


글을 시작하며
오디오 - 음성, 소리 등 - 는 AI 모델이 다루는 텍스트, 이미지, 동영상 등에 못지 않게 중요한 데이터 유형인데요. 보통은 그렇게 항상 주목하게 되는 영역은 아니지만, 정말 중요하다고 생각합니다.
오늘은, 오픈AI에서 2022년 9월 처음 공개한 위스퍼 (Whisper) 모델 기반의 ASR (Automatic Speech Recognition)에 대해서 좀 살펴볼까 합니다. ASR은 말 그대로 ‘구어 (口語)를 자동으로 텍스트로 변환해 주도록’ 설계된 시스템인데요, 보통의 경우에는 다운스트림에서 특정한 작업을 하려면 파인튜닝이 필요합니다. 그런데, 위스퍼 모델은 다국어가 가능한 오픈소스 모델로 공개한데다가 ‘전사 (轉寫; Transcription)’와 ‘번역 (飜譯; Translation)’ 작업을 추가적으로 튜닝하지 않고도 할 수 있는 모델로, 앞서 이야기한 기존의 ASR의 틀을 깬 모델이라고 할 수 있습니다.
아시다시피 오픈AI는 대부분의 고도화된 모델을 공개하지 않고 독점적으로 관리하는 회사인데, 위스퍼 모델만은 2022년부터 예외적으로 오픈소스로 공개하고 있습니다. 2024년 현재 최신 버전인 V3 Turbo는 이전 모델 large-v3보다도 속도가 8배 빠르고, 클라우드 서버 및 로컬에서도 실행할 수 있는데 동시에 비슷한 수준의 정확도를 유지하는 것으로 나타나, 큰 관심을 받고 있습니다.
자, 위스퍼가 어떻게 만들어졌는지, 왜 그렇게 다양한 음성인식 작업을 처리하는데 효율적일 수 있는지 한 번 살펴보겠습니다.
이 글은 아래 목차로 구성되어 있습니다:
보통의 음성인식 모델이 가진 한계
‘음성인식 (Speech Recognition)’ 영역은 사실 그 연원이 꽤 오래 된 기술 분야라고 할 수 있을 텐데요. 최근에 와서 음성인식 분야의 중요한 변화 또는 발전 방향이라고 하면, ‘레이블 - 정답지 - 없이 원시 오디오 (Raw Audio)만 가지고 학습을 하는 비지도 방식의 사전 학습 방법’이라고 할 수 있을 겁니다.
그렇지만, 이렇게 만들어진 모델도 여전히 특정한 작업을 하려면 후공정으로 파인튜닝을 해야 하죠. 그리고 당연히 모델이 트레이닝 데이터에 고유한 패턴을 학습하는 바람에, 새로운 데이터가 들어왔을 때 여전히 조금 이상한 결과를 만들어내거나 실수를 할 위험도 있구요.
‘인코더’ 분야는 많이 개선되었지만, 그래도 ‘파인튜닝을 해야 한다는 것’ 그리고 약한 ‘디코더’의 한계 등은 끊임없이 모델의 성능에 영향을 미치고 있습니다. 물론, 이상적인 세상에서라면 계속해서 필요에 따라 조정을 하지 않아도 음성인식 모델이 다양한 환경에서 잘 작동해야겠죠 - 이런 목표를 가지고 다수의 데이터셋으로 ‘지도 학습’을 하는 기법이 좀 더 일관된 결과를 보여주기도 했지만, 현실적으로 지도 학습을 위한 고품질 데이터의 양은 너무 적구요.
그렇다면, 특별히 파인튜닝을 하지 않아도, 여러 가지 언어로 음성인식을 할 때 모델이 잘 작동할 수 있는 방법이 있다면 너무 좋겠죠?
위스퍼 모델의 등장, 그 이야기

위스퍼 모델의 경우, 오픈AI는 대규모의 ‘약한 지도학습 (Weak Supervision)’ 방식으로 음성인식 시스템을 트레이닝합니다. 이 시스템은, 음성인식 뿐 아니라 번역 작업, 또 원래의 언어로 음성을 텍스트로 전사하거나 영어로 번역하는 작업, 음성 활동의 감지 작업, 언어 식별 작업 등 다양한 작업을 하도록 설계되었습니다.
