


글을 시작하며
튜링 포스트 코리아에서 이전에 MoE (Mixture-of-Experts) 기법에 대해서 커버한 적이 있었습니다.

MoE 기법이 다양한 ‘전문가’ 중에서 가장 적합한 전문가를 선택해서 토큰을 처리하도록 하는 방법이라면, MoD (Mixture-of-Depths) 기법은 각각의 토큰에 대해서 더 깊이, 또는 덜 깊이 계산을 수행하도록 선택하는 방법입니다.
가만히 생각해 보면, 트랜스포머가 시퀀스의 각 토큰이나 단어에 할당되는 컴퓨팅 자원을 조절하지는 않습니다. 그렇지만 실제로는 어떤 단어는 더 많은 주의를 기울여야 하고, 다른 단어들은 별 의미가 없어서 건너뛰는게 좋을 수 있겠죠?
이런 개념에서 착안해서, 구글 딥마인드, 캐나다의 맥길 대학교, 그리고 몬트리올의 MILA 연구진들이 트랜스포머의 효율성을 높이는 새로운 방법, MoD (Mixture-of-Depths) 기법을 제안했습니다.
이미 이해하셨겠지만, 이 기법은 입력 시퀀스의 어느 부분에 더 많은 자원이 필요한지 파악, 선택해서 트랜스포머의 컴퓨팅 파워 (FLOPs) 사용을 최적화합니다. 이제 트랜스포머의 ‘깊이’라는 개념에 대해서 좀 더 살펴보면서, MoD의 작동 방식, 전반적인 성능에의 영향, 우리에게 줄 수 있는 이점 등을 알아보겠습니다.
오늘 에피소드에서는 아래와 같은 내용을 말씀드리겠습니다:
트랜스포머의 ‘과도한 연산량’ 문제
현재 기준 AI 업계의 주류, 트랜스포머 모델. 이 모델은 기본적으로는 각각의 단어 - 또는 토큰 - 에 동일한 양의 컴퓨팅 파워를 사용하게 되는 구조로 만들어져 있습니다. 생각해 보면, 너무나 자연스럽게도 이는 불필요한 자원의 낭비를 불러올 수 밖에 없죠. 따라서 추가적인 처리가 더 필요한 단어와 토큰에 집중한다면, 전력, 시간 등의 자원을 절약할 수 있을 겁니다.
이럴 때, ‘조건부 연산 (Conditional Computation)’을 생각하게 됩니다. 이건 ‘조기 종료 (Early Exiting)’라든가 우리가 잘 아는 ‘MoE (Mixture-of-Experts)’ 같은 기법으로 트랜스포머의 컴퓨팅 자원을 관리하는, 일반적인 접근 방식인데요. ‘조기 종료’는 특정한 토큰에 충분한 수준의 처리를 했다고 생각하면 중단하고 남은 층을 건너뛸 수 있게 하고, MoE는 토큰 자체를 필요한 ‘전문가’에게만 전달하고, 모델의 다른 부분들은 ‘비활성 상태’로 남겨두는 거죠.
이미 이야기한 이런 기법들보다 더 효율적인 건 없을까요? 어떻게 하면 트랜스포머가, 더 똑똑하게, 더 많은 처리가 필요한 토큰에만 집중하게 할 수 있을까요?
MoD (Mixture-of-Depths)의 등장과 작동 방식
이런 관점에서 새로운 해결책을 찾아보자는 목표로, 구글 딥마인드, 캐나다 맥길 대학교, 몬트리올의 MILA (Montreal Institute for Learning Algorithms) 연구자들이 함께 트랜스포머 아키텍처의 깊이를 더욱 심도있게 연구한 결과, MoD (Mixture-of-Depths)라는 기법이 등장하게 되었습니다.
MoD는 ‘조기 종료 (Early Exiting)의 요소를 포함한 MoE’라고 이해해 보면 비슷한데요. MoD 기법은 각각의 단어 - 토큰 - 의 처리 여부를 포함해서, 네트워크 층을 통과할 때 모델의 어느 깊이까지 가야 할 건지까지도 결정합니다. 이렇게 불필요한 층을 건너뛰어서, 성능의 손실 없이 시간, 그리고 컴퓨팅 자원을 절약할 수 있습니다.
