


글을 시작하며
자, 튜링 포스트 코리아의 이전 몇 개 글에서, 올해 주목해야 할 AI 핵심요소/트렌드 중의 하나로 ‘강화학습의 부흥(?)’을 말씀드린 적이 있습니다 - ‘사후 학습’의 맥락에서든, ‘로봇과 AI의 결합’의 맥락에서든, 강화학습은 올해 아주 많은 관심을 받을 거예요.
그런 맥락의 하나로, 작년에 나온 논문들 중 아주 중요한 축에 속한다고 생각하는 논문이 바로 ‘자연어와 강화학습의 결합’에 대한 이 논문, ‘Natural Language Reinforcement Learning (자연어 강화학습)’이라는 아주 직설적이고 간단한 내용의 논문입니다. 이 글에서 앞으로 NLRL이라고 부르겠습니다.
NLRL이 뭐고 왜 알아야 될까요? NLRL은, 강화학습의 개념을 자연어가 핵심 요소인 공간에서 작동하도록 적용하는 겁니다. 여기서는 강화학습의 요소인 ‘목표’, ‘전략’, ‘평가 방법’ 같은 것들이 ‘자연어를 사용해서 재정의’됩니다. 놀랍지 않나요? 이걸 거대 언어모델과 결합하면, NLRL의 실용성이 엄청나게 높아지겠죠 - 간단한 프롬프트, 모델 파라미터 등을 통해서 강화학습을 구현하고 실행할 수 있다는 겁니다.
자 그럼, NLRL이 왜, 어떤 점에서 특별하고 혁신적인지, 어떤 면에서 전통적인 강화학습보다 나은지 한 번 살펴보죠.

NLRL, 중요체크!
오늘은 아래와 같은 내용을 다룹니다:
지금의 강화학습에서 아쉬운 것
강화학습은 MDP (Markov Decision Process; 마르코프 의사결정 프로세스)라는 시스템을 사용해서 문제를 수학적인 과제로 설정, 기계에게 의사결정을 가르치는 기법이다 라고 보면 될 것 같습니다. 이 기법이 게임, 로보틱스 등의 분야에서 지금까지 획기적인 발전을 이끌어왔습니다만, 몇 가지 문제점이 있는데요:
사전 지식 (Prior Knowledge)의 부재
수행할 작업에 대해서 유용한 정보가 없이 시작하기 때문에, 환경과 상황이 어떻게 작동하는지 학습하는데 많은 시행착오를 거칠 수 밖에 없습니다.해석이 어려움 (Difficulty in Interpretation)
알파제로 같은 고급의 강화학습 모델조차, 설명하기 어려운 결정을 종종 내립니다.불안정한 훈련 과정 (Unstable Training)
강화학습을 할 때 단순한 수치적 보상에 의존하게 되는데, 실제 환경이 텍스트라든가 시각적 정보 등 더 풍부한 피드백을 할 수 있는 작업 환경이라면 근본적인 제약이 있죠. 이 때문에 일어나는 문제들 - Misspecification 같은 거죠 - 에 대해서는 한 번쯤 들어보셨을 겁니다
위의 문제점을 한 문장으로 요약하자면 ‘강화학습에 사용되는 엄격한 수학적 기법에는 자연어가 가진 유연성, 해석 가능성이 부족하다’는 말입니다. 아시다시피 CoT 같은 기법과 붙어서 강화학습이 AI 모델로 하여금 언어로 추론하는 걸 잘 하게 도와줄 수는 있죠. NLRL은, 강화학습의 과정에서 모델이 자연어로 자신의 학습 진행 상황을 판단할 수 있도록 하겠다는 겁니다. 결국, 중요한 질문은:
단어들만 가지고, 모델이 올바른 추론 경로에 있는지 어떻게 측정할 수 있을까요?
이런 평가를 어떻게 비지도 (Unsupervised) 방식으로, 즉 사람이 제공하는 레이블이나 예시가 없어도 수행하게 할 수 있을까요?
NLRL (자연어 강화학습) 등장하다
이런 문제를 해결해 보려고, 런던 대학교, 상하이 교통대학교, 브라운 대학교, 싱가포르 국립대학교, 브리스톨 대학교 등의 연구자들이 ‘자연어 강화학습(NLRL)’이라는 접근 방식을 제안한 겁니다. 앞에서 잠깐 언급했듯이, NLRL은 순수하게 수학적 표현에만 의존하는 대신, ‘사람은 과제를 이해하고, 전략을 세우고, 추론 과정을 설명하는데 언어를 사용한다’는 것에서 영감을 얻은 겁니다.
이 아이디어는 강화학습의 핵심 개념들 - 전략, 목표, 평가 등 - 을 자연어 환경에서 재해석, 표현하는 겁니다. 이 방법을 쓰면 거대 언어모델이 기존의 레이블된 데이터가 없더라도 주어진 환경에서 상호작용을 하면서 직접 학습할 수가 있고, 그 때 그 때 내린 결정에 대해서 직관적인, 언어 기반의 설명, 그리고 더 풍부한 피드백을 제공할 수 있습니다.
이 연구자들은 왜 강화학습과 자연어를 연결시키고 싶었을까요? 논문 저자들 중 한 명인 Xidong Feng의 트위터 포스트를 보면, ‘거대 언어모델이 언어를 기반으로 게임을 진짜 이해하게 만들고 싶다’는 아이디어에 끌렸다고 해요 - 단순히 규칙에만 머물지 않고 전략을 세우고 평가하는 것까지 말이죠.
