


알려드립니다:
지난 6월 말부터 약 1달 여 테스트 런을 해 온 ‘튜링포스트 코리아’가 금주부터 공식적으로 출발합니다. 과연 정기적으로 의미있는 기사와 의견을 여러분께 전달할 수 있을까 고민이 있었는데, 주 2~3회 리듬을 가져갈 수 있다고 판단하게 되었습니다. 테스트 런 기간동안 튜링포스트 코리아의 글을 읽어주신 많은 분들께 감사드리고, 앞으로도 많은 응원과 피드백, 주변에 소개 부탁드립니다. 뉴욕에서 발행하는 튜링포스트의 정책에 맞추어, 앞으로 일부 기사와 글은 유료 멤버십 가입자들께는 전체가 공개되고, 무료 가입하신 분들께는 일부가 공개될 예정입니다. 계속해서 AI 기술, 산업, 스타트업 등에 대한 의미있는 뉴스와 인사이트를 전달해 드리도록 하겠습니다.
금주부터는 매주 발행할 주간 다이제스트 FOD (Froth on the Daydream)에 실제 AI 업계 전문가들이 관심을 가지고 추천하는 2~3가지 AI 도구, 서비스, 앱 등을 소개할 예정입니다. 하루가 다르게 새로운 컨셉의 AI 도구들이 등장하고 있는 지금, 최전선의 전문가들이 사용해 보거나 관심있어하는 것들은 어떤 것인지 한 번 확인도 해 보시고 사용해 보세요! (스폰서/광고 아닙니다 ㅎㅎ)
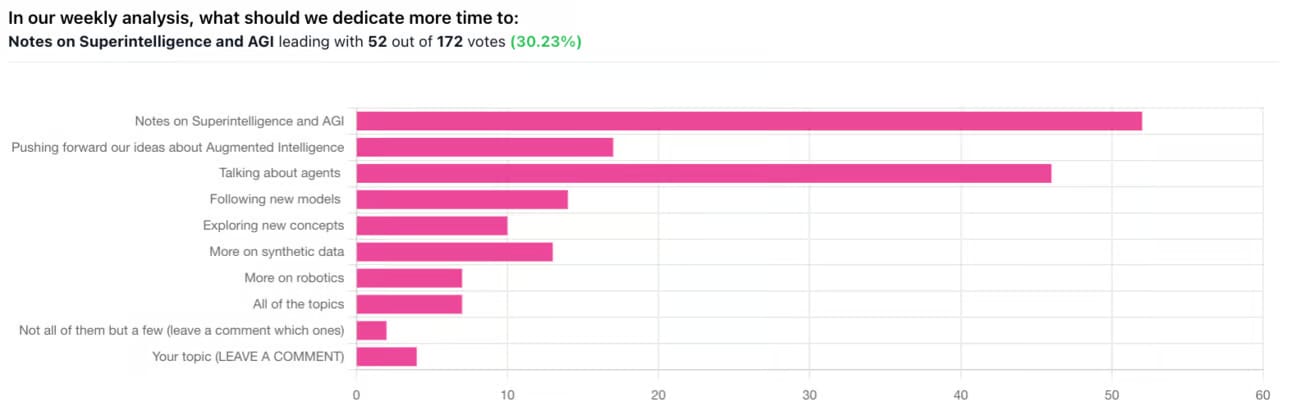
얼마 전 튜링포스트 (turingpost.com)에서 구독자들 대상으로 ‘앞으로 다루었으면 하는 토픽’에 대한 설문조사를 실시했는데, AGI와 Agent가 압도적으로 선두를 차지했습니다. AGI는 장기적인 AI의 발전 방향이라는 관점에서, Agent는 AI의 특성과 장점을 가장 잘 살리는 응용 분야라는 관점에서 그 의미가 크다고 하겠는데요. AGI에 대해서는 Twitter Library 등의 섹션을 통해서, Agent는 그 현실적인 중요성과 관심을 반영해서 그 역사, 기술, 어플리케이션 등 다양한 관점에서 별도 시리즈로 커버해 갈 예정입니다. 많은 관심 부탁드리고, 한글판 구독자분들도 관심있거나 커버했으면 하는 토픽, 회사 등이 있으면 언제든지 알려주시기 바랍니다.