위스퍼 모델은 그 크기와 기능이 따라서 9가지 종류가 있는데요:
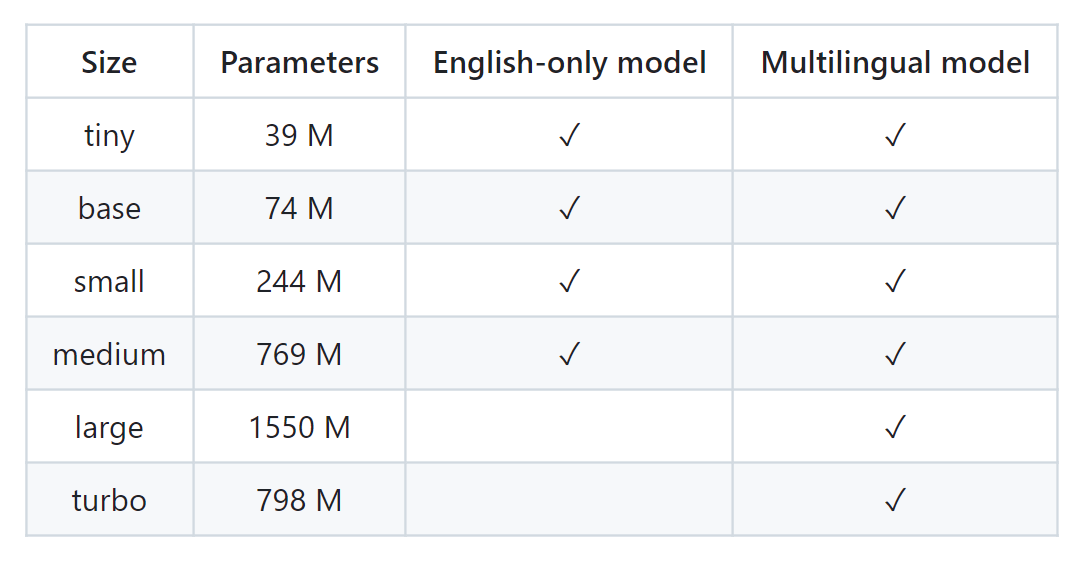
Image Credit: 오픈AI 위스퍼 모델 카드
위스퍼 모델의 초기 버전은 다음과 같은 트레이닝 데이터를 사용했습니다:
680,000시간에 해당하는, 레이블이 지정된 오디오 데이터
그 중 117,000시간에 해당하는 데이터는 96개 언어를 포함
그리고 125,000시간 정도의 번역 데이터
최신의 위스퍼 모델, Whisper large-v3-turbo는 인터넷에서 수집한 680,000시간의 오디오 데이터, 그리고 그에 해당하는 전사 (轉寫) 데이터를 가지고 트레이닝했는데, 데이터의 구성은 아래와 같습니다:
438,000시간은 영어 오디오와 일치하는 영어 전사 (轉寫)본,
126,000시간(약 18%)은 非 영어 오디오와 그에 해당하는 영어 전사 (轉寫)본
117,000시간(약 17%)은 非 영어 오디오와 해당하는 非 영어 언어의 전사 (轉寫)본
非 영어 데이터에 98개의 언어가 있으니, 위스퍼 모델은 총 99개 언어를 처리할 수 있는 셈이네요.
2022년 9월 출시되기는 했지만, 2024년 지금 더 큰 유명세를 얻고 있는 위스퍼 모델. 우선 위스퍼 모델 출시 타임라인을 한 번 살펴보겠습니다:

위스퍼 모델 출시 타임라인
2024년 9월 출시된 Whisper large-v3-turbo는 large-v3 모델의 축소된 버전으로, 디코더 레이어 수가 32개에서 4개로 훨씬 더 적은데, 이 때문에 속도와 효율성이 높아지죠. 위스퍼는 완전한 오픈소스 모델로 허깅페이스를 통해서 브라우저에서 실행할 수 있는데, (오픈AI의 주장에 따르면) 위스퍼의 오픈소스 버전과 API 버전은 동일하지만 API가 최적화된 프로세스를 제공할 뿐 이라고 합니다.
위스퍼가 2022년보다 지금 더 인기가 많고 유명세를 타는 이유는 뭘까요? 몇 가지 생각해 볼 수 있는데요.