MoD의 작동 방식
컴퓨팅 예산의 책정 (Budgeting)
우선, 연구자들은 ‘컴퓨팅 예산 (Compute Budget)’이라고 부르는 고정된 컴퓨팅 자원의 한도를 정하는데, 이 한도는 처리하는 중간에 변경되지 않는 겁니다. 예를 들어서, MoD 트랜스포머는 각각의 층에서 최대로 토큰의 절반만을 처리하도록 용량을 설정할 수 있는데, MoD 모델은 토큰들 전반에 걸쳐서 이 컴퓨팅 한도를 똑똑하게 사용하는 방법을 학습하게 됩니다.라우팅
전통적인 트랜스포머에서는 모든 토큰이 모든 층 (또는 블록)을 통과하면서 처리가 되고, 셀프 어텐션 (Self-Attention)과 MLP (다층 퍼셉트론; Multi-Layer Perceptron)의 조합을 사용합니다. 하지만 MoD 트랜스포머에서는 ‘라우터가 먼저 각각의 토큰을 평가하고 가중치를 할당해서, 각 토큰이 다음 중 어느 과정을 따라갈지 결정합니다:Full Computation (전체 연산; 셀프 어텐션과 MLP)을 수행합니다. 이건 ‘무거운’ 연산입니다.
‘잔차 연결 (Residual Connection)’이라고 부르는, 더 단순한 경로를 통과합니다. 이건 ‘무거운 연산’을 건너뛰면서 컴퓨팅 파워를 절약하는, ‘가벼운 연산’입니다.
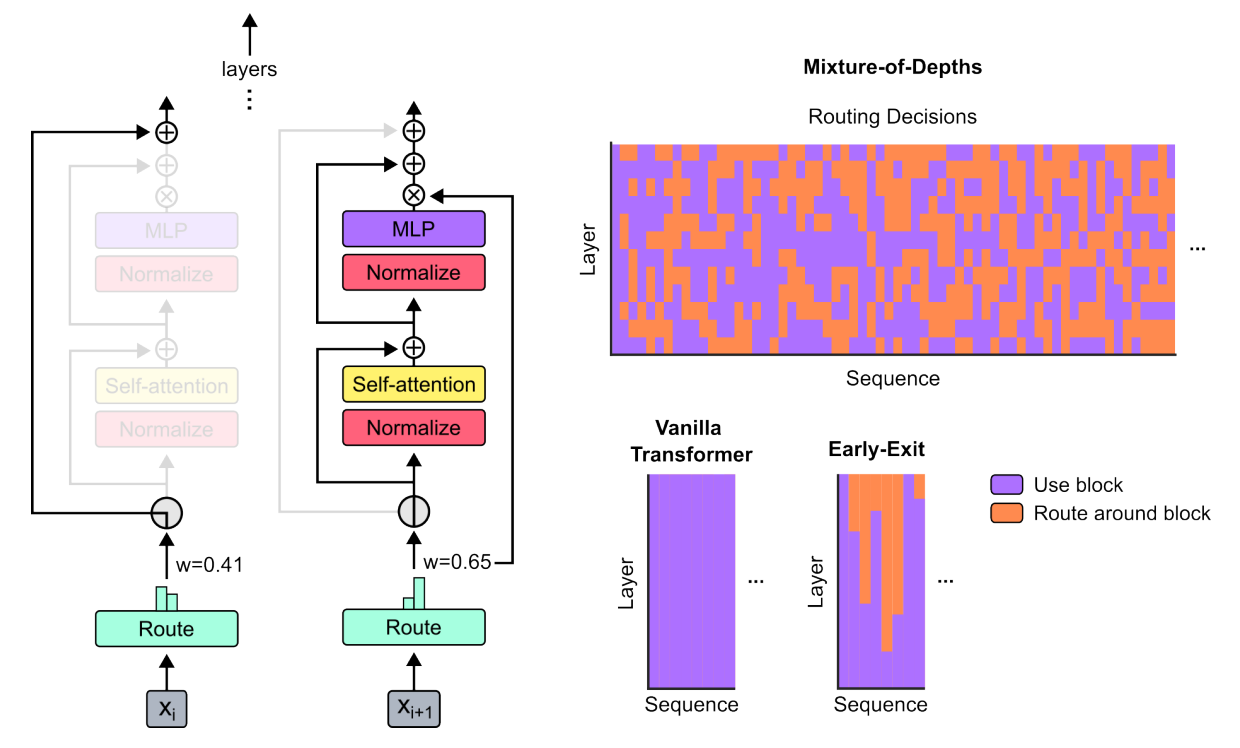
Image Credit: 오리지널 논문
라우팅 (Routing)에 대해서 좀 더 알아봅시다
