

DeepSeek-R1의 등장 이후 몰아친 충격파, 그 지정학적 긴장감
지금으로부터 1달 전인 2025년 1월, 중국의 유망 AI 스타트업 DeepSeek이 자사의 추론 모델 DeepSeek-R1을 공개하면서 전세계 AI 업계에 큰 충격을 안겼죠. DeepSeek은 ‘오픈소스 전략’, 그리고 ‘효율적인 컴퓨팅 자원 활용’이라는 두 가지 축을 중심으로 해서, 오픈AI의 o1과 비견할 만한 성능의 이 모델을 10분의 1 정도의 가격에 제공하면서, 폐쇄형 모델과 오픈형 모델, 그리고 미국과 중국 간 새로운 경쟁 구도를 형성하기 시작했습니다.
금융시장도 이에 즉각적으로 반응했죠: 뉴욕 증시에서 AI 관련주들이 일제히 폭락하면서 혼란에 빠졌는데, 대표적으로 엔비디아의 주가가 장중 한 때 13% 급락했고, 나스닥 지수도 3% 넘게 떨어지면서 한 달만의 최대 일일 낙폭을 기록하기도 했습니다. 투자자들은 DeepSeek의 등장이 “AI 업계의 스푸트니크 모먼트 (Sputnik Moment)”라면서 충격을 표하기도 했습니다.
일반 대중의 관심도 그에 못지 않게 폭발적이었던 걸로 기억합니다: DeepSeek의 앱은 출시 직후 애플 앱스토어 무료 다운로드 1위를 차지하기도 했고, 사용자가 몰리면서 가입이 지연되고 사이버 공격에 시달리기도 했습니다.
한편으로는, 중국발 AI에 대한 검열이나 보안 우려도 제기되었습니다. 실제로 DeepSeek 챗봇은 천안문 사건 등 민감한 주제에 답변을 제한하거나, 이용자의 키 입력 패턴 등 데이터를 수집한다는 정책이 드러나면서, 개인정보의 유출, 악용 가능성에 대한 경계심이 높아졌습니다.
주요 국가들의 대응: ‘AI 국수주의’와 ‘오픈소스 AI’의 기묘한 동거
DeepSeek 사태 이후, 전세계 주요 국가는 저마다의 전략으로 대응에 나서고 있습니다.
미국은 즉시 자국 중심의 AI 역량 강화에 돌입했습니다. 트럼프 대통령은 취임 직후 5,000억 달러 규모의 ‘스타게이트’ AI 인프라 계획을 발표하면서, 미국을 “세계 AI의 수도”로 만들겠다고 선언했구요. 동시에 기존의 행정 명령을 철회하면서 중국에 대한 AI 기술 수출 통제를 더욱 강화하고 있습니다. 미국 의회 일부에서는 “중국산 AI를 아예 차단해야 한다”는 강경론까지 나오면서 ‘배타적 AI 국수주의’ 기조는 더욱 뚜렷해지고 있는 것으로 보입니다.
전통적으로 ‘AI 윤리 및 규제’에 앞장서 온 유럽도, DeepSeek 사태 이후 과도한 규제가 유럽의 AI 경쟁력 저하를 불러올 거라는 우려로 ‘규제 완화’와 ‘개방’ 노선을 모색하는 듯합니다. 바로 얼마 전 열렸던 파리 AI 정상회의에서, 프랑스의 마크롱 대통령을 비롯한 일부 EU의 지도자들은 자국의 스타트업을 키우기 위해서 새로운 AI 법에 융통성을 부여하는 방안을 공개적으로 지지하기도 했습니다.
한국과 일본 등 아시아 국가들은 ‘자국민 보호’, ‘기술 주권’을 강조하는 분위기가 강해 보입니다.
한국 정부는 DeepSeek 출시 직후 주요 부처 공무원들이 DeepSeek에 접속하지 못하게 차단했는데, 중국의 AI 모델 때문에 자국의 민감한 정보가 유출될 수 있다는 불안이 확산된 데 따른 선제적인 대응이죠. 민간 기업들 사이에서도 현대자동차, 한화그룹 등 주요 그룹이 사내에서 DeepSeek 사용을 금지했고, 일부는 자체적인 한국어 AI 플랫폼 개발과 사업화에 본격적으로 나서고 있습니다.
