


글을 시작하며

축구선수 다니 올모
‘OLMoE’, 올모.
축구선수 ‘다니 올모’ 아닙니다 (죄송 ^.^;)
튜링 포스트 코리아에서 이전에 AI 101 에피소드 중 하나로 MoE 아키텍처에 대해서 말씀드린 적이 있는데요:

MoE 기법은, ‘확장 가능 (Scalable)한’ AI 시스템을 구축하게 해 주는 좋은 해결책 중 하나죠. 특정한 작업에 대해서 특화된 전문 모델과 네트워크의 파라미터 일부만 사용해서 ‘모델의 효율성을 높이고 비용을 낮추는’ 접근 방식입니다.
그런데, 대부분의 MoE 모델은 오픈소스가 아니라 ‘폐쇄형 (Closed)’ 모델이라는게 문제라면 문제거든요. 새로 등장한 OLMoE 모델은, 그냥 단순한 MoE보다도 더 효율적인 알고리즘, 더 적은 수의 파라미터를 통해서 모델의 운용에 드는 비용을 줄여줌으로써, 독점적/폐쇄적으로 개발, 운영되는 SOTA 모델과 완전히 개방된 오픈소스 모델 사이의 격차를 줄이고 오픈소스의 쓰임새를 더 확대하겠다는 목적을 가지고 등장했습니다.
Contextual AI의 Niklas Muennighoff는 9월 25일에 “이제 OMLoE는 Molmo 제품군의 일부로서 멀티모달 (MolmoE)이 되었다”고 이야기했는데요. Molmo는 앨런 AI 연구소 (AI2)에서 출시한 오픈소스 LMM (거대 멀티모달 모델) 제품군으로, Molmo-72B, Molmo-7B-D, Molmo-7B-O, MolmoE-1B의 네 가지 모델이 있습니다.
MolmoE-1B가 MoE 모델인 OLMoE-1B-7B가 베이스인 모델인데요. Molmo에 대해서는 별도로 한 번 다루도록 하고, 오늘은 OLMoE의 아이디어와 기능, 그리고 OLMoE가 AI 생태계와 커뮤니티에 어떤 기여를 할지에 대해서 집중적으로 살펴보겠습니다.
OLMoE의 ‘오픈소스’ 정신을 기념하는 의미에서, 이번 AI 101 에피소드는 ‘일주일’ 간의 블록을 걸지 않고 모든 구독자들님이 발행 즉시 전문을 보실 수 있습니다. ^.^
그래도, 프리미엄 플랜으로 업그레이드하신다면 튜링 포스트 코리아의 모든 컨텐츠를 앞으로도 제한없이 보실 수 있고, 튜링 포스트 코리아의 컨텐츠 제작에 큰 도움이 됩니다. 감사합니다!
이 글은 아래 목차로 구성되어 있습니다:
OLMoE가 착안한 아이디어
소위 말하는 ‘SOTA 퍼포먼스를 보여주는 프런티어 AI 모델’은, 트레이닝하고 배포하려면 엄청난 돈이 들어서 많은 경우 작은 기업이나 거기 속한 연구자들이 사용할 수 없는 경우가 많죠. 여기서 얘기하는 ‘전문가 혼합 (MoE; Mixture of Experts)’ 모델 아키텍처는, 레이어 당 다수의 전문가 네트워크를 갖고 있지만 한 번에 몇 개의 네트워크만 활성화하는 방식으로 효율성을 높입니다. 잘 알려진 모델들 중에는, 미스트랄의 Mixtral, 데이터브릭스의 DBRX, AI21 랩스의 Jamba, xAI의 Grok-1 등이 MoE 아키텍처를 활용하고 있습니다.
그런데, 거의 모든 MoE 모델은 공개되어 있지 않아서, AI 커뮤니티에서 경쟁력도 있고 비용 효율적인 MoE를 만드는데는 한계가 있습니다.