MoD를 만든 연구자들은, 효율성과 성능 사이의 균형을 맞추기 위해서 ‘단일한 주 연산 경로 (Single Main Computation Path) 안에서 전문가 선택 라우팅 (Expert-Choice Routing)’을 사용하라고 제안하는데요. 말이 좀 어렵죠? 이 작동 방식은 다음과 같습니다:
각각의 블록에서, MoD 트랜스포머는 라우터가 할당한 가중치를 기반으로 ‘전체 연산 (Full Computation)’을 수행할 고정된 수의 토큰 (상위-k개)을 선택합니다. 이 방법으로는 가장 필수적인 토큰들만 처리하는 방식으로 MoD가 컴퓨팅 파워를 절약하는 것이죠.
위 선택의 결과, 시퀀스의 전체 토큰 수보다 ‘전체 연산’이 필요한 토큰 수가 적다면, 그 나머지는 ‘제외’되거나 처리를 ‘가볍게’ 해서 자원을 절약합니다.
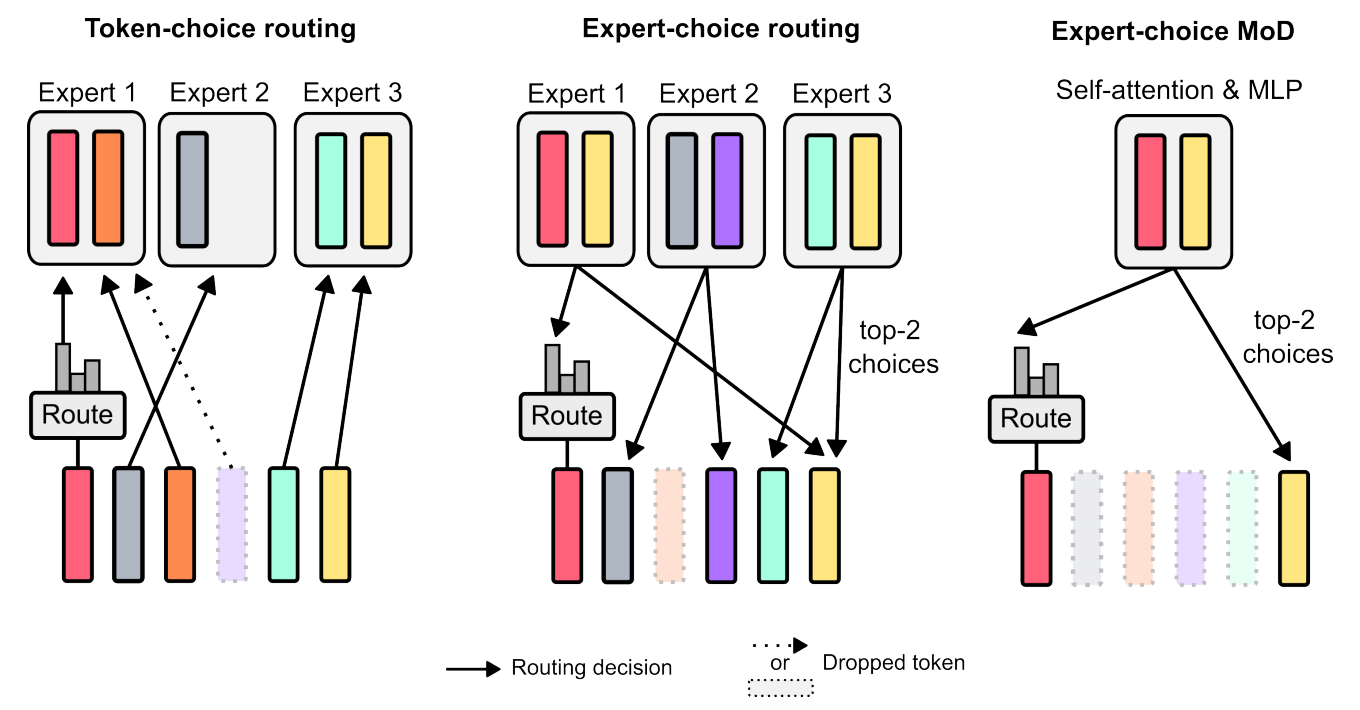
Image Credit: 오리지널 논문
이렇게 ‘단일 경로 설정’을 활용하면 MoD는 우선순위가 높은 토큰만을 ‘전체 연산’ 단계로 보내서 ‘처리 부하 (FLOPs로 측정)’를 줄일 수 있게 됩니다. 결국, MoD는 연산의 부하는 일관되게 유지하면서도 각각의 층에서 어떤 토큰에 대해서 더 ‘깊은’ 처리를 할지 다이나믹하게 선택하니, 트랜스포머의 구조를 변경하지 않고서도 단지 층을 통과하는 토큰에 대한 선택만 바뀌는 셈이죠.
다시 한 번 정리하면, 무거운 연산 경로를 택하는 토큰의 수를 제한해서, MoD는 연산의 요구량과 모델의 효과성 간에 균형을 맞춥니다. 예를 들어, 토큰의 절반만 이 집중적인 경로를 타게 된다면, Self-Attention 연산을 하는데 최대 75% 적은 전력만으로도 할 수 있습니다.