일본도 마찬가지로 AI 전략 재정비에 나섰습니다. 일본 정부는 DeepSeek의 파장이 커지자 AI 개발과 활용에 관한 기본 계획을 수립하면서, 보안과 윤리 문제를 중점적으로 다루겠다고 발표했습니다. 더불어, AI 산업 육성책과 리스크 관리를 병행하는 대응책, 그리고 AI 시대의 전력 수요 급증에 대비한 에너지 정책 등도 검토를 시작했습니다.
이렇게 수많은 국가가 ‘자국 중심의 기술 보호와 육성’에 신경을 쓰면서도, 공통적으로 ‘오픈소스 AI’를 활용한 자국의 산업 및 생태계 강화를 소리높여 주장한다는 공통점이 있습니다.
원래 오픈소스의 핵심 가치는 ‘경계없는 협업을 통한 혁신의 가속화’라고 생각합니다. 이미 소프트웨어 업계에서 입증이 되었듯이, 전세계의 연구자와 개발자들이 열린 환경에서 함께 참여할 때 기술의 발전도 비약적으로 이루어집니다. 흔히 ‘오픈소스’라고 이야기할 때 떠올리는 ‘공개’ 또는 ‘무료’라는 이미지는, ‘오픈소스’라는 정신의 결과로 나타나는 다양한 측면 중 일부일 뿐입니다.
AI 분야도 예외가 아닙니다. 메타의 수석과학자인 얀 르쿤 (Yann LeCun) 박사도 DeepSeek의 성공을 두고 “이번 일은 중국이 미국을 앞섰다기보다, 오픈소스 모델이 폐쇄형 모델을 앞서고 있다는 뜻”이라고 지적한 바 있습니다.
그런데, 과연 ‘AI 국수주의’라고도 부를 만한 현재의 긴장된 분위기, 그리고 각국의 태도가, ‘오픈 소스 AI를 통한 AI 생태계의 발전’이라는 목표와 공존할 수 있는 걸까요?
‘오픈소스 AI를 향한 글로벌 협력’, 힘들고 어려워도 확대해야
‘오픈소스 vs. 폐쇄’, ‘협력 vs. 자립’이라는 이분법적 시각 속에서, 각국은 자국의 기술적 역량을 키우면서도 국제 규범의 형성에 참여해야 하는 이중적 과제에 놓여 있습니다. 분명히 기억해야 할 것은, AI 역량을 자국 내에만 가두거나, 자국의 AI 역량만을 강화하는데 투자하겠다는 식의 ‘국수주의적 접근’은, 우리가 원하는 AI의 혁신을 둔화시킬 뿐 아니라 협업의 선순환을 차단하게 된다는 겁니다. 한 조직, 한 나라가 폐쇄적으로 일할 때보다, 전세계 인재들이 집단의 지성을 모을 때 더 빠르고 안전한 발전이 가능하다는 점은 이미 역사적으로 증명된 것이구요.
게다가, 미국·중국을 제외한 대다수 국가들에게 개방과 협업은 선택이 아닌 필수입니다.

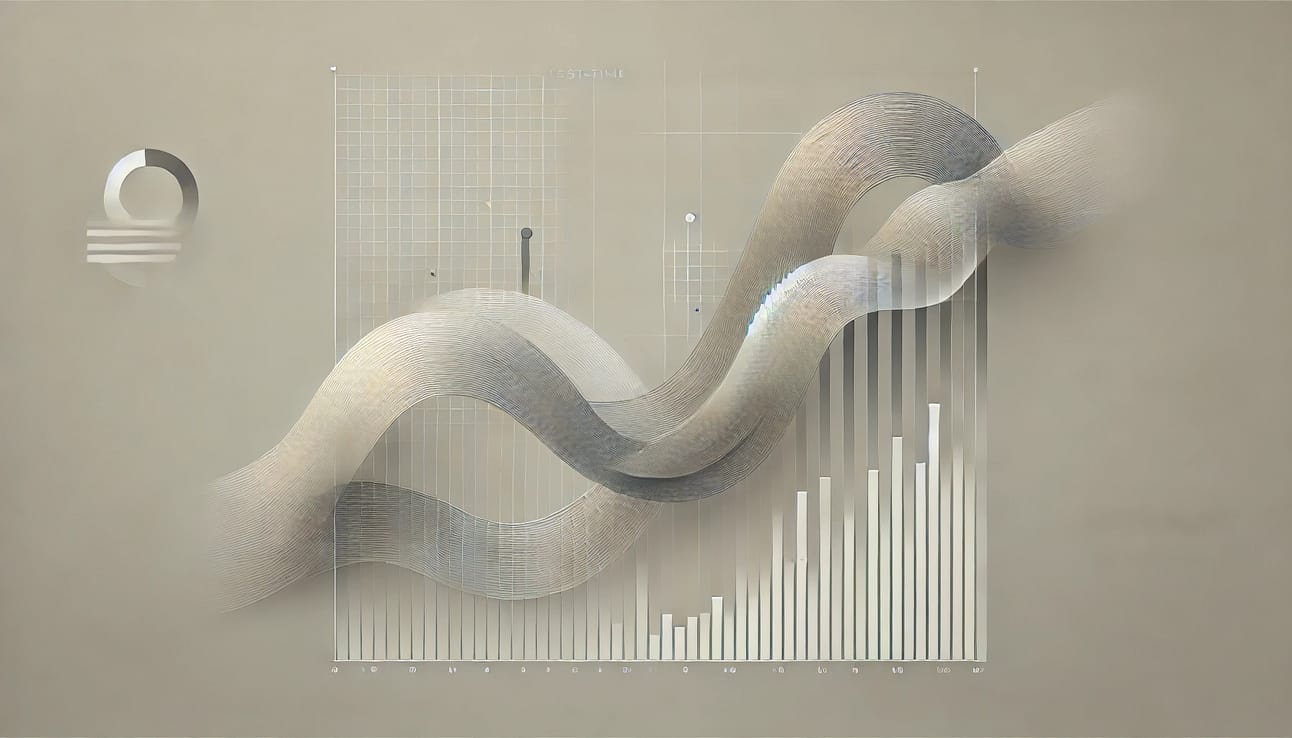