Xidong Feng은 이전에 ‘ChessGPT: Bridging Policy Learning and Language Modeling’이라는 논문을 통해서 온라인에서 사용 가능한 사람의 게임 플레이 데이터를 사용하는 접근 방식을 시도한 적이 있는데, 이건 비용이 너무 많이 들기도 하고 데이터의 일관성 문제도 있고, 게다가 새로운 게임이나 새로운 작업에 대해서는 확장성이 부족하다는 결론을 낸 바 있습니다.
그래서 이미 CoT (Chain-of-Thought) 기법과 관련된 사례에서 볼 수 있듯이 자연어와 강화학습을 결합했을 때 좋은 결과를 보여줄 수 있다는 것에 힌트를 얻어 ‘강화학습’에 눈을 돌리게 된 것이죠. 자, 그럼 ‘강화학습’이 ‘자연어’로 업그레이드되었을 때 어떤 일이 일어나는 건지 한 번 볼까요?
NLRL의 작동 방식
강화학습의 핵심 개념을 ‘자연어’로 재정의
텍스트 기반의 MDP (Markov Decision Process; 마르코프 의사결정 프로세스)
전통적인 강화학습에서는 MDP가 ‘상태 (States)’, ‘행동 (Actions)’, ‘전이 (Transitions)’, ‘보상 (Rewards)’를 사용해서 의사결정이 일어나는 환경을 표현합니다. NLRL은 이런 요소들을 ‘텍스트’라는 관점과 도구로 재정의하게 되죠:
상태 (S)
현재의 상황이라든가 환경을 의미합니다. “당신은 교차로에 있습니다” 같이 자연어를 사용해서 설명되게 됩니다.행동 (A)
“직진하세요”, “위로 이동” 같이 언어에 기반한 결정을 표현합니다.피드백 (전이/T 및 보상/R)
숫자값 대신 “목표에 도달했습니다” 같은 텍스트 설명으로 제공됩니다. 예를 들어서, NLRL은 “목표 지점에 도달하기” 또는 “문 열기” 같은 언어적인 목표로 시작하게 됩니다.
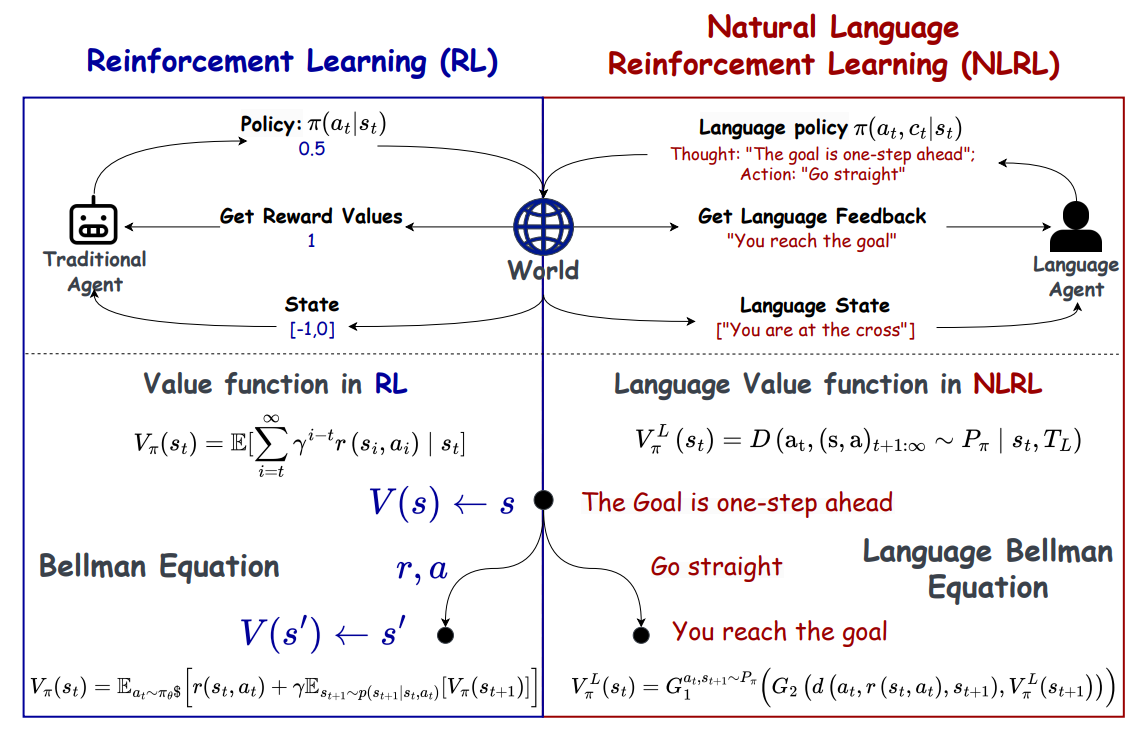
Image Credit: 오리지널 논문
언어로 과제 지시 (Language Task Instruction)
NLRL은 "목표 지점에 도달하기" 또는 "문 열기"와 같이 자연어로 과제를 지시하고, 이렇게 지시한 과제가 에이전트의 성능을 평가하는 기준점이 됩니다 - 중요한 건 ‘에이전트의 행동이 과제와 얼마나 잘 부합하는지’ 측정하는 걸 텐데, 이건 에이전트의 행동을 언어적인 요약으로 바꿔서 기술한 ‘Trajectory Description’을 평가하는 방식으로 이루어지게 됩니다. 궁극적 목표는, 이 Trajectory Description이 과제의 지시 내용과 일치하도록 에이전트의 정책 (Policy)을 최적화하는 겁니다.