핵심 아이디어는 ‘균형’입니다: 모든 토큰이 연산이 많은 경로를 택한다면 MoD는 표준 트랜스포머처럼 작동할 것이고, 모든 토큰이 가벼운 경로를 택한다면 더 빠르지만 덜 정확할 겁니다.
또 잊지 말아야 할 중요한 세부사항은, 특정 부분에만 선택적 토큰 처리를 적용하는 MoE 접근방식과는 다르게, MoD는 순방향 층 (계산을 수행하는)과 어텐션 메커니즘 (문맥에서 단어들이 서로 어떻게 관련되는지 결정하는) 모두에 이 방식을 적용한다는 겁니다. 따라서 MoD는 어떤 토큰이 업데이트될지 뿐만 아니라 모델에서 다른 토큰들이 어떤 토큰을 ‘볼’ 것인지도 결정해서, 입력의 필수적인 부분에만 집중하도록 도와줍니다.
MoD의 성능과 장점
MoD의 성능은 어떤가?
최적화 구성을 찾아내기 위해서, 연산 예산을 다양한 수치로 고정해 놓은 상태에서 MoD 모델을 훈련시켜 봤는데요 - 그래서 결국, MoD 모델은 표준 트랜스포머를 능가할 수 있었을까요?
실험 결과, MoD 트랜스포머는 파라미터 당 필요한 FLOP (부동소수점 연산)을 줄여줄 수 있고, 최고 수준의 모델들과 동등한 성능을 더 적은 파라미터로 달성할 수 있다는 것이 밝혀졌습니다.
연구진이 발견한 MoD 성능의 핵심 포인트는 다음과 같습니다:
MoD 모델은 최고의 베이스라인 모델과 동일한 수준의 성능에 도달했지만, 도달 속도는 최대 66% 더 빨랐습니다. 이런 속도 향상이 가능한 건 각 단계에 필요한 FLOP 수가 감소했기 때문입니다.
MoD 트랜스포머는 베이스라인 트랜스포머와 동일하거나 더 적은 FLOP으로도 더 낮은 손실(더 나은 정확도)을 달성할 수 있습니다.