금주의 튜링포스트 코리아 예고:
AI 101: LLM이 처리할 수 있는 컨텍스트가 점점 길어지고 있는 ‘Long-Context’ 환경에서, 기존 RAG의 한계를 극복하게 해 주는 LongRAG을 알아봅니다.
AI Infra Unicorns: ARM에 이어 소프트뱅크가 인수한 두 번째 반도체 회사. AI 반도체 기업 그래프코어 (Graphcore)는 어떤 회사인지 알아봅니다.
AI의 추락 - 지금이 바로 ‘실용적인’ AI를 만들어갈 때.
지난 월요일, 미국 경제의 급속한 둔화에 대한 우려, 이스라엘-이란 간 전쟁 가능성 등 여러 이유로 주식 시장, 암호화폐 시장, 유가 등 현물시장 모두가 큰 폭으로 하락세를 보였습니다. 미 연준의 금리 조정 속도에 대한 비판이 거세지면서 경기 침체기로 진입하는 것 아니냐 하는 두려움도 커지고 있구요. 저를 포함한 모두가 아마 긴장하면서 다음에 벌어질 상황을 예의주시하시리라 생각합니다.
지금이 ‘AI 거품론’, 또는 ‘AI 겨울’에 대해 이야기하기 적절한 때일까요? 어떻게 생각하세요?
지난 1~2주간 - 제 생각에는 골드만 삭스와 세콰이어 캐피탈의 리포트가 나온 이후 - 본격적으로 ‘AI 거품론’에 대한 이야기가 많이 들리고 있지만, 사실 이 주제는 1년 반 정도 전부터 꾸준히 제기되어 온 주제이기도 하죠. 그 때, 어떤 전문가 분들은 생성형 AI에 대한 막대한 투자가 역설적으로 또 다른 ‘AI 겨울’을 불러올 수 있다고 경고했었습니다. 물론 그 대척점에서, AI가 가져다줄 수 있는 이익, 그리고 업계에서의 확고한 투자 의지가 이런 붕괴를 막을 수 있다고 주장한 분들도 있구요. 지난 주, Tech. 및 Media Analyst인 Ben Thompson은 지금까지의 ‘AI에 대한 기대’는 1990년대 일었던 기술 투자 흐름과 비슷하게, 실제로 내게 필요한 뭔가를 만드느라고 생긴 것이라기보다는 ‘남들에 뒤떨어질까봐’ 하는 두려움 때문에 생긴 것에 가깝다는 비유를 들기도 했습니다. 이런 ‘두려움’은 대개 ‘기대의 과잉’, 그리고 ‘투자의 과잉’을 불러오게 되죠.
우리가 목도한 AI에 대한 이 ‘열광’은 사실 필연적으로 ‘AI의 추락’ - 실제로 많은 AI 회사들, 특히 ‘AI 워싱 (Washing)’에 열심인 회사들은 몰락하게 될 겁니다 - 을 불러올 수 밖에 없고, 우리는 아마 이후 AI를 활용해서 지속적으로 성장할 수 있는 방안을 찾기 위한 성찰의 시간을 보내게 될 겁니다. 그 동안 투자한 것을 일부 수확하고, 그 결실을 찬찬히 살펴보면서 뭘 어떻게 더 잘 해야 하는지 살펴보고 새롭게 투자해야 할 때입니다.
우리가 이렇게 우려의 시간을 보내는 사이에, 이미 AI 업계는 Hype를 지나 AI를 우리의 생활에 보다 밀접하게 연계하기 위한 실용적인 도구와 서비스들을 만드는 단계로 전환하는데 여념이 없습니다. 바로 지금부터의 시간이, 우리가 다시 한 번 ‘AI 겨울’을 맞게 될지, 아니면 AI를 기반으로 한 혁명적인 전환의 새벽을 열게 될지 결정할 것입니다.