자, 그럼 이제 이 정책 (Policy)이라는게 뭔지 이야기해 보죠.
언어 정책 (Language Policy)
전통적인 강화학습의 목표도 이 ‘정책 (Policy)’를 학습하는 것이죠. 정책이란 건, 주어진 상태에서 에이전트가 취해야 할 최선의 행동을 알려주는 일종의 ‘전략’ 같은 건데요. 최적화된 정책은 예상할 수 있는 장기적인 보상을 극대화해 줍니다.
확률에 기반해서 직접 취할 행동을 선택하는 대신에, NLRL은 CoT (Chain-of-Thought) 과정을 통합해서 행동을 취하게 합니다. 따라서, 여기서 이야기하는 ‘언어 정책’'이라는 건 아래와 같은 요소를 포함하게 됩니다:
자연어로 기술된 - 표현된 - 전략적 추론, 논리적 단계, 그리고 계획
두 개의 단계로 생성되는 행동 (Actions)
추론 과정 자체의 생성
위의 ‘추론 과정’에 따라 생성된 행동
언어 가치 함수 (Language Value Function)
강화학습 환경의 에이전트는 특정한 상태에서 앞으로 받을 보상들을 고려해서 선택을 하게 되는데요. 현재 시점에서 앞으로 받을 보상들의 합을 계산하는 개념이 바로 ‘가치함수’입니다. 가치함수에는 상태 가치함수와 행동 가치함수 - Q 함수라고도 하죠 - 라는게 있다는 정도만 기억하시면 될 것 같구요.
NLRL에서는 기존의 강화학습에서 고려하는 상태 가치 (State Value)와 상태-행동 가치 (State-Action Value) 대신에, 자연어로 상태와 행동을 평가하는 언어 가치 함수를 도입합니다:
언어 상태 가치 (Language State Value)
과제를 달성한다는 관점에서, 특정한 상태 (State)가 얼마나 유효한 것인지 평가합니다.언어 상태-행동 가치 (Language State-Action Value)
상태-행동 쌍 (State-Action Pair)의 유효성, 효과성을 평가합니다.
이런 ‘가치 함수’들은 전통적인 ‘수치 점수’에 비해서 더 해석하기 쉽고 피드백도 상세하게 받을 수 있습니다. 예를 들어서, 의사결정의 이면에 존재하는 논리적인 추론 내용, 미래의 결과에 대한 예측, 그리고 서로 다른 행동들을 언어로 비교해 볼 수 있는 거죠.
언어 벨만 방정식 (Language Bellman Equation)
‘벨만’이라는 이름 때문에 굉장한 수학적 개념이 있다고 생각하실 수도 있지만, 그냥 단순하게 ‘현재 상태의 가치함수’와 ‘다음 상태의 가치함수’의 관계식이 바로 벨만 방정식이다라고 생각하시면 되겠습니다. 이 벨만 방정식을 풀어내는 과정에서 최적의 정책을 찾는 것 - 최고의 보상을 받는 것 - 이 바로 강화학습의 과정이라고 할 수 있겠구요.
NLRL은 이 아이디어를 언어 벨만 방정식으로 변형하는데요. 이 방정식에서는 아래와 같은 요소를 활용하게 됩니다:
중간 전이 과정 (Intermediate Transitions)에 대한 언어적인 설명
정보 집계 함수(Information Aggregation Functions; G1과 G2)
G1: 서로 다른 행동과 전이에 걸친 피드백을 결합합니다. (전통적인 강화학습의 평균 계산과 유사하게요)
G2: 즉각적인 피드백과 미래의 평가를 결합해서, 기존 벨만 방정식의 합산 단계를 모방합니다.
언어 정책 (Language Policy)를 평가하는 기법
반복해서 말씀드리지만, NLRL은 ‘강화학습 기법을 자연어의 영역에서 작동하도록 적용하는 것’인데요. 그래서 언어 정책이나 전략이 얼마나 잘 작동하는지 측정하기 위해서, 연구자들은 표준적인 강화학습 방법을 재정의해야 했습니다. 여기 그 방법들이 있는데요:
언어 MC (몬테카를로) 추정
몬테카를로(MC) 기법은 수치적 결과를 추정하기 위해서 반복적으로 무작위 샘플링을 하는 알고리즘의 한 종류라고 하겠습니다. 강화학습에서는, 완전한 궤적 - 즉, 전체 에피소드 - 의 결과를 평가하고 편향되지 않은 수익 (Returns)의 추정치를 제공하는데 자주 사용되는데요. 이 기법은 무작위성을 기반으로 ‘결과의 공간’을 탐색하게 되니, 다양한 적용이 가능하고 효과적이기도 합니다.