국가별 AI 스타트업 생태계 규모 vs. 국가간 AI 연구개발 협업 현황. Image Credit: 튜링 포스트
전세계 주요 국가의 ‘AI 스타트업 생태계 규모’를 해당 국가의 ‘국가간 AI 연구개발 협업 수준’과 비교해 봤습니다. X축의 AI 협업 수준은, 2022년 ~ 2024년 사이에 주요 컨퍼런스 (NeurIPS, CVPR, ICML, AAAI, ICJAI 등)에 나온 AI 연구 논문을 국가별로 300편씩 뽑아서 국제 공동연구 비율, 다기관 협업 비율을 보고 반영한 지표고, Y 축의 스타트업 생태계 규모는, 국가별 AI 스타트업에 대한 투자액, 유니콘 스타트업의 수, AI 스타트업 비율 등을 반영한 지표입니다.
지표가 로그스케일로 변환되어서 저 정도로 보일 뿐이지, 실제로는 미국과 중국을 제외하고는 AI 스타트업 생태계의 규모는 다 저~ 밑에 그만저만하게 모여있을 뿐입니다. 심지어 미국과 중국의 차이도 엄청나구요. 미국, 중국을 제외하면, 우리가 문 걸어잠그고 우리끼리만 해도 ‘오픈소스 AI’의 효익을 거둘 수 있다고 이야기할 수 있는 규모의 AI 스타트업 생태계를 보유한 나라는, 절대로 없습니다.
우리나라의 경우 지난 몇 년간 정부, 학계, 업계가 모두 노력해서 AI 연구의 관점에서 큰 진전을 보여온 게 사실입니다. 일본의 경우도 많이 노력하고 있구요. 그렇지만 우리나라나 일본 같이 AI 기술, 그리고 AI 산업을 성장시키려고 대규모 투자를 계속하고 있는 나라조차도, 개별적인 AI 스타트업 생태계는 그 규모에 명확한 한계가 있습니다. 단순히 ‘자국의 오픈소스 AI 생태계를 강화’한다는 캐치프레이즈와 ‘독자적으로 AI 역량 및 산업을 키우겠다는 국수주의적인 투자’로는, 자국 AI 기술의 혁신과 산업의 성장을 이끌어낼 수 없습니다.
프랑스가 ‘오픈소스 AI의 허브'를 표방하면서 미스트랄 같은 기업을 지원하는 이유도, 전세계적인 협력 네트워크 속에 유럽이 들어가야 경쟁력이 생긴다는 깨달음이 있었기 때문입니다. 결국, 혁신은 전세계적으로 협력하는 개방 환경에서, 안보도 국제적인 공조를 통해서 달성되는 것이라고 생각합니다. 이미 오늘 미국의 AI 스타트업이 개발한 서비스를 내일이면 지구 반대편의 모든 나라에 있는 사람들이 사용해 볼 수 있는 이 시대에, 과감하게 AI 국수주의적인 관점을 버리고 어떻게 다른 나라와 협업과 협력을 확대하면서 건전하게 경쟁할 것이냐 하는 고민, 그리고 그 고민이 반영된 투자와 노력이 없이는, 결국은 고립되고 뒤쳐질 수 밖에 없습니다.