일부 더 작은 크기의 MoD 모델들은 더 적은 파라미터를 사용하면서도 베이스라인 모델들만큼 좋은, 혹은 더 나은 성능을 보여주었습니다.
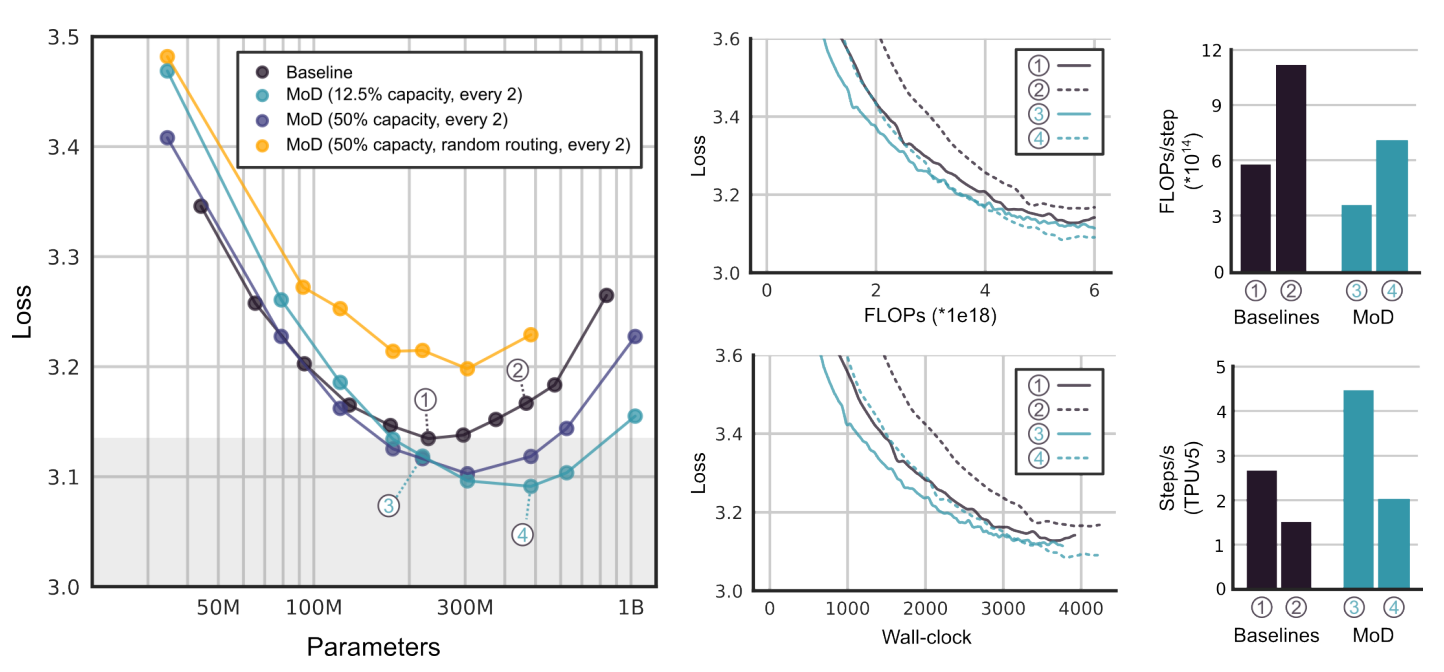
MoD 파라미터 튜닝. Image Credit: 오리지널 논문
결과적으로 연구진이 발견한 MoD 트랜스포머의 최적 설정 - 즉, 추가적인 연산 능력이 없이도 더 좋은 성능을 보여주는 구간 - 은 다음과 같습니다:
12.5% 블록 용량. 이건 각 블록 당 토큰의 12.5%만이 ‘전체 연산’을 거치게 되고, 나머지 87.5%는 더 빠른, 경량의 경로를 통과한다는 의미입니다.
모든 블록이 아니라, ‘한 블록씩 건너 뛰면서’ 라우팅 적용.