NLRL에서 사용하는 MC 추정은, 에이전트의 현재 정책을 사용해서, 상태에서 시작해서 여러 개의 완전한 텍스트 기반 궤적 - ‘롤아웃 (Rollouts)’이라고 부르는데요 - 을 시뮬레이션하면서 텍스트의 영역에 적응합니다. 각각의 궤적은 자연어로 표현된 행동과 결과의 순서를 나타내구요. 수칙적인 수익을 평균낼 수 있는 전통적인 강화학습과는 다르게, NLRL은 정성적인 정보를 정량적인 평가로 집계해야 한다는 과제를 해결하기 위해서 집계 함수 G1을 사용, 자연어 설명을 요약 값으로 결합해서 만들어내야 합니다.
장점
MC 추정은 완전한 궤적을 사용하여 직접 평가하므로 ‘편향’을 피할 수 있습니다.단점
미래의 단계가 많이 달라질 수 있으니 변동성이 높을 수 있고, 이 때문에 G1 함수가 정보를 효과적으로 결합해서 종합하기가 더 어려워집니다.
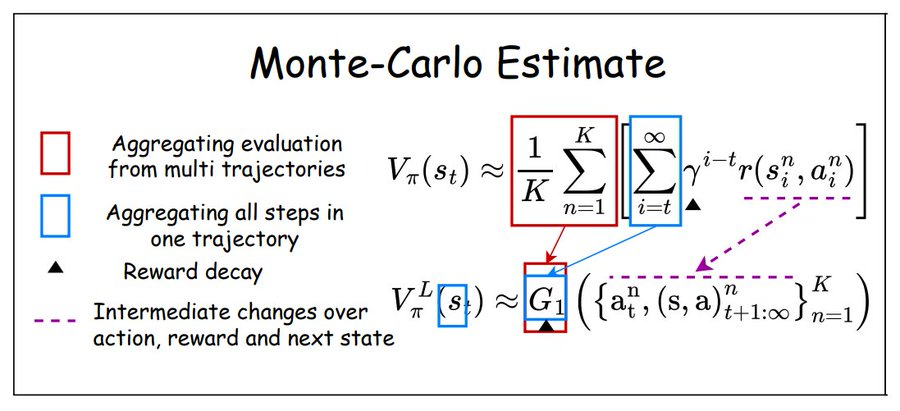
Image Credit: 오리지널 논문
언어 TD (시간차; Temporal Difference) 추정
몬테카를로 (MC) 추정이라는게, 충분히 많은 반복을 통해서 MDP를 풀어나가는 방법인데, 이건 에피소드가 길거나 끝이 없는 연속 결정 문제에는 적용하기가 어렵죠. 그래서 시간차 (TD: Temporal-Difference) 학습이라는 걸로 각 타임 스텝마다 가치함수를 업데이트하는 방식으로 MC 방식의 단점을 보완합니다. 바둑으로 따지자면, MC 추정은 바둑을 마친 후에 처음부터 끝까지 다시 두면서 생각하는 ‘복기’, TD 추정은 하나 하나 두면서 업데이트 되는 거라고 하면 될 거 같습니다.
앞에서 ‘언어 MC 추정’에서는 전체 궤적 - 에피소드 전체 - 을 사용해서 평가를 한다고 했는데요. 위에 설명처럼 언어 TD는 ‘한 단계 앞만’을 고려합니다. 언어 벨만 방정식을 사용해서 상태의 가치를 ‘즉각적 보상’과 ‘다음 상태의 가치’ 두 부분으로 나누는데요. 다시 말해서, G1 함수를 사용해서 한 단계의 언어 설명을 집계하고, G2를 사용해서 즉각적인 평가와 미래의 평가를 결합하는 겁니다.
장점
TD는 전체 궤적이 아닌 단기적 변동에 초점을 맞추게 되어 변동성을 줄일 수 있고, 빠르기도 합니다.단점: 다음 상태의 가치가 단지 추정치일 뿐이라서 정확하지 않을 수 있어, ‘편향’을 초래할 수 있습니다.