마침, 앨런 AI 연구소, Contextual AI, 워싱턴대, 프린스턴대 연구원들이, 뛰어난 성능을 갖춘 오픈소스 MoE 모델, OLMoE를 만들어서 공개했는데요. 이 친구들이 모델 학습에 사용한 가중치, 코드, 로그, 데이터 등을 모두 오픈소스로 공개했기 때문에, 누구든 이 모델의 작동 방식을 확인하고, 사용하고, 개선할 수 있습니다.
OLMoE의 작동 방식
고밀도 (Dense) AI 모델처럼 항상 대규모 연산을 하는 전체 네트워크를 사용하는 대신, MoE 모델인 OLMoE는 ‘전문가 (Expert)’라고 부르는 여러 개의 작은 연산 네트워크를 사용합니다. OLMoE의 가장 중요한 특징 중 하나는, 이 ‘전문가 네트워크’를 아주 높은 수준으로 고도화한다는 겁니다 - 예를 들어, 한 전문가 네트워크는 ‘언어 번역’ 작업만 전문으로 하고, 다른 전문가 네트워크는 ‘수학적 추론’만 전문으로 하는 식이죠.
어떤 단어, 입력이 들어와서 처리될 때마다, 전체 전문가 네트워크들 중에서 소수의 네트워크만 활성화되기 때문에 모델의 효율성이 높아지게 됩니다. 이 때, ‘라우터’라고 하는 모델의 일부 요소에서, 입력값의 특성에 따라서 각각의 작업에 사용할 전문가 네트워크를 결정하는데, 라우터는 확률을 기반으로 최적의 전문가 네트워크를 선택, 이들의 출력이 결합되면서 최종적인 결과값을 만들어냅니다.

Image Credit: OLMoE 아키텍처 (논문)
OLMoE는 얼마나 많은 ‘전문가 네트워크’와 ‘파라미터’를 사용하나?
MoE 모델에서는 ‘입력값에 따라 사용할 전문가 네트워크의 수’, ‘전문가 네트워크의 설계 방법’, ‘라우터가 전문가 네트워크를 선택하는 규칙’ 등이 중요한 결정 사항인데요.
OLMoE의 경우는, ‘효율성’과 ‘성능’의 균형을 잘 맞출 수 있는 최적의 활성 파라미터를 열심히 찾아서, 총 69억 개의 파라미터 중에서 각각의 입력값에 대해서 한 번에 사용되는 파라미터 수는 약 13억 개 정도로 정해져 있습니다. 그리고 각각 작업에 대해서 64개의 전문가 네트워크 중에 8개의 네트워크를 활성화해서 추론 작업을 수행합니다.
연구자들은 최적의 파라미터 숫자나 네트워크 숫자를 어떻게 구했을까?
위에 말씀드린 아주 구체적인 수치를 결정하기 위해서, 연구자들이 아주 광범위한 실험을 했다고 하는데, 실험을 하면서 ‘입력값 당 8개 미만의 전문가 네트워크를 활성화하면 결과값의 정확도가 떨어지고, 그보다 많은 전문가 네트워크를 활성화하면 계산 비용이 크게 증가’하는 패턴을 발견했다고 해요. 결국, 정확도 vs. 계산 효율성의 트레이드오프에서 최적의 균형점을 찾은 것이죠. 활성화할 전문가 네트워크를 선택할 때 사용하는 기술을 ‘토큰 기반 라우팅 (Token-based Routing)’이라고 부르는데, 이 때 학습된 라우터가 토큰을 삭제하지 않고 가장 관련성이 높은 전문가 네트워크들에 각 입력 토큰을 할당해서 모델 효율성을 극대화합니다.
그리고 여기서 멈추지 않고, ‘Dropless Token Choice Routing’ 기법이란 걸 통해서 모델 효율성을 한층 더 향상시키는데요. 이 기법은 하나의 전문가 네트워크에만 과부하가 걸리지 않으면서 각각의 입력값이 정보의 손실 없이 전문화된 네트워크들로 잘 처리되도록 하는 기법이라고 합니다. 이런 기법들을 혼합해서, OLMoE는 비슷한 크기의 고밀도 모델 대비 약 2배 빠른 속도로 학습하고, 비용 측면에서는 전체 파라미터 수가 훨씬 적은 모델과 비슷한 추론 비용을 소비합니다.