우리가 만들고 있는 건 도대체 뭘까요?
지금 당장 자문해 봐야 할 건, ‘우리가 AI, 특히 LLM과 멀티모달 모델에 대규모로 투자하면서 진짜 달성하고자 하는게 무엇인가?’하는 질문이겠죠. 이제 인터넷 자체로부터도 더 많은, 충분한 데이터를 구할 수가 없는데도 그저 더 큰 모델, 더 많은 데이터를 맹목적으로 쫓고 있는 건 아닐까요?
곧 나온다 말이 많은 GPT-5라든가 또 그 다음에 나오게 될 GPT-6는 얼마나 더 많은 기능을 제공할 수 있을까요? 아마 우리가 묻는 질문에 대해서 더 나은 답을 줄 수는 있으리라 생각하지만, GPT-6도 ‘우리가 결국 AI로 만들고자 하는 건 뭐고, 도달하고자 하는 최종 목표는 뭔가’라는 질문에 대한 답은 모르지 싶습니다. 샘 알트만조차도 최근 조 로건과 한 인터뷰에서 ‘애초에 오픈AI를 시작할 때는, AI가 샘 자신이 힘들어하는 일을 좀 대신해 주기를 바랬는데, 지금 AI가 그런 것 같지는 않다’고 이야기한 적이 있습니다. 우리는 진짜 AI를 활용해서 진짜 필요한 무언가를 만들고 있는 걸까요? 아니면 뚜렷한 목표나 이미지가 없이 점점 더 복잡하고 큰 시스템을 만드는 일을 반복하고 있는 걸까요?
앞으로의 난제는 ‘자기 증명’
네. AI에 대한 엄청난 투자가 꽤 긴 시간 이어졌지만, 지금 AI 업계는 ‘아직 입증되지 않은 수익 모델’, ‘골드만 삭스나 세콰이어 캐피탈 등에서 제기하는 회의론’ 등 극복해야 할 꽤 어려운 숙제들을 안고 있습니다.
소위 거대 기업간, 그리고 국가간 ‘AI의 군비 경쟁’이 심화되면서, 과연 현재 AI 영역의 자본 투자 (Capital Expenditure; CapEx)가 정당화될 수 있는 건지에 대한 논쟁도 더 치열해지고 있죠. 최근에 세콰이어 캐피탈의 파트너 데이비드 칸 (David Cahn)은 ‘AI CapEx’가 단순히 크냐 작냐의 문제가 아니라 과연 진짜 누군가 ‘필요해서’ 이 투자를 하고 있는 건지를 봐야 한다고 했습니다. 마이크로소프트, 아마존, 구글 등 거대 CSP들이 경쟁하는 과정에서 엄청난 속도로 AI 투자가 이뤄지고 있긴 한데, 그 최종 목적이나 효과가 무엇일까요? 아이러니하게도, 이 거대 빅테크들의 틈바구니에서 수없이 많은 스타트업들은 고사 위기에 준하는 압박을 받기도 합니다. 게다가 AI의 발전 방향에 따라서 현재 투자하고 있는 물리적인 인프라는 나중에 무용지물이 될 수도 있지 않을까요?
AGI의 꿈은 잠깐 넣어두고, ‘실용적’인 AI 도구에 집중해요
자, 다시 질문을 해 봅시다 - 우리가 만들고 있는 건 뭘까요? AI는 어찌보면 이미 엄청난 성과를 보여줬습니다. 다양한 우려가 있지만, 많은 사람들에게 AI는 ‘실질적’인, 의미가 있는 가치를 제공하고 있는, 놀랍고 유용한 도구입니다. LLM을 우리가 제대로 사용한다면 얻을 수 있는 큰 잠재력이 있어요. 관심있으신 분은 한 번 구글 딥마인드의 연구자 니콜라스 칼리니 (Nicholas Carlini)의 글을 읽어보시면 좋겠습니다 - 니콜라스는, 여러 가지 한계가 있지만 이미 LLM이 자신이 하는 일의 생산성을 대략 50% 정도 높일 수 있는 정도의 유의미한 영향을 미치고 있다고 이야기하고 있습니다. 아직 소위 AGI 수준에 이르지 못했지만, LLM, 그리고 AI의 이점은 아주 현실적인 영역에서 빠르게 성장하고 있다는 걸 보여줍니다.