첫번째로는, 무엇보다도 오픈AI가 전세계 AI 영역의 선도 주자로 엄청난 성장을 지난 2년간 했잖아요? 당연히 위스퍼를 포함한 오픈AI가 하는 모든 것에 더 많은 관심이 집중되는 건 어찌보면 당연하다고 하겠구요.
두번째로는, 훌륭한 장점을 가진 음성인식 모델인 위스퍼가 ‘완전한 오픈소스’로 공개, 누구나 접근할 수 있게 되면서 더 많은 사람들이 관심을 갖고 사용하게 된 것도 있을 것 같습니다.
세번째로는, 아마 이게 가장 근본적이면서도 명백한 이유일 텐데요, 위스퍼의 업데이트 버전이 모델의 초기 버전 대비 훨씬 더 나은 성능, 기능을 보여주고 있죠.
위스퍼는 어떻게 작동하고 어느 정도의 성능을 보여주나?
학계와 업계에서, ‘인코더-디코더 트랜스포머 아키텍처’의 확장성 (Scalability)는 이미 입증된 바 있죠 - 그래서 오픈AI는 위스퍼 모델을 구축할 때 이 아키텍처를 선택했습니다. 확장성은 대규모의 Weak Supervision 접근 방식을 활용할 때 매우 중요한 요소죠.
모델 아키텍처를 한 번 살펴보도록 하겠습니다.
위스퍼 아키텍처
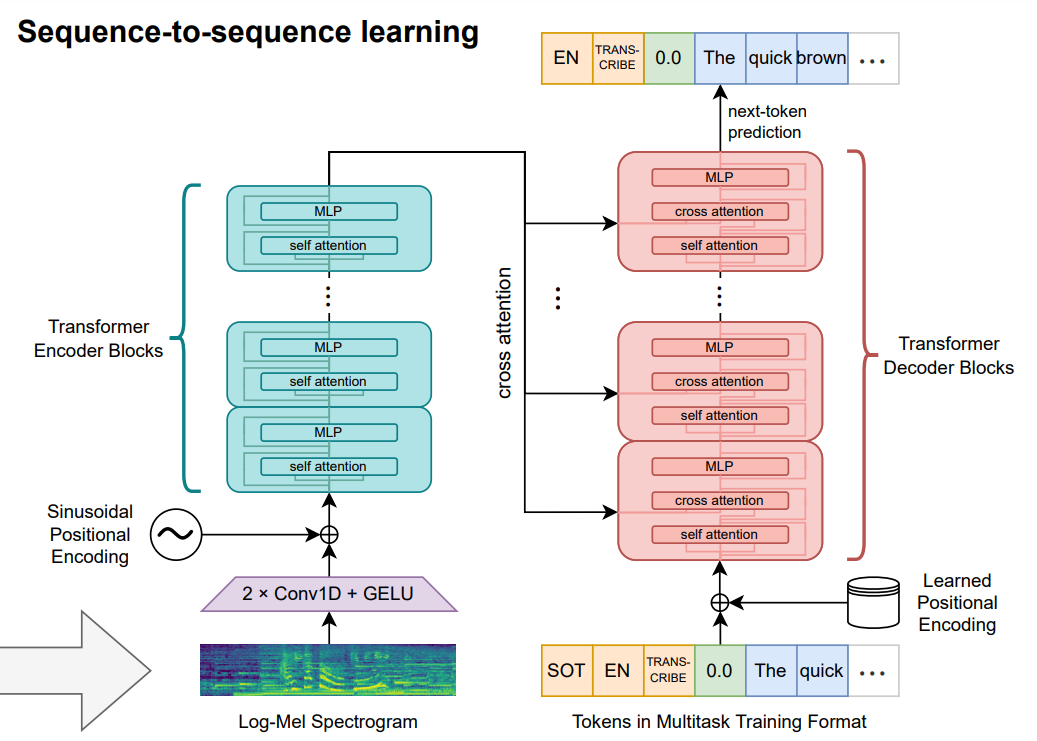
Image Credit: 위스퍼 아키텍처 (오리지널 논문)
원본 오디오 (Raw Audio)를 Mel Spectrogram (멜 스펙트로그램; 소리 파형을 사람이 들을 수 있는 범위로 줄인 Mel Scale - Melody Scale - 로 다운스케일한 후 그 파형을 그림으로 그린, 소리의 시각적 표현입니다)으로 처리, 정규화한 다음, 모델에 전달해서 트레이닝합니다. Whisper large-v3에서는 스펙트로그램 입력에 128개의 ‘Mel frequency bins’를 사용합니다.