인력을 키우겠다구요? 키워야지요. 그렇지만 우리나라를 보자면 AI 인력의 Inflow보다 Outflow가 많은 나라에 속합니다 - 외국에서 우리나라에 와서 연구나 일을 하는 AI 인력보다 그 반대로 나가는 인력이 점점 더 많아질 수 밖에 없습니다. 답은 정해져 있다고 생각하고, 그렇다면 그에 맞게 계획을 세우고 그에 맞게 투자를 해야겠죠.
어느 나라든, 안보와 산업 경쟁력 측면에서 AI의 주권을 지키면서도 동시에 개방적인 생태계에서 뒤쳐지지 않으려는 이중적인 과제에 직면하고 있고, 지금으로서는 예전과 같은 수사를 반복하면서 똑같은 방식의 투자를 말하고 있다는 생각에 안타깝습니다. 그렇지만 잊지 말아야 합니다: 국경을 넘어서 공유되는 지식이야말로 AI 기술과 산업 발전의 연료라는 것을요. 돌이켜 보면, 캐나다와 영국 출신 학자들이 주도한 딥러닝 연구도 미국 실리콘밸리 자본과 다양한 나라의 데이터 자원이 결합하면서 꽃을 피운 셈입니다. 이런 글로벌 협업과 밸류 체인이 없었다면, 오늘날의 AI 혁신이 과연 가능했을까요? 오픈소스 운동의 산물인 Python, PyTorch, TensorFlow 같은 핵심 도구들도, 특정 국가가 아닌 전 세계 개발자들의 협력으로 만들어지고 광범위하게 사용되면서 AI 발전을 크게 앞당겼습니다. 만약 각 나라가 이런 지식과 도구를 폐쇄적으로 통제하고, 전 세계의 수많은 개발자들이 협업하기 어려운 환경이었다면, AI 발전 속도는 지금보다 훨씬 더디고 그 결과도 오직 일부의 국가나 지역에서만 향유할 수 있었을 겁니다.
DeepSeek 사태로 인해 촉발된 현재의 갈등과 고민, 기술 패권을 향한 경쟁 속에서도 ‘인류 공동의 발전을 위한 협력’이라는 큰 그림을 간과해서는 안 될 것입니다. 지금이야말로 ‘글로벌 협력’과 ‘자국의 이익’을 조화시키는 지혜가 필요한 때입니다.
트위터 라이브러리 (Twitter Library) 🐦
‘Test-Time Compute’는 AI 모델이 응답을 만들어낼 때 사용하는 연산 능력이죠. 많은 연구자들이 지금 TTC의 확장, 즉 스케일링에 집중하고 있는 이유는, 느리지만 심층적인 ‘사고’, 그리고 단계별 추론을 가능하게 해서 전반적인 모델의 성능을 - 우리가 원하는 방향으로 - 향상시켜줄 수 있기 때문일 겁니다.
오늘은 Test-Time Scaling에 대한 8가지의 새로운 연구에 대해서 알아봅니다:
*아직 튜링 포스트 코리아 구독 안 하셨나요? 구독해 주시면 매주 중요한 AI 뉴스를 정리한 다이제스트를 받으실 수 있습니다!
금주의 주목할 만한 업계 동향 📰
앤쓰로픽이 여러 가지 뉴스로 미디어를 장식한 한 주였습니다.
새로운 하이브리드 모델
앤쓰로픽에서 ‘비용’ - ‘성능’ 사이에서 절충하면서 조정할 수 있는 성능의 범위를 제공하는, 새로운 하이브리드 모델을 출시했습니다. 오픈AI가 단순한 ‘저-중-고’ 식의 옵션을 제공하는 것과 다리, 이 모델은 정밀하게 성능 수치를 조정할 수 있어서, 복잡한 워크로드를 처리하는 기업의 경우에 쓸모가 있을 것 같습니다. 초기의 피드백으로는, 코딩 작업에서 오픈AI 모델의 최고 성능을 능가하는 것으로 나타났네요.이 지수는 Claude.ai를 사용하는 사람들의 익명화된 데이터 수백만 건에 기초해서, 노동 시장에 대한 AI의 영향을 추적해 보겠다는 시도입니다. 자료에 따르면, AI는 소프트웨어 개발과 기술 문서 작성 등의 영역에서 강력한 파워를 드러내고, 작업의 성격은 ‘자동화’보다는 ‘증강’ 쪽인 것으로 나타납니다. 중간 정도부터 고임금의 직업군에서 AI의 활용률이 가장 높다고 하네요. 데이터셋은 오픈되어 있어서, 연구자들이 AI 활용 패턴의 추세를 분석하고, 변화하는 AI 기반의 경제 환경에 대응하기 위한 정책 결정에도 활용할 수 있을 것으로 보입니다.