어떤 기술이든 메인스트림 마켓에 확산되는 건 하루 아침에 일어나는 일은 아닙니다. 그래도, 생성형 AI는 상당한 규모로 AI 도구가 대중적으로 사용되면서 생산성 향상에 기여하고 있다고 생각합니다. 지금 이 순간도 더 많은 AI 도구를 개발하고, 기업이 AI를 비즈니스 프로세스에 통합하도록 지원하는 스타트업들이 등장하고 있어요. 그렇게 본다면, 지금은 ‘거품이 계속되는’ 단계라기보다는 ‘의미있는 구축’ 작업이 이어지는 단계라고 볼 수 있을 겁니다.
저는 지금 우리가 만들고 있는 방향으로는 AI가 AGI에 도달할 것이라고 생각하지 않습니다 - 아직 우리는 ‘지능 (Intelligence)’이 뭔지 제대로 이해하고 있지 못하기 때문이에요. 마찬가지로, 곧 우리가 ‘AI 겨울’에 진입할 거라고 생각하지도 않습니다 - 일반적인 생산성 도구 뿐 아니라 의료, 제약, 금융, 저널리즘 등 다양한 산업 전반에 걸쳐서 쓸만한 유용한 도구들이 이미 많고 계속 나올 것이기 때문이죠.
지금은 신중하게 고려하되 전략적으로 AI에 어떻게 투자할지 결정하고 움직여야 될 시기이고, 무엇보다도 진짜 내가, 우리 회사가, 우리 나라가 AI를 통해서 뭘 하려고 하는 건지 명확한 그림을 그려야 할 때입니다.
지금 당장 더 큰 규모의 모델이 필요한지 의문을 제기하는 사람들도 많지만, 지난 몇 년간 AI 학계와 업계는 이 부분에서 LLM을 필두로 아주 가시적인 진전을 이루고 성과를 만들어냈습니다. 이제는, 한 단계 더 큰 도약에 필요한 투자를 이끌어내기 위한 ‘성공 사례’를 만들어내기 위해 모두가 팔걷어붙이고 나서야 할 때입니다. 그 주인공은, ‘AI 자체’가 아니라, 바로 ‘멋진 AI 도구를 자유자재로 활용하는 우리’가 될 겁니다.
추락 (Fall)이 아닌, 결실을 거둘 ‘AI의 가을 (Fall)’을 기대하며, 모두 화이팅입니다!!
새 코너 - 업계 전문가들이 추천하는 AI 서비스 👍🏼
Superwhisper - 이메일 작성 등 모바일 기기로 할 만한 많은 작업을 타이핑이 아니라 음성으로 자연스럽게 진행할 수 있도록 해 주는 음성 비서입니다. 온디바이스로 사용할 만한 여러 소형 모델을 다운로드해서 활용할 수 있습니다 (Free + Pro)
튜링포스트가 고른, 주목할 만한 업계 동향
구글, 금주에 아주 발빠르게 움직였습니다:
Gemini 1.5 Pro가 GPT-4나 Claude 3.5 등 주요 경쟁 모델을 뛰어넘는 성능을 보여줍니다.
Gemma 2 2B - 더 작고, 더 안전하고, 더 투명하게 작동하는 초소형 오픈소스 모델로, 콘텐츠 모더레이션 도구 ShieldGemma, 모델 해석용 도구 Gemma Scope와 함께 더 신뢰할 수 있고 이해할 수 있는 AI를 향한 구글 오픈소스 전략의 첨병 역할을 할 것으로 예상됩니다. 깔끔하게 잘 패키지화되어 있습니다.