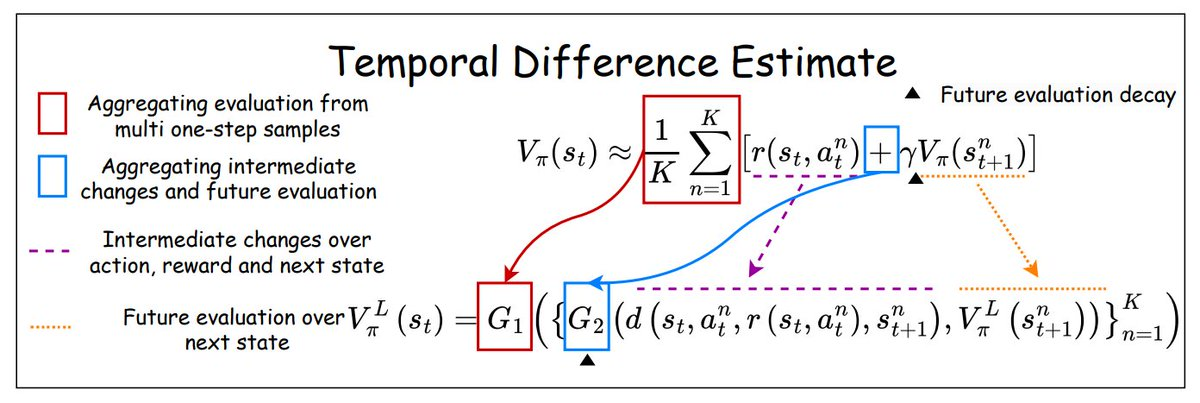
Image Credit: 오리지널 논문
LLM, NLRL과 찰떡같은 합
위에서 말씀드린, 모든 NLRL의 개념과 구성 요소를 실현하고 작동시키려면, 바로 LLM이 필요하겠죠! LLM이 언어를 이해하고, 처리하고, 생성하는 걸 아주 잘 하는 모델이니까요. NLRL 프레임웍 내에서 LLM은 의사결정자, 평가자, 그리고 트레이너의 역할까지 수행합니다:
언어 정책으로서의 LLM
LLM은 의사결정 에이전트로 작동하면서 자연어 추론 - CoT 같은 - 을 기반으로 행동을 생성합니다. 예를 들어, "목표 지점까지의 거리를 줄이기 위해 전진하세요." 같은 거요.언어 가치 함수로서의 LLM
전통적인 강화학습이 수치적 가치 함수를 사용해서 결정을 가이드하는 것처럼, LLM은 "이 움직임은 미래의 가능성을 열어줍니다"와 같이 상태와 행동에 대한 통찰력이 있는, 텍스트 기반의 평가를 생성합니다.언어 몬테카를로(MC) 연산자, 언어 시간차(TD) 연산자로서의 LLM
LLM이 행동의 결과 같은 즉각적인 피드백을 미래의 평가와 결합, 상태나 행동의 가치를 추정합니다.MC와 TD 추정치의 Distillation (증류)
LLM은 비지도방식의 상호작용 (Interaction) 데이터 기반 훈련을 통해서 ‘언어 기반 가치함수’를 근사 (Approximation)하는 법을 학습하게 됩니다.정책 개선 연산자 (Policy Improvement Operator)로서의 LLM
LLM은 다양한 행동과 그 평가를 분석해서, 주어진 상태에 대한 최선의 행동을 선택하도록 하는 역할을 합니다.언어 정책 훈련
정책 그래디언트와 같은 불안정한 강화학습 기법을 사용하는 대신, NLRL은 안정성과 정확성을 위해 지도 학습을 사용합니다.
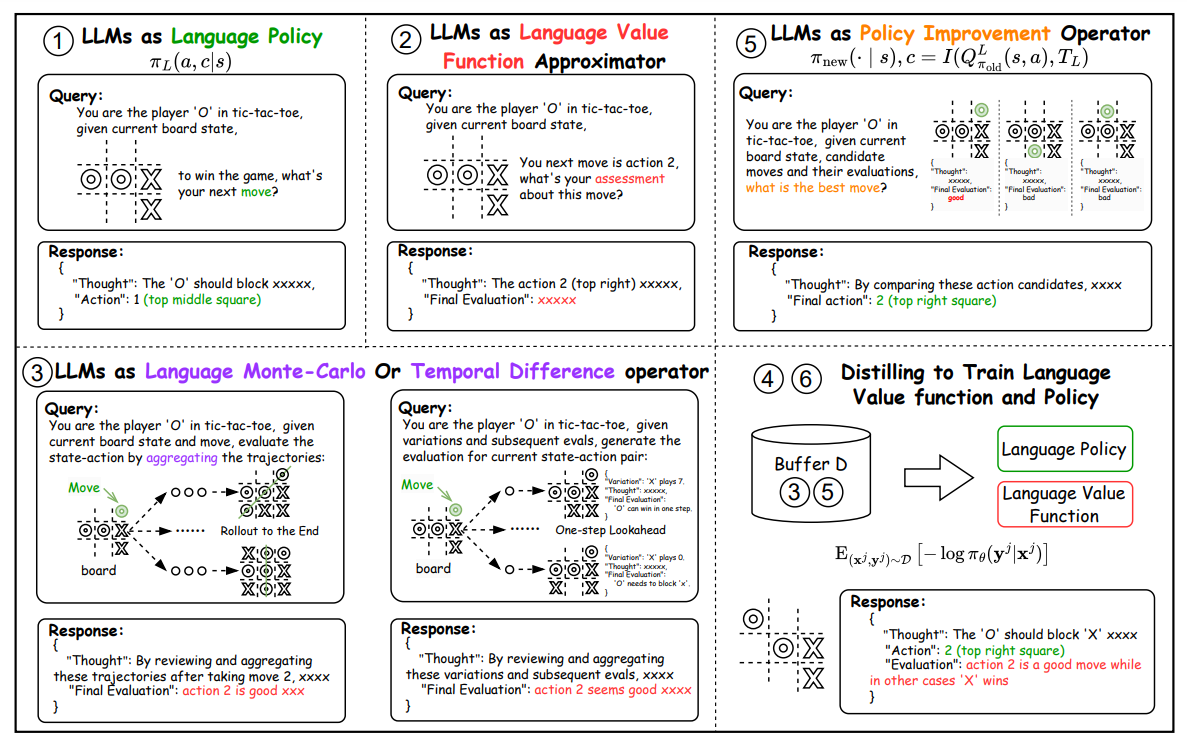
Image Credit: 오리지널 논문
간단히 정리해 보자면, NLRL은 의사결정, 피드백 루프에서의 평가, 개선, 프롬프트를 사용한 비평과 계획, 그리고 선택에 대한 설명과 같은 작업을 수행하기 위해서, 전통적인 강화학습 메커니즘 대신 LLM을 사용합니다. 숫자를 생성하는 전통적인 강화학습 모델과 달리, LLM은 사람이 읽을 수 있는 설명을 생성해서 시스템이 내린 결정을 이해할 수 있게 도와줍니다. 그리고, 특정한 작업에 맞게 파인튜닝을 하거나 프롬프트를 조정하는 등의 유연성도 제공합니다.