Where and how AI is used across the economy, drawn from real-world usage data from Claude.ai. The numbers refer to the percentage of conversations with Claude that were related to those individual tasks, occupations, and categories.
스노우플레이크 + 앤쓰로픽의 파트너십 = 데이터 기반의 강점을 가진 AI
스노우플레이크와 앤쓰로픽 양사가 협업해서 Claude 3.5 Sonnet을 Cortex Agents에 내장, 기업의 데이터 분석을 자연어로 실행할 수 있게 합니다. 텍스트 - SQL 작업에서 강력한 성능을 보여주는데, AI 기반의 의사 결정에 유용하게 활용될 수 있을 것으로 보입니다.
…오픈AI도 꾸준히 새로운 소식과 로드맵 이야기로 주도권을 잃지 않고 있습니다.

모델 스펙 업데이트
오픈AI가 자사 모델 스펙을 업데이트했네요.
오픈AI에 추가 설명에 따르면, o1 및 o3-mini 같은 모델은 복잡한 추론, 의사 결정 및 다단계 계획에 뛰어난 모델로 법률, 금융 및 엔지니어링 분야의 작업에 잘 맞는다고 합니다. GPT 모델은 더 빠르고 간단한 작업을 비용 효율적으로 하고자 할 때 좋구요. - 딱히 새로운 이야기는 아니네요. o-시리즈를 잘 사용하는 사례로, 모호한 정보를 처리할 때, 대규모 데이터셋에서 핵심적인 세부 정보를 찾고 싶을 때, 고급의 코드를 검토할 때 등이 포함되어 있네요. 효과적인 프롬프트는, 명확하고 직접적으로 써야 하는데, 단계별 지침이나 예제 몇 개는 거의 필요없다고 합니다.
갈릴레오 랩, 허깅페이스에 에이전트 리더보드 게시
갈릴레오 랩스가 새로운 에이전트 리더보드를 허깅페이스에 출시, LLM이 실제 에이전틱 워크플로우에 필요한 작업을 얼마나 잘 처리하는지 벤치마킹하기 시작했습니다. 완벽하지는 않더라도, 개발자가 에이전트 어플리케이션을 만들 때 사용할 모델을 선택하는데 도움이 될 것 같습니다.
튜링 포스트 코리아팀이 읽고 있는 것들
The New Touch Interface (by Will Schenk)
‘새로운 기술이 등장할 때, 처음에는 단순한 용도로 사용되지만, 시간이 지나면서 우리의 삶을 근본적으로 바꾸는 방식으로 발전한다’는 원리를 바탕으로, AI도 지금은 단순히 질문에 답하거나 그림을 그려주는 정도에 불과하지만 앞으로는 우리의 생각과 소통 방식 자체를 바꾸는 도구가 될 거라는 이야기를 하고 있습니다.
이 글에서는 거대 언어모델 (LLM)이 단순히 단어를 예측하는 '확률적 앵무새'인지, 아니면 내부적으로 월드 모델을 구성하면서 사물에 대한 더 깊은 이해를 갖추고 있는 무언가인지에 대한 논쟁을 다루고 있습니다. 일부의 연구에서는 LLM이 단순히 통계적 패턴을 넘어서, 훈련 데이터로부터 복잡한 개념과 관계를 학습, 내부적으로 '월드 모델'을 구축할 수 있다는 걸 시사하기도 하죠. 물론 이런 모델의 한계와 진정한 이해 능력에 대한 의문은 여전히 남아 있습니다.