인코더는 오디오의 특성 (Features)을 여러 계층의 변환 (Transformation)을 거쳐서 처리합니다.
디코더는 토큰을 사용해서 전사 (轉寫; Transcription) 결과값을 예측합니다.
텍스트의 처리를 위해서, GPT-2 모델을 기반으로 한 바이트 레벨 토크나이저를 사용하는데, 다국어를 처리할 수 있도록 조정을 거칩니다.
멀티태스킹 셋업
멀티태스크 모델을 만들기 위해서, 연구자들은 음성처리 파이프라인을 여러 가지 구성요소로 분할하는 대신 전체 파이프라인을 단순화하는 방식을 택했습니다. 이런 멀티태스킹 셋업은 전체 시스템을 더 효율적으로 만들 뿐 아니라 관리도 쉽고, 결과적으로 위스퍼 모델이 전사, 번역, 음성 활동 인지, 언어 감지 등 다양한 작업을 부가적인 처리 없이도 할 수 있도록 해 줍니다. 그렇다면, 연구자들은 어떻게 모든 작업을 하나의 모델로 할 수 있도록 구현했을까요?
바로 그 비밀은, ‘토큰’에 있습니다. 모델이 ‘마커 (Markers)’라고 하는 특별한 토큰을 전달받아서, 어떤 작업을 수행할지 지시를 받는 거죠. 그리고 이 토큰들은 입력의 일부입니다.
아래 그림에 이 작동 방식이 간략히 설명되어 있습니다:
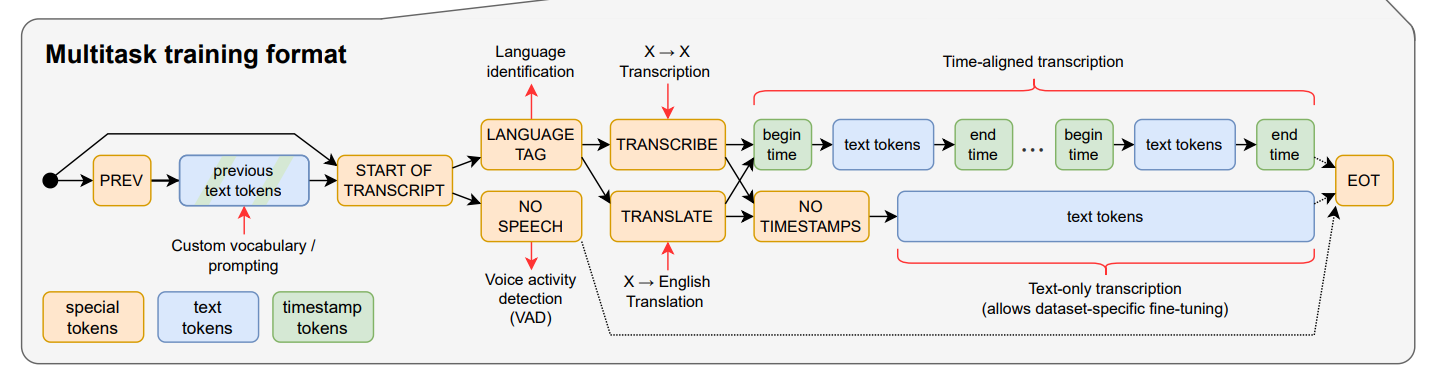
Image Credit: 오리지널 논문
언어 감지: 위스퍼는, 먼저 누군가 말하고 있는 언어를 감지하는 것부터 시작하는데, 99개 각각의 언어마다 독특한 토큰을 사용합니다.
작업 선택: 그 다음에, 토큰을 사용해서 음성을 전사 (轉寫; Transcription)할지, 번역 (飜譯; Translation)할지 등을 결정합니다.
타임스탬프: 만약 필요한 경우, 모델이 각각 말해진 단어의 시작 및 종료 시간을 예측하고, 각 텍스트의 앞뒤에 시간 마커를 추가합니다.