캐릭터AI (Character.AI)의 임원 영입 - 구글의 캐릭터AI에 대한 ‘재능 인수 (Acqui-hire)’ 소식인데요. 아마존의 AdeptAI 인수, 마이크로소프트의 Inflection AI 경우와 마찬가지로, 스타트업의 탑급 임원을 영입하고 해당 스타트업은 그대로 두는 방식입니다. 독점법 위반 소지를 줄이는데 효과가 있다지만, 해당 스타트업의 인재 충원이라든가 Valuation에는 어떤 영향이 있을까, VC들은 어떤 반응을 보이게 될까 등이 궁금하네요.
구글 클라우드의 데이터베이스 포트폴리오 확장 - Spanner SQL에 그래프 및 벡터 서치를 포함시키는 새로운 AI 기능 업그레이드로, 구글 클라우드의 쓸모를 한층 높이게 될 것으로 보이네요.
크롬 브라우저에 3가지 AI 기능 추가 탑재 - 구글 렌즈, 자연어로 브라우저 기록 검색, 탭 비교 (Tab Compare; 여러 탭의 제품 정보를 모아서 비교해 줌) 기능을 탑재했네요. 검색으로부터 쇼핑을 위한 비교 작업까지 사용자의 불편을 줄여주는 유용한 기능들로 보입니다.
오픈AI, 핵심 리더급 흔들리나
샘 알트만의 해고-복귀 이후 아직 오픈AI의 경영진이 안정화되지 않은 걸까요? 지난 6월에는 공동창업자였던 일리야 수츠케버가 오픈AI를 그만두고 SSI (Safe SuperIntelligence)를 창업했는데, 또 다른 공동창업자 존 슐만 (John Schulman)이 앤쓰로픽으로 합류한다고 합니다. 존 슐만은 챗GPT의 개발에서 중추적인 역할을 담당한 사람들 중 하나로 알려져 있죠. 이 외에도 그렉 브록먼 (Greg Brokman; President), 피터 덩 (Peter Deng; Head of Product)도 장기 휴직에 들어가거나 몇 달간 오픈AI를 떠나있는 것으로 알려져 있습니다.
깃허브, AI 기능으로 ‘승부수’를 띄웠습니다
GitHub의 새로운 베타 버전, GitHub Models는 개발자가 더 쉽게 AI 모델로 실험을 할 수 있게 해줍니다. 최근 출시된 메타의 Llama 3.1과 OpenAI의 GPT-4o까지 포함하고 있어서, 이 도구는 여러 AI 모델을 비교해 볼 수 있는 원스탑 도구라고 할 수 있는데요. 여러 AI 도구들을 자사 플랫폼에 탑재, 단 한 번의 커밋 (Commit)으로 AI 개발을 가능하게 함으로써 허깅페이스 (HuggingFace) 같은 강력한 경쟁자를 앞지르려고 하는 것 같습니다.
NLP의 ‘오염 (Contamination)’ 위기
2024년 CONDA Data Contamination 리포트에서 아주 중요한 문제를 언급하고 있습니다 - 바로 GPT-4나 PaLM-2 같은 AI 모델을 훈련하는 과정에서 평가를 위한 데이터들이 학습 데이터에 포함되어, 모델이 ‘자기도 모르게’ 오해의 소지가 있는 높은 점수를 기록하게 된다는 겁니다. 보고서에서는 91개의 오염된 데이터 소스를 언급하는데, NLP 커뮤니티에 모델 평가를 위한 투명성과 더 엄격한 평가 방법이 필요하다는 점을 역설하고 있습니다. 비유하자면 AI 세상의 도핑 스캔들 정도 될까요?
‘뜨거운 감자’로 떠오른 엔비디아
엔비디아는 애플의 비전 프로로 로봇을 몰래 훈련시킨 사건과 반독점 조사, 칩 출시 지연 등의 곤경에 처해 있네요. 최신 AI 칩에서 발견된 설계 오류가 엔비디아의 발목을 잠시 잡을 수는 있겠지만, AI 업계에서의 엔비디아의 ‘영향력’에까지 이상이 생길 것 같지는 않습니다.