실제로 NLRL이 얼마나 잘 작동하나? 그리고 장점은?
자, 연구진들은 NLRL 접근 방식이 성능을 얼마나 향상시키는지 측정해 보려고 다음과 같은 세 가지 시나리오에서 테스트를 진행했다고 합니다:
T자형과 중간 사이즈 미로 (Maze)를 이용한 미로 게임 실험으로, 언어 시간차(TD) 기법 및 정책 개선이 미로에서의 의사결정을 어떻게 향상시키는지를 평가했습니다.
브레이크스루 보드 게임에서 5x5 브레이크스루 보드 게임의 상태를 평가하기 위한 언어 가치 함수를 훈련했습니다.
자연어 액터(Actor)-크리틱(Critic)을 적용한 틱택토 게임으로, 더 단순한 게임 환경에서 완전한 자연어 액터-크리틱 프레임웍을 검증했습니다.
실험 결과는 다음과 같습니다:
미로 게임 실험:
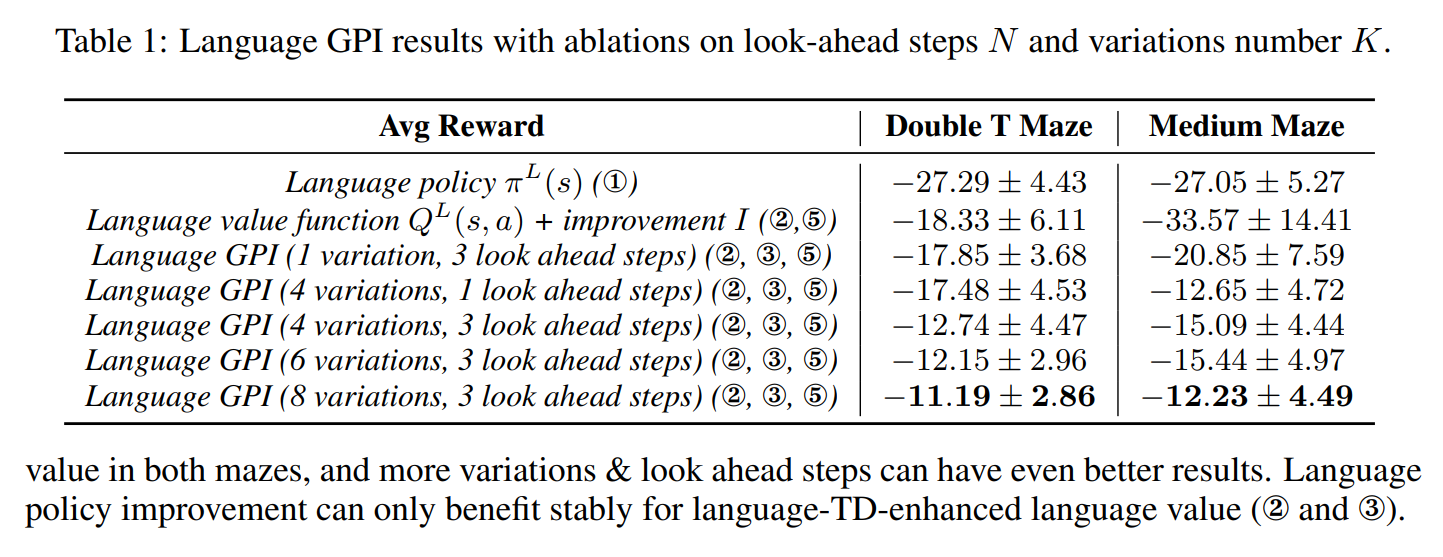
언어 TD 기법은 기본적인 프롬프트 기반의 정책들과 비교했을 때 훨씬 더 좋은 성능을 보였습니다.
변형이 더 많을수록, 선행 단계를 더 많이 확인할수록 성능이 향상되었지만, (당연하게도) 한계 효익은 빠르게 체감하는 모습을 보였습니다.
언어 정책만으로는 약 -27의 보상 (좋지는 않은 성능이죠)을 달성했지만, 6가지의 변형, 3단계의 선행 단계 확인을 적용한 언어 TD 기법으로는 -12의 보상 (상당한 개선이죠)을 획득했습니다.
Image Credit: 오리지널 논문
5x5 브레이크스루 보드 게임
베이스라인을 세팅해 보면, GPT-4와 같은 사전 학습된 LLM을 사용한 프롬프트 기반의 평가는 약 61%의 정확도로 저조한 성능을 보였습니다.
언어 TD 기법으로 훈련한 언어 가치 함수는 85% 이상의 정확도를 달성했습니다.
롤아웃 단계와 데이터셋 크기를 다양화한 결과 확장성과 견고성을 보여주었지만, 너무 많은 선행 단계를 확인하게 될 경우에 과적합의 위험이 있다는 것도 드러났습니다.