“음성 없음” 토큰: 만일 오디오에 음성이 없다면, 모델은 “<|nospeech|>” 토큰을 예측합니다. 이렇게 해당 오디오 부분에서 전사하거나 번역할 내용이 없다고 시스템에 알립니다.
작업 완료되면: 모델이 전사 또는 번역 작업의 끝을 표시하는 토큰을 추가합니다.
자, 그럼 이렇게 다양한 작업을 처리할 때 위스퍼 모델이 보여주는 성능을 한 번 확인해 볼까요?
위스퍼의 성능
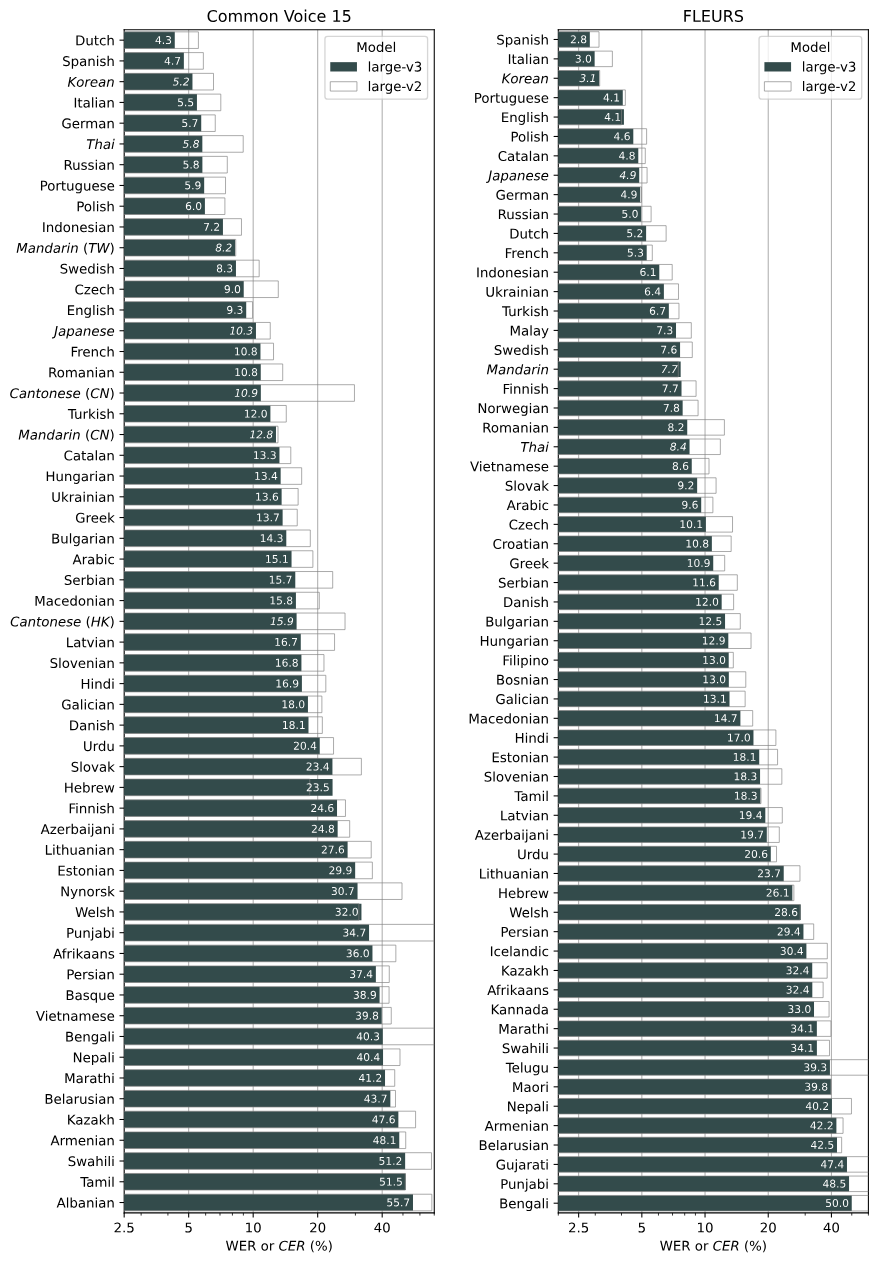
음성인식 시스템의 성능이라는 건 보통 WER (Word Error Rate; 단어 오류율)이라는 지표로 측정하는데요. 아래에 보여드릴 결과는 Whisper large-v2에 대한 분석에서 나온 거지만, large-v3 모델은 전체적으로 다양한 언어에서 향상된 성능을 보여주고, Whisper large-v2에 비해서 10%~20% 정도 오류가 적습니다.