Groq - 시리즈 D 투자 완료
고속 추론 칩 개발사인 Groq이 2.8B USD 기업가치로 640M USD의 투자를 받았습니다. 우리 돈으로 8천 8백억원 정도 되는 엄청난 금액이네요. 메타AI의 얀르쿤 교수가 Groq의 Technical Advisor로 조인하기도 했습니다.
‘스태빌리티 AI’에서 ‘Flux’로
얼마 전 스태빌리티 AI의 CEO가 루머 속에 교체되는 사건이 있었는데요. 스태빌리티 AI의 몇몇 개발자가 블랙 포레스트 랩스 (Black Forest Labs)라는 새로운 회사를 설립하고 FLUX.1이라는 ‘텍스트-to-이미지’ 모델을 발표했습니다. 이 모델은 ‘무료’이고 미드저니나 DALL-E 3에 버금가는 성능을 보여준다고 합니다. 블랙 포레스트 랩스는 a16z가 리드한 시드 라운드에서 31M USD (약 430억원)를 투자받았고, 앞으로 ‘텍스트-to-비디오’ 모델을 공개할 예정이라고 합니다.
다른 뉴스레터의 읽어볼 만한 기사와 글
Building A Generative AI Platform - Chip Huyen
Chips for Peace: how the U.S. and its allies can lead on safe and beneficial AI
- Cullen O'Keefe
새로 나온, 주목할 만한 연구 논문
Top pick : 금주의 Top Pick은 ‘메타’ 판이네요 ㅎㅎ
The Llama 3 Herd of Models
이 연구 논문은 ‘라마 3 아키텍처’에 기반한 모델 패밀리인 'Llama 3 Herd'를 소개하는데요. 메타가 아닌 타사에서도 고성능 AI 모델을 파인튜닝할 수 있도록 한 이 접근방식은, 앞으로 AI 산업 환경에 큰 변화를 가져올 수 있습니다 - 바로 AI 경쟁에 진입 장벽을 낮춤으로써 막대한 투자 재원이 없더라도 소규모 업체나 스타트업이 다양한 맞춤화된 서비스를 개발할 수 있게 되는 것이죠. 이렇게 된다면, (메타를 제외한) 거대 테크 기업의 지배력이 흔들릴 가능성도 있어 보입니다.
SAM 2: Segment Anything in Images and Videos
메타의 연구원들이 내놓은 SAM 2는 ‘이미지, 그리고 동영상에서 원하는 객체를 따서 분할할 수 있도록 하는 통합 모델입니다. 이전에 발표한 SAM의 ‘동영상 도메인 확대 버전’ 쯤이라고 할 수도 있겠습니다. SAM 2는 스트리밍 메모리를 갖춘 트랜스포머 기반 아키텍처를 활용해서 비디오 프레임을 처리, 이전 모델에 비해서 정확도도 올라가고 사용자가 해야할 액션도 줄여준다고 합니다. 이 모델의 학습에는 지금까지 가장 큰 비디오 세그멘테이션 데이터셋인 SA-V 데이터셋이 사용되었고, 여러가지 벤치마크에서 속도, 정확도 모두 이전 모델 SAM을 능가하는 모습을 보여줍니다.
MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
이것도 역시 메타의 발표 내용인데, MoMa는 ‘얼리 퓨젼 (Early Fusion: 서로 다른 모달리티의 데이터를 하나로 합친 다음 학습을 진행)’ 방식으로 멀티 모달 모델을 사전 학습시키는데 최적화된 새로운 MoE 아키텍처입니다. 이 아키텍처는, 텍스트와 이미지를 처리하기 위해서 ‘모달리티 별’로 Expert Group을 배치해서, 기존의 방식과 대비할 때 상당한 수준의 효율성 증가와 FLOPS (연산량) 절감이 가능하다는 걸 보여줍니다. 인과 관계를 추론할 때는 여전히 어려움이 있지만, 특히 MoD (Mixture-of-Depths; 트랜스포머 각각 레이어에서 어떤 토큰을 처리할지 동적으로 선택하는 기법)와 결합될 때는 뛰어난 사전 학습 효율성, 성능을 보여줍니다. 따라서, 이전보다 더 리소스를 효율적으로 사용하는 멀티모달 AI 시스템의 길을 보여주는 하나의 방법이라고 볼 수 있겠습니다.
Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge
메타, UC 버클리, NYU 연구원들이 함께 쓴 이 연구 논문에서는 ‘메타 보상 (Meta-Rewarding)’이라는 방법을 제안하는데, 이건 LLM이 스스로 이미 내린 결정을 판단하고 개선할 수 있도록 해서 더 나은 Alignment를 할 수 있도록, 그리고 지시를 따르는 능력을 향상시키는 방법입니다. 이 방법으로 AlpacaEval 2나 Arena-Hard 등의 벤치마크에서 정확도가 크게 향상되어, 모델이 사람의 감독이 없이도 주목할 만한 개선을 할 수 있다는 걸 보여주었습니다. 이 접근방식은, 자율적으로 판단력과 답변의 품질을 향상시킬 수 있는 ‘자기 개선’ 모델을 개발할 수 있다는 가능성을 보여줍니다.
비 영어권 (Chemical Language 포함 ㅎㅎ) 언어에 대한 논문
JACOLBERTV2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources - 이 논문은 제한된 컴퓨팅 자원 환경 안에서 멀티-벡터 검색기를 최적화해서 일본어 검색 성능을 높이는 방법을 연구합니다. [논문 보기]
A Large Encoder-Decoder Family of Foundation Models For Chemical Language는 화학 관련 작업을 하는데 사용할 수 있도록 트랜스포머 기반 모델을 훈련해서, 분자의 특성 예측이나 분류 작업에서 SOTA 성능을 달성하는 결과를 보여줍니다. [논문 보기]
SeaLLMs 3: Open Foundation and Chat Multilingual LLMs for Southeast Asian Languages는 동남아시아 언어군에 맞는 다국어 모델을 만들어서, 다양한 작업에서의 성능 및 효율성 향상 결과를 보여줍니다. [논문 보기]
Adapting Safe-for-Work Classifier for Malaysian Language Text: Enhancing Alignment in LLM-Ops Framework - 말레이어 텍스트에 대한 SFW (Safe-for-Work; NSFW 또는 ‘후방주의’의 반대 개념) 분류기를 만들어서 안전하지 않은 콘텐츠를 감지할 수 있도록 합니다. [논문 보기]
Knesset-DictaBERT: A Hebrew Language Model for Parliamentary Proceedings - 이 논문은 정치적 담론에 대한 분석을 더 잘 할 수 있도록 의회 회의록 등의 정치적 텍스트를 가지고 히브리어 모델을 파인튜닝합니다. [논문 보기]
비전 및 멀티모달 모델 논문
OmniParser for Pure Vision Based GUI Agent는 UI 스크린샷을 구조화된 요소로 파싱하는 비전 기반 방법론을 개발, 다양한 애플리케이션에서 모델의 성능을 개선하도록 해 줍니다. [논문 보기]
Mixture of Nested Experts: Adaptive Processing of Visual Tokens - 이 논문에서는 시각적 토큰을 다이나믹하게 라우팅해서, 계산 비용을 줄이면서도 정확도를 유지, 비전 트랜스포머를 개선하는 프레임웍을 제안합니다. [논문 보기]
Visual Riddles: A Commonsense and World Knowledge Challenge for Vision and Language Models - 여기서는 비전 언어 모델을 대상으로 상식 및 세계에 대한 지식이 필요한 ‘수수께끼’ 벤치마크를 테스트해 봄으로써, 이런 측면들을 잘 통합해서 좋은 결과를 내는 것이 어렵다는 걸 보여줍니다. [논문 보기]
글에 대한 리뷰를 남겨주세요!
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!