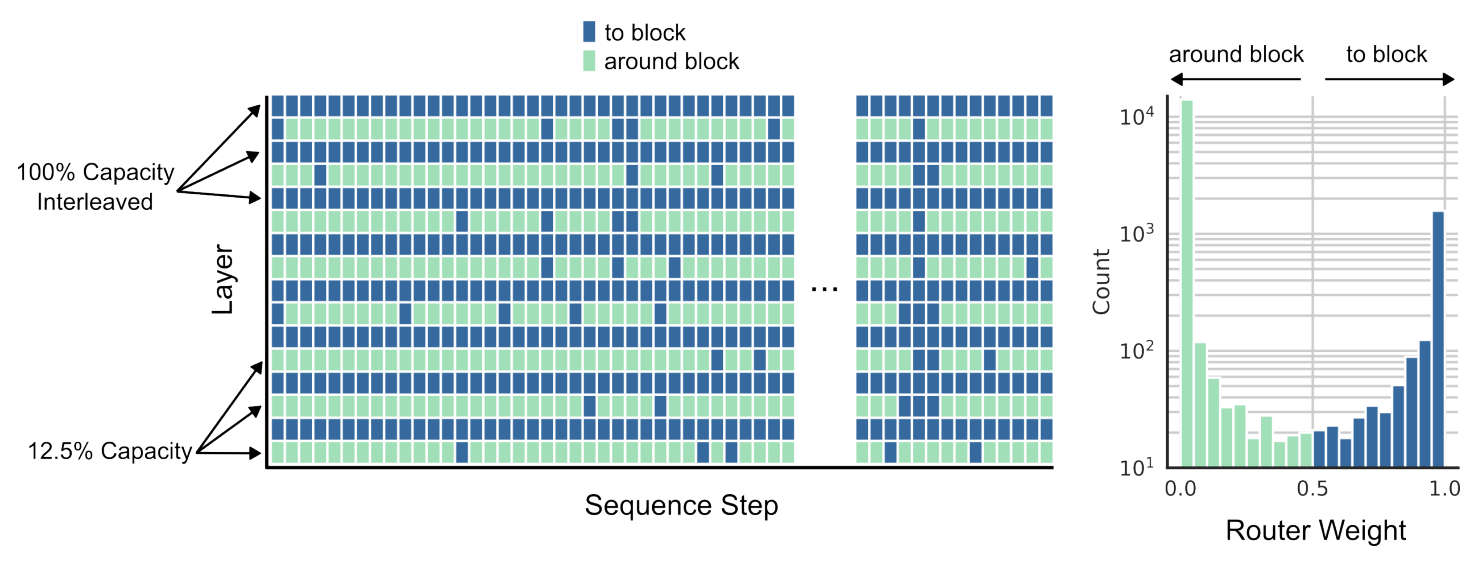
라우팅 분석. Image Credit: 오리지널 논문
자, 그럼 이제 MoD 기법의 장점과 흥미로운 점을 한 번 정리해 보죠.
MoD의 장점은?
MoD는 이런 장점들이 있습니다:
연산량 감소와 효율성 향상
일부 토큰들이 지름길 경로를 통해서 계산되고, ‘전문가 선택 (Expert-Choice)’ 라우팅으로 트랜스포머가 필수적인 토큰에만 집중할 수 있기 때문에, MoD 트랜스포머는 컴퓨팅 파워를 절약할 수 있습니다.더 빠른 속도
각 단계에 필요한 FLOPs(부동소수점 연산) 수가 감소, 속도가 향상됩니다. 최적화된 설정으로 MoD 모델은 데이터를 훨씬 더 빠르게 처리하면서도 베이스라인 모델과 동등한 성능을 달성할 수 있습니다.정확도
MoD 트랜스포머는 베이스라인 모델보다 더 많은 파라미터를 가지고도 손실을 더 낮게 만들 수 있습니다.
또 다른 중요한 점 하나는, MoD 트랜스포머를 ‘성능’과 ‘속도’ 중 하나에 맞춰 파인튜징할 수 있다는 건데요:
성능에 초점을 맞출 경우에는, MoD 트랜스포머는 표준 트랜스포머보다 약간 더 나은 예측 정확도를 달성할 수 있습니다. 고성능 MoD 모델은 동일한 양의 컴퓨팅 리소스(FLOPs)를 사용하면서도 표준 트랜스포머 대비 최대 1.5%의 정확도 향상을 달성할 수 있습니다.