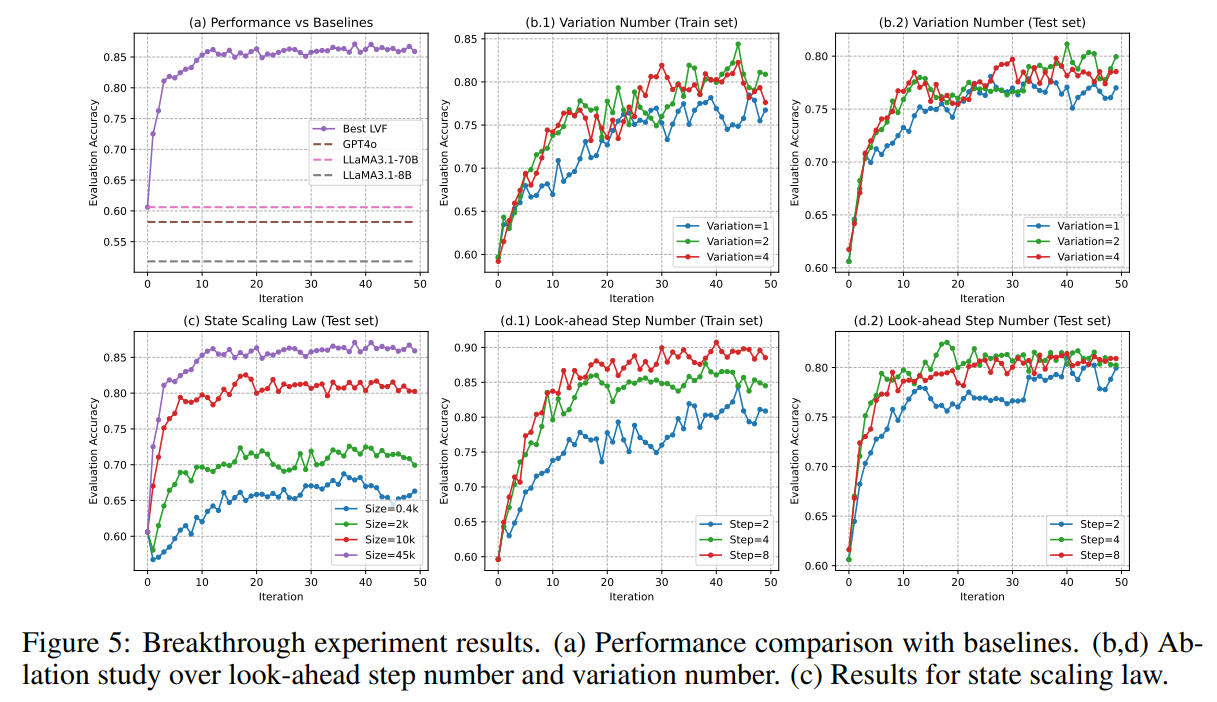
Image Credit: 오리지널 논문
자연어 액터-크리틱을 적용한 틱택토 게임
NLRL은 결정론적 상대, 무작위 상대 모두에 대해서 베이스라인보다 더 높은 승률을 달성했습니다. 심지어 강화학습의 PPO(Proximal Policy Optimization) 방식보다도 더 좋은 성능을 보였습니다.
훈련 에포크를 증가시키면 안정성이 향상되었습니다.
과거 경험을 유지하기 위해 더 큰 버퍼를 사용하면 망각을 줄일 수 있었습니다.
반복 당 더 많은 롤아웃 궤적을 사용하면 더 안정적인 학습 곡선을 얻을 수 있었습니다.
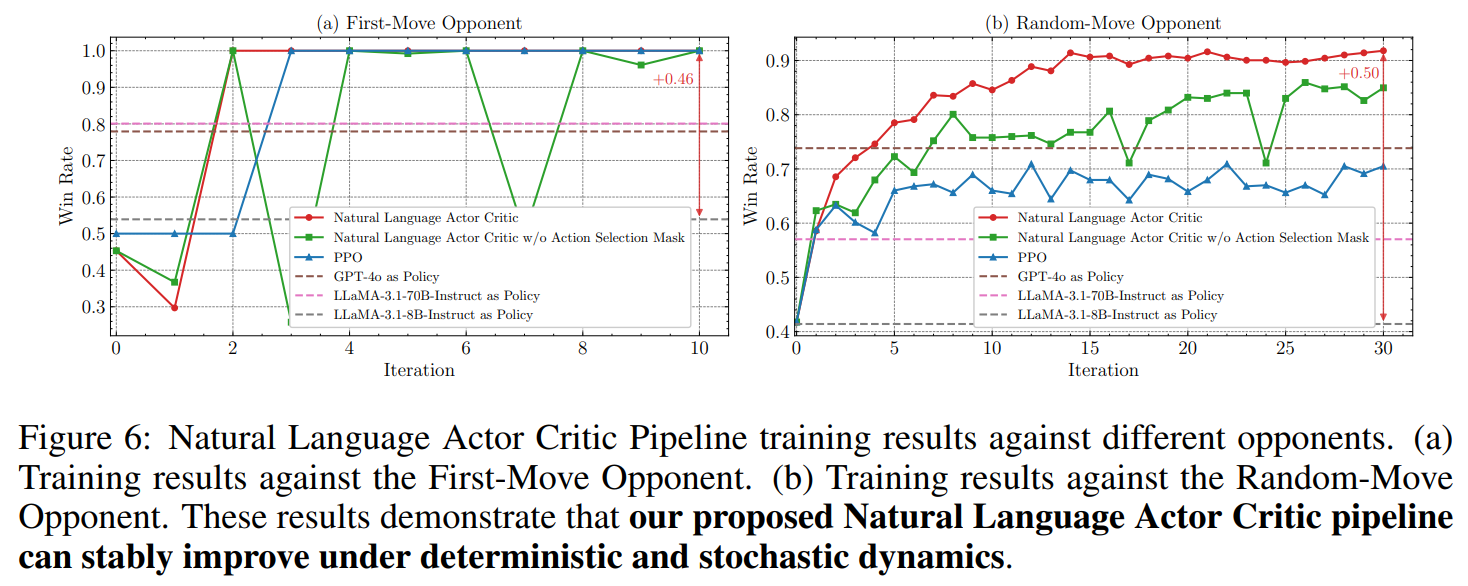
Image Credit: 오리지널 논문
이런 실험들을 통해서, 자연어의 ‘해석 가능성 (Interpretability)’을 강화학습의 ‘엄밀성 (Rigor)’와 결합해서 거둘 수 있는 NLRL의 잠재력을 확인할 수 있습니다.