OLMoE를 개발한 연구자들은, 5조 개의 토큰으로 구성한 대규모 데이터셋으로 OLMoE를 사전 학습시키는 과정을 거쳐서, 전문가 네트워크들이 다양한 종류의 데이터에 충분히 노출되어 아주 높은 수준의 전문성을 확보할 수 있도록 조치했는데, 이 덕분에 활성 파라미터의 수를 크게 늘리지 않고도 좋은 성능을 얻을 수 있다고 합니다.
더불어, 트레이닝 과정 전반에 걸쳐서 모델의 안전성, 효율성을 보장하기 위해서 몇 가지 기법을 적용했는데요 - Load-balancing Loss (로드 밸런싱 손실)을 이용해서 모든 전문가 네트워크가 고르게 사용될 수 있도록 하고, Router Z-loss (라우터 Z-손실)을 적용해서 모델의 의사결정 상 불안정성을 줄이고 성능, 훈련의 일관성을 모두 개선했습니다.
이렇게 다양한 기법을 신중하게 적용해서, 총 69억 개의 파라미터와 13억 개의 활성 파라미터로 불필요한 계산 오버헤드 없이 아주 효율적이면서도 강력한 모델, OLMoE를 만들 수 있었습니다.
이제 몇 가지 그래프로 OLMoE의 성능을 확인해 보죠.
OLMoE-1B-7B의 성능은 어느 정도인가?
‘사전훈련 중’, ‘사전훈련 종료 후’, 그리고 ‘모델 조정 (Adaptation) 후’ 세 단계에서 OLMoE의 성능을 평가한 자료를 보면:
1. 사전훈련 중
OLMoE-1B-7B는 전반적으로 모든 작업에 걸쳐서 OLMo-7B 같은 고밀도의 모델을 포함한 다른 모델들보다 일관적으로 우수한 성능을 보여줍니다.
활성 파라미터가 13억 개에 불과하지만, 경쟁 모델보다 더 적은 연산 능력 (FLOPs)을 요구합니다.