영어 음성인식: 위스퍼 모델을 LibriSpeech 벤치마크에서 테스트한 결과 WER가 2.5%로 경쟁 모델 대비 비슷한 수준이라고 할 수 있지만, 다른 데이터셋에서는 훨씬 더 좋은 성능을 보여줬습니다. 이건 위스퍼 모델의 ‘일반화 (Generalization)’ 능력이 아주 좋다는 것을 시사합니다. 그리고 위스퍼는 OOD (Out-of-Distribution) 작업 - 트레이닝한 데이터와 패턴이 다른 데이터를 사용하는 것 - 에서 뛰어난 성능을 보여줬는데, 다양한 음성 인식 데이터셋에서 경쟁 모델 대비 평균 55.2% 정도 적은 오류를 나타냈습니다.
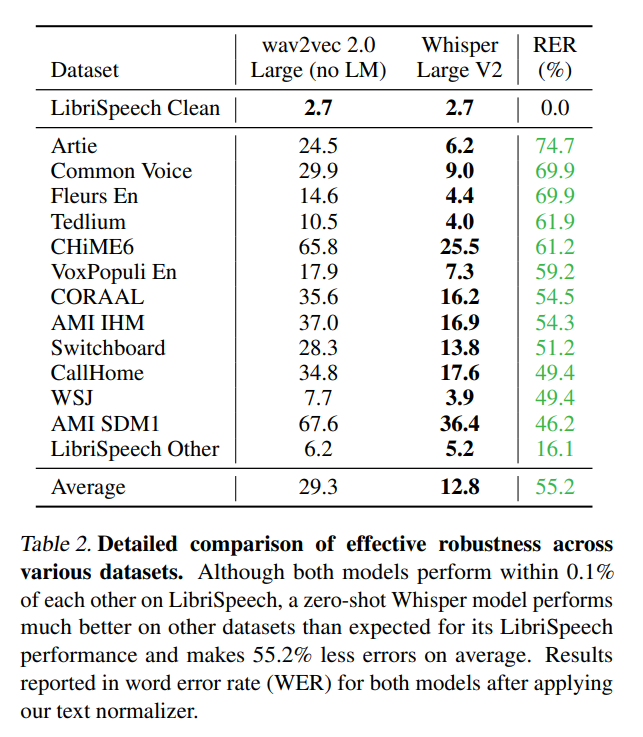
Image Credit: 오리지널 논문
다국어 음성인식: 위스퍼는 Zero-shot 평가에서 XLS-R과 mSLAM 같은 모델들을 능가하는 성능을 보여주는데, 특히 다국어 LibriSpeech (MLS)와 VoxPopuli에서 두각을 나타냅니다. 그렇지만 언어에 따라서 성능에 차이는 있는데, 히브리어, 중국어, 텔루구어, 한국어 같은 언어에서는 고유한 문자 체계나 언어적 차이 때문에 인상적인 성능을 보여주지 못하고 있습니다.
Image Credit: 오픈AI 위스퍼 깃허브
음성 번역: 위스퍼는 CoVoST2에서 기존 기록을 갈아치우는 최고 성능을 달성했고, 특히 자원이 적은 언어에 대해서도 파인튜닝을 하지 않고도 강력한 성능을 보여줬습니다.
잡음에 대한 강건성 (Robustness): 위스퍼는 잡음이 있어도 일관적으로 좋은 성능을 보여줬습니다. 다른 모델들에 비해서, 시끄러운 환경 (예: 술집 소음)에서도 성능 저하가 덜 발생했습니다.
