토큰 (Discrete Token)’으로 변환합니다. 텍스트 프롬프트는 T5 텍스트 인코더를 사용해서 처리하는데, 비디오의 생성 과정을 가이드하는 임베딩으로 변환합니다.
비디오 토큰은 추가적인 처리를 위해서 학습된 임베딩으로 변환됩니다. 각 트랜스포머 블록은 아래의 기법을 활용합니다:
3D Positional Embedding (3D 위치 임베딩): 비디오의 공간적, 시간적 관계를 포착하기 위해서 Absolute Embedding과 RoPE (회전) Embedding을 모두 포함합니다.
셀프 어텐션: 비디오 토큰의 중요한 패턴에 집중하도록 해 줍니다.
크로스 어텐션: 크로스 어텐션 레이어는 텍스트 임베딩을 비디오 토큰과 통합해서 출력을 입력 프롬프트와 일치시키는 ‘텍스트 기반 비디오 생성’을 가능하게 해 줍니다.
MLP (2계층 순방향 - Feed-forward 네트워크): 처리된 정보를 개선, 정리합니다.
출력의 재구성: 처리된 임베딩은 Cosmos Tokenizer의 디코더를 사용해서 다시 비디오 프레임으로 변환되어서, 출력 토큰을 기반으로 비디오를 재구성합니다.
세부적인 사항을 선명하게 표현하고, 아티팩트 (원래 의도하지 않았던 화면의 왜곡이나 결함을 말합니다)가 최소화된 비디오를 만들기 위해서, Diffusion Decoder를 이 구조에 추가할 수도 있습니다. 이렇게 하면, ‘이산 토큰’을 고품질의 연속적인 표현으로 변환해서, 특히 더 대형의 Autoregressive WFM에서 공격적인 토큰화 압축 작업의 결과로 나타나는 ‘흐린 출력 (Blurry Output)’ 문제를 해결할 수 있습니다.
이 모델은 아래와 같은 것들이 있습니다:
4B와 12B 파라미터를 가진 기본 모델들
Cosmos-1.0-Autoregressive-13B-Video2World와 같은 Video2World 모델들은 텍스트로 가이드하는 모델 종류입니다. 베이스 모델에서 파생된 이 모델은, Text Conditioning - AI 모델에게 텍스트로 ‘이러이러한 걸 만들어 줘’라고 하는 겁니다 - 을 할 수 있도록 해 주는 크로스 어텐션 레이어를 포함합니다.
모델이 보여주는 결과는 다음과 같은데…
Cosmos-1.0-Autoregressive-13B-Video2World와 같은 더 큰 모델들은, 동작의 일관성을 더 잘 맞춰주고 세부 사항도 더 풍부하게 묘사되는 비디오를 만들어냅니다.
4B와 같은 더 작은 모델들은, 빠르기는 해도 복잡한 작업이라면 어려움을 겪기도 합니다.
…일부 한계점도 발견되었습니다:
‘텍스트 컨디셔닝’ 모델 (Video2World 계열)에서, 모델 자체가 비디오 예측 작업을 중심으로 훈련된 탓에, 입력 텍스트가 항상 생성되는 비디오에 강력한 영향을 미치지 않을 수도 있습니다.
때때로 객체들이 예상치 못하게 나타나기도 하는데, 예를 들어 아래에서 ‘갑자기 튀어나오는’ 것같은 모습을 보여줄 수 있습니다.

Image Credit: 오리지널 논문
Cosmos WFM의 장점은 뭔가?
자, 모든 WFM의 핵심적인 목적은, 바로 ‘실제 세계를 시뮬레이션’하는 거죠? 이걸 다시 말하자면, 좋은 WFM을 만들려면 현실적이고 물리적으로도 일관된 비디오를 만드는 능력을 갖고 있는지 잘 테스트해야 한다는 거겠죠. 즉, WFM의 평가는 1) 3D 일관성 (3D Consistency), 2) 물리적인 정렬 (Physics Alignment)이라는 두 가지 측면에 초점을 맞추게 됩니다.
3D 일관성 (3D Consistency)
‘3D 일관성’은, 생성된 비디오가 현실적인 3D 구조와 기하학적인 원칙을 얼마나 잘 유지하는지 보여줍니다. 이걸 평가하는데는 두 가지 방향이 있는데, 샘슨 오차 (Sampson Error)와 카메라 포즈 성공률을 사용해서 3D 기하학 관점의 준수를 평가하는 ‘기하학적 일관성 (Geometric Consistency)’, 그리고 새로운 시점을 적용했을 때 프레임의 정확도를 평가하는 ‘시점 합성 일관성 (View Synthesis Consistency)’가 바로 그것들입니다.
Cosmos WFM은 이 3D 일관성 관점에서 어느 정도 좋은 성능을 보여줄까요?
Cosmos WFM은 VideoLDM과 같은 기존의 베이스 모델들보다 ‘기하학적인 일관성’과 ‘시점 합성 일관성’ 모두에서 더 좋은 성능을 보여줍니다. 카메라 위치의 추정, 그리고 합성된 시점의 품질 면에서 실제 영상에 근접한 결과를 달성한다고 합니다. (더 쉽게 풀어서 말씀드리면, Cosmos WFM은 기존의 비디오 생성 모델들보다 더 자연스럽고 일관된 영상을 만들어내고, 실제 촬영한 것처럼 자연스러운 카메라 움직임과 화면을 만들어낼 수 있다는 거겠죠?)