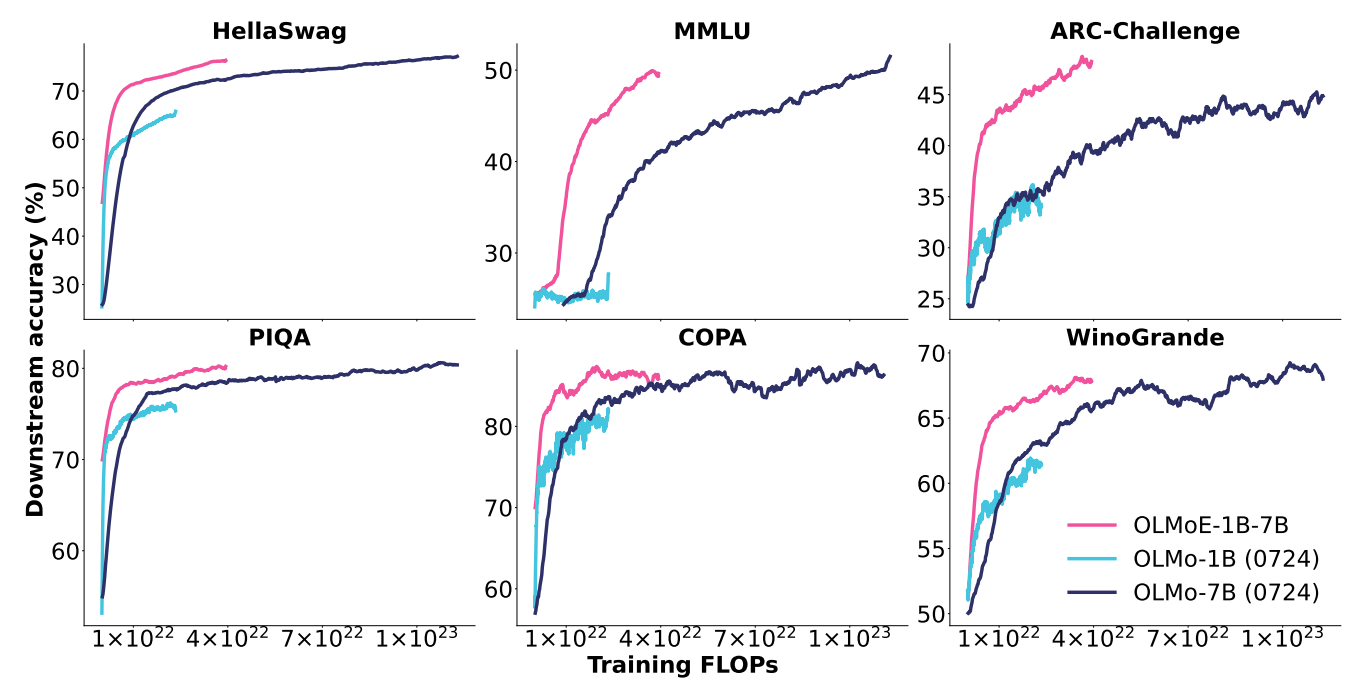
Image Credit: OLMoE 논문
2. 사전훈련 종료 후
파라미터가 20억 개 미만인 다른 모델과 비교했을 때 OLMoE-1B-7B의 성능이 더 뛰어납니다.
계산을 위한 예산 (Computational Budget)이 더 큰 모델의 경우는, Qwen1.5-3B-14B가 더 나은 성능을 보여주지만 OLMoE-1B-7B에 비해서 파라미터가 두 배 이상 많죠.
더 많은 수의 파라미터와 컴퓨팅 용량을 가진 Llama3.1-8B 같은 모델과 비교하면 OLMoE가 좀 부족한 모습을 보이는 것도 사실입니다.
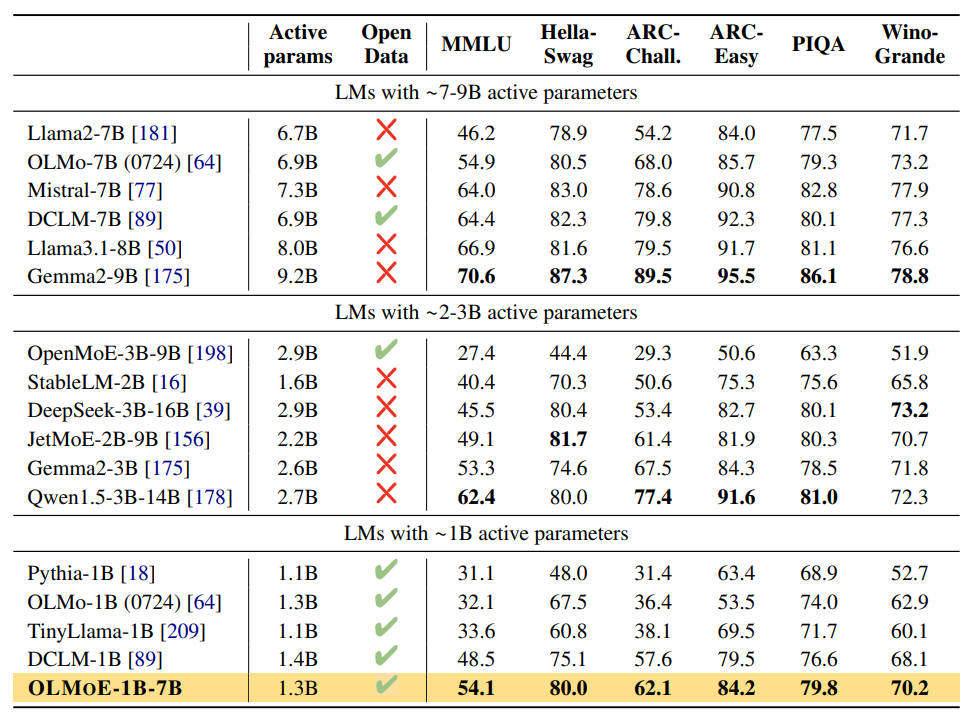
Image Credit: OLMoE 논문
3. 모델 조정 (Adaptation) 후
조정 (Adaptation)이라는 것에는 모델이 다운스트림에서 수행해야 하는 특정한 작업들 - 예를 들어서 코딩이라든가 수학적 추론 - 에 맞게 모델을 파인튜닝하는 작업이 포함됩니다. 이런 작업은 2단계 프로세스로 진행되는데요:
SFT (Supervised Fine-Tuning): 특정한 지시 작업에 잘 따르도록 모델을 튜닝
DPO (Direct Preference Optimization): 사용자와 잘 상호작용하도록 모델을 튜닝
OLMoE를 개발한 연구자들은 ‘코드’와 ‘수학’ 관련된 데이터들을 더 추가해서, GPT-4 같은 모델과 마찬가지로 이 영역에서 모델의 성능을 개선하도록 했습니다. 그 결과:
SFT가 특히 GSM8K 같은 작업에서 성능을 향상시키는데 도움을 주었습니다.