이미 NLRL을 통해 얻을 수 있는 많은 좋은 점들을 언급했습니다만, 한 번 다시 중요한 장점을 정리해 보죠:
사전 지식의 활용
거대 언어모델 (LLM)에 저장된 방대한 정보를 활용해서, 새로운 작업에 빠르게 적응할 수 있습니다.더 나은 해석 가능성
NLRL은 자연어를 사용해서 의사결정을 하고 에이전트의 추론 과정을 더 이해하기 쉽게 설명합니다. 모든 출력은 사람이 읽을 수 있구요.더 풍부한 피드백
텍스트 피드백을 통합할 수 있어서, 더 안정적이고 효과적으로 훈련을 할 수 있습니다.LLM이 주는 이점을 레버리지
LLM의 강점 (예를 들어 추론, 집계, 언어 생성)을 활용해서, 언어 기반 환경에서 효과적이면서도 해석 가능한 시스템을 만들 수 있습니다.더 나은 계획과 비평
간단한 지시를 통해서 언어 모델의 계획 수립 능력과 자체 행동 비평 능력을 향상시킬 수 있습니다.평가
자연어 가치 함수를 통해서 상황을 평가하도록 모델을 훈련시켜서, 사람이 신뢰할 수 있는 평가를 제공할 수 있습니다.명확한 추론
전통적인 ‘액터-크리틱’ 접근 방식과 유사한 훈련 파이프라인을 통해서, 시스템이 텍스트 기반 피드백만으로 학습해서 명확하고 해석 가능한 추론을 생성할 수 있습니다.확장성
NLRL 프레임웍은 미로부터 보드 게임까지 다양한 환경을 다룰 수 있기 때문에, 우수한 ‘일반화 (Generalization)’ 가능성을 보여준다고 할 수 있습니다.
NLRL의 한계
AI 연구 커뮤니티의 NLRL에 대한 논의 쓰레드를 살펴보면, NLRL의 한계점이나 이슈는 뭐냐라는 질문이 꽤 많은 걸 알 수 있습니다.
NLRL의 첫 번째 심각한 한계는, 바로 ‘제한된 행동 공간’입니다. 게임 실험들은 "위로 이동", "직진", 또는 격자의 9개 위치 중 하나를 선택하는 것과 같은 ‘이산적 공간’에서의 성능을 보여주는 거죠. 하지만 로보틱스와 같은 ‘연속적’인 행동 공간이나 ‘고차원’의 작업에서 NLRL이 어떤 성능을 보여주는지는 아직 연구되지 않았습니다.
두 번째 중요한 한계는 ‘LLM의 높은 계산 비용’입니다. 의사결정을 위해 상당한 컴퓨팅 자원이 필요하고, 결과적으로 - 적어도 현재 상태로는 - NLRL은 비교적 소규모의 어플리케이션에 제한해서 적용하는게 용이하겠죠.
더불어서, LLM 때문에 따라오는 또 다른 한계는, ‘NLRL이 더 작은 네트워크를 사용하는 전통적인 강화학습 방법들에 비해 시간이 많이 필요하다 (Less Time-Efficient)’는 점입니다.
맺으며
AI의 혁신이란, 새로운 개념을 만들어내고, 이런 새로운 개념을 고전적인 기계학습 개념에 적용하면서 새롭게 재해석해내는 정반합의 과정이 반복적으로 일어나는 프로세스라고 생각합니다. 이런 ‘재해석’의 과정 자체가, 더 효율적인 시스템을 만들어가기 위한 하나의 중요한 경로가 되구요.
NLRL은, 강화학습의 원리가 자연어의 풍부한 능력과 원활하게 통합되는, 하나의 ‘새로운 장’의 시작을 의미하는게 아닐까 느끼고 있습니다. 어떤 분들은, ‘이미 기존의 강화학습에서 모든게 충분히 잘 작동하는데, 왜 자연어를 적용하고 자연어로 해석을 해야’ 하는지 의문을 가지실 수도 있을 겁니다. 그렇지만, 그런 새로운 접근을 통해서 ‘인간 친화적인 접근 방식’으로 AI를 진화시키는 것, 그것이 어쩌면 우리가 지향해야 하는 AI의 본령이 아닐까 하는 생각도 해 보면 좋을 것 같습니다.
보너스: 참고 자료
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!