속도에 초점을 맞출 경우에는, MoD 트랜스포머는 더 적은 FLOPs를 사용하면서도 비슷한 예측 정확도를 유지하면서 단계 당 최대 50% 더 빠르게 데이터를 처리할 수 있습니다.
MoD의 과제와 그 해결방향
뭐, 좋은 점만 있기야 하겠어요? MoD가 유망한 기법이기는 하지만, 여전히 몇 가지 문제점들이 있습니다:
높은 학습 비용
라우터들과 함께 전체 모델을 학습시켜야 하기 때문에 MoD 모델의 학습 비용이 많이 듭니다.중요한 레이어를 건너뛸 위험
때때로 중요한 레이어들을 건너뛸 수 있을 텐데, 그렇게 되면 모델 성능이 저하될 가능성이 있죠.하드웨어 호환성 문제
다이나믹한 연산이 필요한 MoD 모델은 정적인 연산 그래프와 고정된 메모리 요구사항 하에서 가장 좋은 성능을 보이는 현재의 하드웨어와 완벽하게 맞지 않을 수 있습니다.
그렇지만 역시, 이런 문제들을 해결하는 데 도움이 되는 몇 가지 방법들이 이미 있기는 합니다.
MoD가 가진 문제들의 해결책
메릴랜드 대학교와 텐센트 AI 연구소의 연구자들이 두 가지 새로운 방법을 제안했는데요:
라우터 튜닝
전체 모델을 학습시키는 대신, 더 작은 데이터셋으로 라우터 네트워크만 파인튜닝합니다. 이 접근법은 어떤 레이어를 건너뛸지 제어하는 모델의 더 작은 부분에만 집중해서 학습 비용을 줄입니다.마인드스킵 (MindSkip; 다이나믹한 깊이를 가진 어텐션)
‘마인드스킵’은 중요한 레이어들을 건너뛰지 않도록 선택적으로 어텐션을 적용, 효율성을 개선하면서도 모델 성능은 높은 수준으로 유지합니다. 필수적이지 않은 레이어만 건너뜁니다.
실험을 해 본 결과, 이런 해결책들로 다음과 같은 성과를 달성했다고 하네요:
효율적인 레이어 스킵으로 21% 더 빠른 처리 속도 달성
성능이 단 0.2%만 감소해서, 계산 상의 이점을 고려하면 매우 작은 트레이드오프 달성
두 가지를 합쳐보다: MoDE (Mixture-of-Depths-and-Experts)
자, 그럼 하나만 더 생각해 볼까요? 만약에, 이 MoD 기법을 기존의 MoE 기법과 결합해 보면 어떨까요? MoD 기법을 개발하는 과정에서 구글 딥마인드, 캐나다 몬트리올의 맥길 대학교, 캐나다 몬트리올의 MILA 연구자들은 이런 MoD+MoE 조합도 테스트를 해 보고 싶었고, 그래서 두 가지 기법의 장점을 모두 활용해 보자는 목표로 MoDE (Mixture-of-Depths-and-Experts) 모델을 만들었습니다.
MoDE 모델의 두 가지 변형 형태를 테스트했는데요:
단계별 (Staged) MoDE
먼저 MoD를 구현한 다음 MoE를 적용합니다. 다시 말해서, Self-Attention 단계 이전에 토큰들의 경로를 지정, 가능한 경우에는 토큰들이 이 단계를 건너뛸 수 있게 합니다.통합 (Integrated) MoDE: MoD 라우팅을 각 블록에서 표준 MLP Experts와 함께 ‘No-Op (No Operation)’ 전문가들 - 이건 ‘가벼운’ 경로겠죠 - 과 결합합니다.