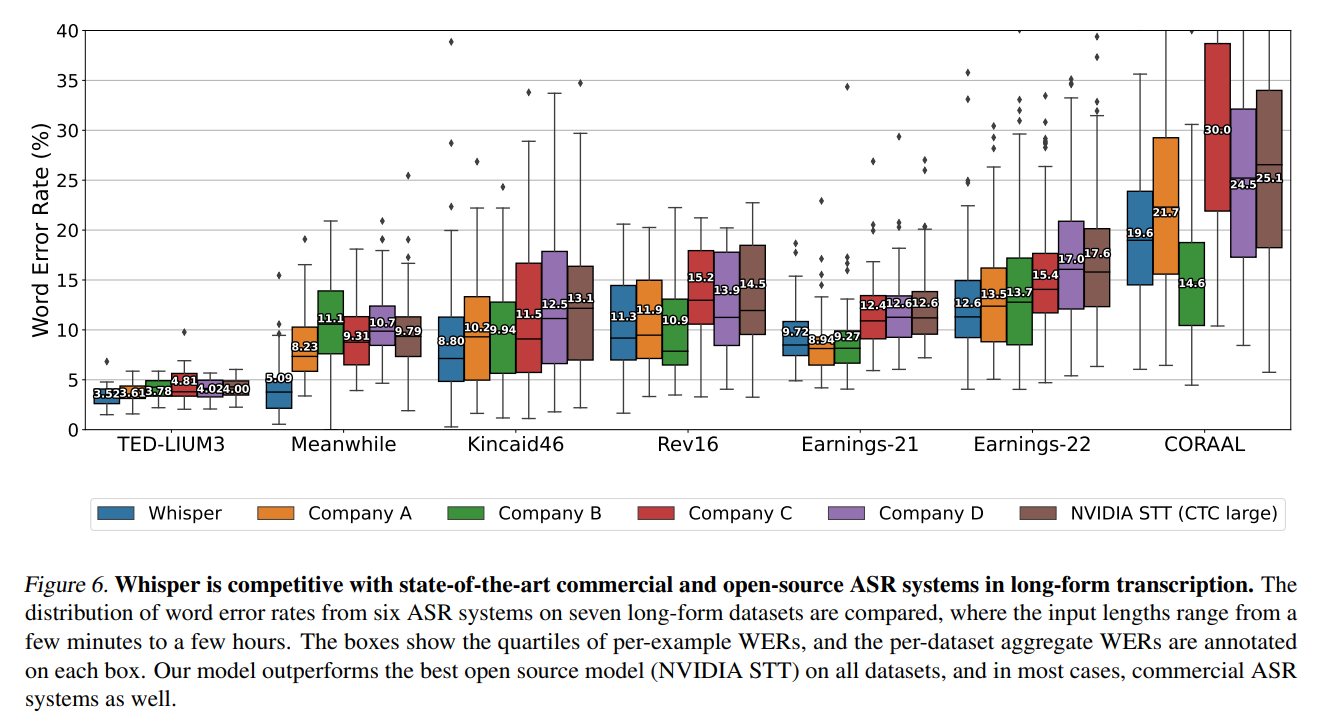
장문 전사 (Transcription): 위스퍼는 최신의 상용 시스템들과 비교해도 경쟁력있는 성능을 보여주고, 팟캐스트나 인터뷰 같은 긴 오디오 파일을 가지고도 우수한 성능을 발휘합니다.
Image Credit: 오리지널 논문
위스퍼의 장단점과 한계
위스퍼의 장점과 단점
성능을 이야기하면서 일부 언급했지만, 다시 한 번 위스퍼의 장점을 정리하자면 다음과 같습니다:
1. 다국어 지원 능력: 총 99개 언어에 대해서 음성인식 및 기타 다양한 작업을 할 수 있어서, 전세계적으로 활용 가능하다고 할 수 있는 다재다능한 모델입니다. 그리고 액센트나 전문 용어에 대해서도 강건성 (Robustness)을 보여줍니다.
2. Zero-shot 학습: 새로운 데이터셋에 대해서도 파인튜닝이 없이 우수한 음성인식 성능을 보여줍니다.
3. 잡음에 대한 강건성 (Robustness): 소음이 있는 환경에서도 정확도를 잘 유지합니다.
4. 멀티태스킹 기능: 하나의 모델에서 전사 (Transcription), 번역, 언어 식별 등의 작업을 정확하게 처리할 수 있습니다.
5. 확장성: 더 큰 데이터셋과 모델을 사용할수록 성능이 향상됩니다.