DPO 튜닝은 특히 AlpacaEval에서 높은 점수를 받는데 도움이 되었습니다.
튜닝된 버전, OLMoE-1B-7B-Instruct는 파라미터 수가 더 적지만 일부 작업에서는 Qwen1.5-3B-14B 같은 훨씬 더 큰 모델보다도 좋은 성능을 보여줍니다.

Image Credit: OLMoE 논문
OLMoE의 장점, 그리고 한계
우선, 지금 단계에서는 ‘OLMoE의 장점’을 정확히 판단해서 이게 왜 일반적인 MoE 아키텍처의 모델보다 더 나아진 버전인지 명확하게 정리해 보는게 의미가 있을 것 같습니다:
오픈소스: OLMoE는 완전한 오픈소스 모델로, 모든 사용자, 개발자가 OLMoE의 작업 프로세스에 접근할 수 있고, 연구용, 상업용 제한없이 활용할 수 있습니다.
높은 효율성과 비용 대비 효과: 위에서 여러 차례 이야기한대로, OLMoE에 필요한 컴퓨팅 파워 사용량이 적기 때문에, 고밀도 모델 대비 비용이 절감되고 효율성이 높습니다.
성능: OLMoE는 특별히 비용을 증가시키지 않고도 더 큰 규모의 모델과 경쟁할 수 있습니다. 표준적인 MoE도 물론 비슷하거나 더 높은 성능을 보여줄 수 있지만, 많은 경우에 더 큰 컴퓨팅 자원을 필요로 합니다.
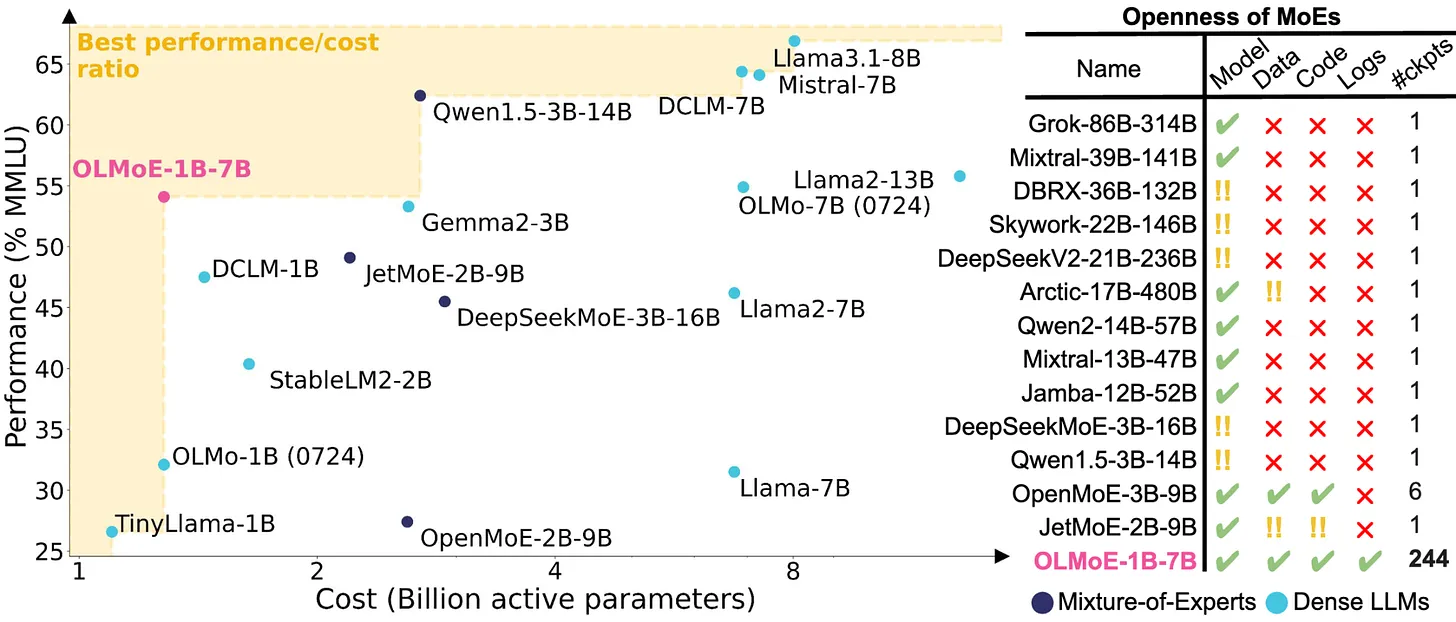
Image Credit: Nathan Lambert 블로그
물론, 몇 가지 단점이랄까 한계도 존재하죠 - 이 한계점들은 대부분 ‘복잡한 모델 아키텍처’ 때문에 나타나는 것들인데요:
라우팅의 복잡성: 전문가 네트워크로의 라우팅이 최적화가 잘 되지 않는다면, 추가적인 오버헤드가 생겨서 특정한 종류의 입력값에 대한 모델 성능이 저하될 수 있습니다.