Image Credit: 오리지널 논문
물리적 정렬 (Physics Alignment)
‘물리적 정렬’이란 건, 비디오가 중력이라든가 운동 역학 같은 물리 법칙을 얼마나 잘 준수하는지 보는 겁니다. 그리고 관찰된 시나리오를 바탕으로 해서 모델이 현실적으로 일어날 법한 결과를 예측할 수 있는지도 테스트하구요.
Cosmos WFM은 다음과 같은 결과를 보여줍니다:
Diffusion WFM은 픽셀 수준의 지표에서 더 나은 성능을 보여주고, Autoregressive WFM보다 시각적 효과를 더 높은 품질로 렌더링합니다.
모델이 더 크면 시각적인 세부 사항이 더 풍부하지만, 그렇다고 반드시 물리 법칙을 더 잘 준수하는 건 아닙니다.
Cosmos WFM은 객체가 사라지거나 변형되는 것, 그리고 불가능한 움직임이나 중력을 무시하는 것 같이 ‘물리 법칙을 위반’하는 것 같은 일반적인 문제가 여전히 있습니다.

Image Credit: 오리지널 논문
물리적 AI 어플리케이션에서 ‘사후 훈련 WFM’의 구현
자, 그럼 Cosmos 플랫폼 구성에서 ‘네 번째 요소이자 단계’인 ‘사후 훈련 WFM’으로 돌아가 보죠. 이미 말씀드렸다시피, Cosmos WFM은 다양한 종류의 어플리케이션을 지원할 수 있도록 파인튜닝할 수 있는데요. 다음은 엔비디아가 테스트해 본 세 가지 예시입니다:
카메라 제어 (Camera Control)
Cosmos WFM을 파인튜닝하면, 단일한 이미지에서 3D로 탐색할 수 있는 세계를 만들어서 카메라로 탐색해 볼 수 있습니다. 현실적인 시점을 가진, 3D 일관성 및 시간적인 일관성을 가진 비디오를 만든다는 거죠. 사용자는 카메라를 앞뒤로 이동하거나 좌우로 회전시키면서 이렇게 만들어진 세계를 대화형으로 탐색할 수 있습니다. AI 에이전트는 카메라의 움직임을 기반으로 변화를 예측할 수 있구요.
카메라 제어를 할 수 있는 최신의 비디오 생성 모델인 CamCo와 비교했을 때, Cosmos WFM은 비디오 품질이 더 우수하고 카메라 궤적을 재추정하는 정확도가 더 높고, 새로운 궤적과 데이터 분포에도 잘 적응하는 일반화 성능을 보여줍니다. 그리고, 동일한 입력에서도 여러 가지 가능한 미래를 시뮬레이션해서 다양한 출력을 생성할 수 있습니다.
로봇 동작 조작 (Robot Manipulation)
Cosmos WFM은, 지시 사항이라든가 동작을 기반으로 해서 비디오 출력을 예측, 작업 계획과 시뮬레이션을 돕는 로봇을 조작하는 작업용으로 파인튜닝할 수 있습니다.
지시 사항을 기반으로 하는 비디오 예측 작업에서는, 입력값이 비디오 프레임과 텍스트 지시 사항이고, 출력은 로봇이 지시 사항을 따르는 예측된 비디오입ㄴ다.
동작 기반의 다음 프레임 예측 작업에서는, 로봇의 동작 벡터가 텍스트 지시 사항을 대체해서 동작의 결과를 보여주는 다음 비디오 프레임을 생성합니다. 동작 시퀀스를 처리하면, 모델이 로봇이 작업을 완료하는 전체 비디오를 만들 수 있겠죠.
두 Cosmos 모델들 모두 베이스 모델보다 뛰어난 성능을 보여주고, Diffusion 모델은 사람이 평가했을 때 78.3%의 선호도를 보여주었습니다. 예측된 비디오 프레임이 실제 데이터와 아주 유사했다고 하네요.

Image Credit: 오리지널 논문,
Cosmos-1X 데이터셋에서 Instruction 기반의 비디오 예측에 대한 사람의 평가 결과
자율 주행 (Autonomous Driving)
Cosmos WFM을 파인튜닝해서 현실적이고, 일관성도 있고, 제어할 수 있는 ‘다중 시점 주행 시나리오’도 생성할 수 있습니다.
이 모델은 6개의 카메라 시점 (전방, 후방, 좌측, 우측, 후방 좌측, 후방 우측)에서 영상을 생성하고, 자율주행 차량의 카메라 설정을 모방합니다. 지정된 차량 경로에 맞춰서 다양한 주행 시나리오 (교통 밀도, 날씨, 조명, 도로 유형, 차량 속도, 강이라든가 톨게이트)를 생성할 수 있어서, 정밀한 주행 경로 제어를 할 수 있습니다.
Cosmos 모델은 입력된 경로를 7cm 미만의 오차로 따라가면서, 아주 정확하게 경로를 추종할 수 있다는 걸 보여주었습니다. 그리고 여러 개의 시점에서 기하학적, 시간적 일관성을 유지했습니다.