자, 단점이라고까지 하긴 뭐 하지만, 이슈가 될 법한 점들을 좀 이야기해 본다면:
위스퍼 (Whisper)는 CPU, GPU 모두에서 실행할 수 있습니다. CPU를 사용할 수는 있지만, 물론 Whisper Large V3 같은 대형 모델에서는 아주 느릴 수 있겠죠. GPU를 사용하면 전사 (Transcription) 속도가 많이 빨라지지만, 이것 역시 몇 가지 문제가 있어요 - 다수의 사용자들이 Whisper를 로컬에서 실행할 때, 특히 강력한 GPU를 장시간 사용하는 경우 시스템이 심각하게 과열된다는 보고가 있습니다. 과열 문제를 피하기 위해서 클라우드 옵션을 생각해 볼 수는 있겠습니다.
실질적인 관점에서 고려해 볼 만한 몇 가지 옵션으로, 허깅페이스의 WhisperWebGPU나, Whisper Large V3 Turbo 모델을 클라우드 기반으로 구현한 Groq이 있습니다. 속도로 유명한 만큼, Groq의 인프라는 아주 빠른 성능을 보여주고, 리얼타임 스피드의 216배 속도를 자랑합니다. 이 옵션은 ‘로컬에서 직접 하드웨어를 관리하기는 싫은데 빠른 속도는 필요한’ 경우에 괜찮은 선택지가 될 수 있겠죠 - Groq의 위스퍼 모델은 GroqCloud를 통해서 접근 가능합니다.
위스퍼의 한계
많은 부분 위스퍼가 다른 음성인식 모델과 그 접근 방법 대비 개선된 점을 보여주지만, 여전히 몇 가지 눈에 띄는 한계는 있습니다:
1. 환각: Weak Supervision 접근 방법으로 대규모 노이즈가 있는 데이터로 트레이닝한 위스퍼는, 때로 오디오에 없는 텍스트를 생성할 수도 있습니다. 이런 일은 ‘언어에 대한 지식’과 ‘전사 (轉寫; Transcription)’를 섞게 되기 때문에 발생하는데, 가끔 실제로 존재하지 않는 단어를 예측하기도 합니다.
2. ‘이븐하지 않은’ - 흑백요리사 한 번 패러디 해 봤습니다 ^.^; 언어 성능: 어쨌든 트레이닝 데이터의 제한이 더 많은, 자원이 적은 언어에서는 성능의 격차가 있고, 액센트, 방언, 인구 통계학적 그룹 (예: 성별, 인종, 나이)에 따라서 정확도가 들쭉날쭉할 수 있습니다. 그래서 일부 화자의 경우에는 단어 오류율이 높아질 수가 있어요.
3. 반복적인 텍스트 생성: Seq2seq 아키텍처 때문에, 모델이 반복적으로 같은 출력을 만들어낼 수가 있습니다. Beam 서치나 Temperature 스케쥴링 같은 기법을 사용하면 이 문제를 줄이는데 도움은 되겠지만, 궁극적인 해결책은 아닙니다.
맺으며
2022년 9월 최초로 공개 된 이후, 현재 Large-V3과 Large-V3-Turbo에 이르기까지 완전한 오픈소스로 공개하고 있는 오픈AI의 음성인식 모델 ‘위스퍼 (Whisper)’. 위스퍼는 ASR (Automatic Speech Recognition) 영역에서 중요한 진보를 만들어 온 모델로, 개인 개발자로부터 대기업에 이르기까지 폭넓은 사용자들이 접근해서 활용할 수 있습니다. 다국어 지원, 노이즈에 대한 복원력, 하나의 모델에서 여러 종류의 작업을 처리할 수 있는 능력은, 대부분의 ASR 모델이 특정한 작업을 위한 파인튜닝을 필요로 하는 현실을 볼 때, 아주 유의미하다고 하겠습니다.
물론, 위스퍼가 만들어낸 진보의 크기만큼 계속해서 부각되는, 그리고 변치 않는 ASR 기술과 시스템의 과제가 있습니다: 예를 들어, 언어 간 불균형한 성능 문제라든지, 반복적으로 같은 텍스트가 생성되는 간헐적인 문제라든지 하는 것들이요.
그렇지만 이런 한계에도 불구하고, 위스퍼는 음성 AI를 통해서 어떤 걸 할 수 있는지를 선도적으로 보여주는 모델이고, ‘음성인식’을 통해서 뭔가를 해 보겠다고 하면 꼭 검토해 볼 만한, 다재다능하고 효율적인 해결책을 제공합니다.
보너스: 자료 소스
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!