이 글에서는 거대 언어모델 (LLM)이 단순히 단어를 예측하는 '확률적 앵무새'인지, 아니면 내부적으로 월드 모델을 구성하면서 사물에 대한 더 깊은 이해를 갖추고 있는 무언가인지에 대한 논쟁을 다루고 있습니다. 일부의 연구에서는 L
Dwarkesh Patel의 Noam Shazeer, Jeff Dean 인터뷰
구글의 최고 과학자인 Jeff Dean, 그리고 AI 연구자 Noam Shazeer와 한 이 인터뷰에서는 지난 25년 간 구글에서 했던 경험, 그리고 AI의 발전에 대해 이야기를 나눕니다. 초기의 PageRank 알고리즘부터 MapReduce, BigTable, TensorFlow, 최근 Gemini 프로젝트까지 여러 혁신적인 시스템 개발에 참여했던 경험, 그리고 AI의 미래, 구글의 역할, 하드웨어와 알고리즘 설계의 상호 보완적인 발전에 대한 비전을 공유합니다.
새로 나온, 주목할 만한 연구 논문
‘주목할 만한 최신의 AI 모델’을 먼저 소개하고, 각 영역별로 ‘Top Pick’은 해당 논문 앞에 별표(🌟)로 표시했습니다!
주목할 만한 최신 AI 모델
LM2: Large Memory Models에서는 Long-Context 환경에서 추론 능력을 개선하기 위한 메모리 모듈을 갖춘 Transformer 아키텍처, LM2를 소개하는데, LM2는 RMT를 37.1% 능가하고, 멀티 홉 추론에서 뛰어난 성능을 보입니다.
NatureLM: Deciphering the Language of Nature for Scientific Discovery는 과학 영역 전반에 걸쳐서 NatureLM을 훈련시켜서, 다양한 도메인의 어플리케이션에 적용할 수 있도록 SMILES-to-IUPAC 변환, CRISPR RNA 설계 같은 작업의 성능을 향상시켜 줍니다.
LLM 아키텍처, 트레이닝 및 최적화 기법
🌟 Matryoshka Quantization은 효율적으로 모델을 배포하기 위해서 int2, int4 및 int8 레이어를 혼합하는 멀티 스케일 양자화 기법 MatQuant를 소개합니다.
InfiniteHiP: Extending Language Model Context Up to 3 Million Token는 모듈화된 Hierarchical Pruning 기법을 활용해서 단일 GPU에서 컨텍스트 용량을 3M 토큰으로 확장해 줍니다.
🌟 LLM Pretraining with Continuous Concepts는 트레이닝 효율성을 향상시키기 위해서 토큰 임베딩과 추상적 개념 표현 (Representation)을 혼합하는 CoCoMix를 제안합니다.
모델의 추론 및 인지적 역량
🌟 LLMs can easily learn to reason from demonstrations는 LLM이 복잡한 추론 작업을 학습할 때, 내용보다 구조적 패턴에 더 많이 의존한다는 것을 보여줍니다.
From brute force to brain power: How Stanford’s s1 surpasses DeepSeek-R1 – 최고의 성능을 내기 위해서 최소한의 고품질 예제를 사용하는, 데이터 효율이 아주 높은 추론 모델을 개발합니다.
🌟 Forget what you know about LLMs evaluations – LLMs are like a chameleon은 LLM이 피상적인 패턴에 얼마나 의존하는지를 확인하는 벤치마크 과적합 디텍터, C-BOD를 제안합니다.
강화학습 및 적응 행동
🌟 Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning – 결과에 기반한 보상 메커니즘을 사용해서 수학적 성능을 향상시키는 RL 프레임웍, OREAL을 소개합니다.
Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning은 사람과 유사한 의사소통 능력을 갖춘 사회적 추론 게임을 탐색하도록 LLM을 훈련하는 RL 기반 프레임웍을 소개합니다.
에이전트 개발
Towards Internet-scale training for agents에서는 웹 에이전트의 탐색 및 상호 작용 기술을 향상시키는 대규모 훈련 파이프라인, InSTA를 소개합니다.
🌟 Hephaestus: Improving Agent Capabilities through Continual Pre-Training은 추론, 계획 및 함수 호출 영역에서 LLM 에이전트의 능력을 향상시키기 위한 특수 코퍼스를 개발합니다.
WorldGUI: Dynamic Testing for GUI Automation은 실제 어플리케이션의 과제를 반영하는 다이나믹한 GUI 작업에서 LLM 성능을 평가하기 위한 벤치마크를 제안합니다.
읽어주셔서 감사합니다. 프리미엄 구독자가 되어주시면 튜링 포스트 코리아의 제작에 큰 도움이 됩니다!