메모리 요구사항: 총 69억 개의 파라미터는 꽤 상당한 메모리 자원을 필요로 합니다.
확장성 (Scalability) 문제: 현재의 OLMoE 구성은 상당히 효과적이지만, 규모가 커질수록 전문가 네트워크가 많아지면서 관리라든가 라우팅이 복잡해지고 확장성이 떨어질 수 있습니다.
데이터 종속성: OLMoE가 학습을 효과적으로 하려면 사이즈도 크고, 다양하면서 균형잡힌 데이터셋이 필요합니다. 데이터가 잘 큐레이션되지 않거나 도메인의 특성을 잘 반영하지 못하면, 모델의 성능이 저하될 수 있습니다.
맺으며
MoE를 기반으로 하는, 그보다 더 발전된 모델인 OLMoE는, MoE 아키텍처의 모든 장점을 누구나 활용할 수 있도록 하는 효율적이고 강력한 모델인데요. 게다가 ‘오픈소스’로 공개되어 있는 이 모델은, 여타 폐쇄형 모델과 동등하거나 더 나은 성능을 보여줍니다.
OLMoE는 ‘기술의 개발 과정과 그 결과물을 모두 투명하게 공개해서, 궁극적으로 더 훌륭하고 쓰임새도 많은 시스템을 만들겠다’는 철학이 현실화된 하나의 좋은 사례라고 할 수 있습니다. 다른 스타트업, 그리고 대학교들과 함께 이 프로젝트를 주도적으로 이끈 앨런 AI 연구소, ML 커뮤니티의 발전, 모델 개발의 민주화에 계속해서 헌신하고 있는 이 기관에 다시 한 번 찬사를 보냅니다.
OLMoE and the hidden simplicity in training better foundation models by Interconnects
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!