Image Credit: 오리지널 논문
안전성 이슈와 가드레일 시스템
Cosmos WFM 플랫폼은 다양한 분야에서 활용한다는 걸 전제로 설계되었기 때문에, 개발자, 그리고 사용자들이 어떤 사용 사례라 할지라도 이 플랫폼이 안전하다는 확신을 가질 수 있어야 하겠죠. Cosmos의 안전한 사용을 보장하기 위해서, 강력한 가드레일 시스템이 구축되어 있습니다.
이 시스템은 두 단계로 작동합니다:

Image Credit: 오리지널 논문
사전 가드 (Pre-Guard)는 다음과 같은 기능을 사용해서 프롬프트를 방지합니다:
키워드 차단: 차단 목록이 유해한 키워드 (폭력, 비속어)를 필터링하며, "ran"→"run"과 같이 단어의 기본형을 비교하기 위해서 표제어 추출(Lemmatization)을 사용합니다.
Aegis-AI-Content-Safety 모델: 폭력, 위협, 괴롭힘 및 유사한 위험과 관련된 프롬프트를 감지하고 차단하며, 안전하지 않다고 판단될 경우 오류 메시지를 표시합니다.
사후 가드 (Post-Guard)는 다음의 기능을 사용해서 출력물을 필터링, 안전한 비디오 생성을 보장합니다:
비디오 안전 필터: 분류기가 프레임을 검토해서 안전하지 않은 프레임이 있는 경우 해당 비디오를 표시합니다.
얼굴 흐림 (Face Blur) 필터: 20x20 픽셀보다 큰 얼굴을 감지하고 픽셀화해서, 장면의 맥락은 유지하면서 개인정보를 보호합니다.
자, 이렇게 전체적으로 Cosmos WFM 플랫폼의 전체적인 부분을 검토하고, 그 장점과 안전성 이슈에 대한 대응책까지 살펴봤는데요. 하지만 어떤 한계점이 여전히 있을까요?
한계점
여러분과 함께 살펴본 대로, Cosmos WFM은 아주 훌륭하고 유망한 플랫폼이지만, 여전히 초기 단계의 시뮬레이터로서 아래와 같은 주목해야 할 도전 과제들이 있습니다:
살짝 말씀드린 대로, 물체의 영속성, 접촉 역학, 그리고 중력이나 빛의 상호작용과 같은 물리적 정확성과 관련된 문제들이 여전히 있습니다.
생성된 비디오의 현실감이 기본적인 물리 원칙을 제대로 따르지 못하는 경우가 꽤 많습니다.
비디오 품질에 대한 평가가 주관적으로 이루어질 수 밖에 없고, 물리적 충실도를 평가하는데 사람의 편향성이 영향을 미치게 됩니다.
이런 문제들을 해결하기 위해서, 연구자들이 재현성 (Reproducibility)과 인터랙티브 (Interactive) 테스트 (를 위한 자동화된 평가 방식 - 멀티모달 LLM과 물리 시뮤레이터 등을 활용해서요 - 을 도입하려고 하고 있다고 합니다.
맺으며
이번에 발표한 Cosmos WFM 플랫폼을 통해서, 엔비디아는 다시 한 번 ‘통합된 메커니즘으로 완벽하게 작동하는 개념들의 보물창고’를 우리에게 안겨주었습니다. 물리적인 세계를 위한 범용 시뮬레이터를 만드는 이런 도전, 바로 우리가 ‘물리적 AI (Physical AI)’를 향해서 빠르게 나아가고 있다는 걸 보여줍니다.
물론 Cosmos WFM 플랫폼에도 한계가 있고 많은 개선이 앞으로 이어져야 하겠지만, 역시 현재 우리가 손에 넣을 수 있는 것들 중에서 가장 체계적인 접근 방식 중에 하나이고, 무엇보다 사람들이 이걸 가지고 실험해 볼 수 있도록 공개했다는 점이 인상적이라 하겠습니다.
엔비디아에 있어서도, 그리고 AI의 미래를 기대하는 우리 모두에게 있어서, Cosmos는 긴 여정이 시작일 뿐입니다. 이런 도구를 활용해서 더 많은 사람들이 스스로의 역량을 강화하고 다양한 각도에서 물리적 AI에 접근할 수 있다면, 우리의 예상보다 훨씬 빠르게, 물리적 AI와 함께하는 미래를 살아볼 수 있지 않을까요?
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!