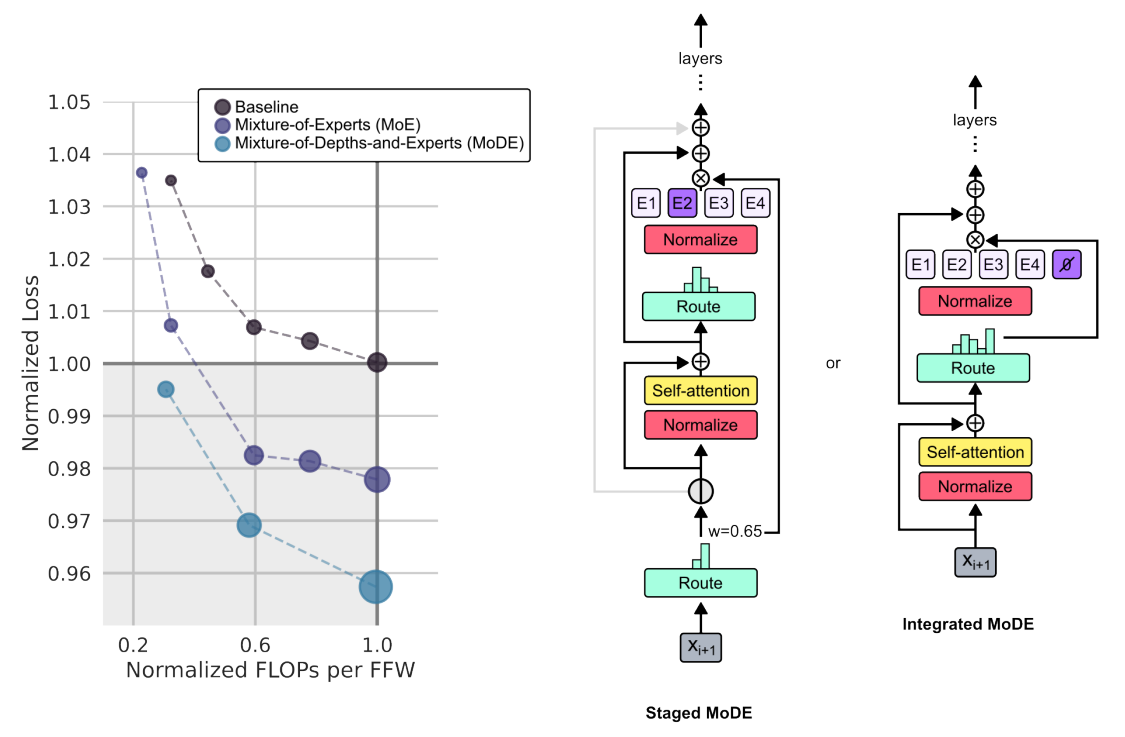
Image Credit: 오리지널 논문
이 두 가지 변형 형태의 MoDE 모델은 각각 다음과 같은 장점을 가지고 있습니다:
단계별 (Staged) MoDE는 Self-Attention 단계를 건너뛸 수 있기 때문에 더 많은 연산량을 절약할 수 있습니다.
통합 (Integrated) MoDE는 라우팅을 단순화하고 전통적인 MoE 모델보다 더 나은 성능을 보여줍니다. 여기서 토큰들은 용량 제한 때문에 수동적으로 제외되는 게 아니라, 더 단순한 ‘잔차 경로’를 능동적으로 선택하는 것을 학습합니다.
맺으며
AI의 지속 가능한 발전을 위해서, 컴퓨팅 자원을 효율적으로 사용하는 것은 필수적인 결정 요소입니다.
MoD, 그리고 MoD와 MoE를 결합한 MoDE 기법 모두, 처리 속도는 높이면서 모델의 계산 효율성과 성능을 향상시킬 수는 없을까 하는 연구자들의 고민의 결과입니다. MoD는 트랜스포머를 ‘더 포괄적이고 합리적으로 바라볼 수 있는 선택지’를 제공해 주고, MoD의 장점과 MoE의 장점을 결합한 MoDE 역시 높은 성능을 유지하면서도 모델을 단순화하는 데 특히 큰 가능성을 보여주고 있다고 판단됩니다.
보너스: 참고 자료와 소스 링크
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!