


글을 시작하며
튜링 포스트 코리아의 ‘AI 101’ 섹션에서 그 동안 다양한 RAG 아키텍처에 대한 소개는 꽤 했었는데요. LLM 기반 어플리케이션의 전반적인 쓰임새와 성능을 높이기 위한 또 다른 중요한 한 축, ‘파인튜닝’이 있죠! 코딩용 모델이라든지, 특정한 도메인, 기능을 더 잘 하도록 설계된 모델 등, 전문화된 AI 모델이 더 확산될수록, 특히 성능의 향상 등을 위해 파인튜닝 작업이 중요한 경우가 많다고 합니다.
그렇지만, 거대한 모델의 모든 파라미터를 다시 트레이닝하는 ‘Full Fine-Tuning’은 돈도 돈이고 시간도 오래 걸려서, 부담이 될 수 밖에 없죠. 2021년 마이크로소프트에서 발표한 ‘LoRA (Low Rank Adaptation)’이 바로 여기에 대한 해결책이 되었는데요. 이건 ‘사전 훈련된 모델의 가중치 (Weight)는 고정시켜 놓고, 트랜스포머 아키텍처 각각의 계층에 훈련 가능한 행렬을 별도로 삽입해서, 다운스트림 과정에서 매개변수 수를 크게 줄이는 효과를 줍니다. 간단히 이야기하자면, LoRA는 LLM의 파인튜닝을 아주 효율적으로 하게 해 주는 기술인 거죠.
물론, LoRA도 모든 경우에 항상 최고의 결과를 만들어주지는 않으니까, 또 여기서 다양한 변종인 DoRA, QLoRA, QDoRA 같은 추가적인 기법들이 개발되었습니다. 이 기법들이 개략적으로 어떤 내용인지, LoRA를 어떻게 개선해 주는지 한 번 알아볼까요?
이 글은 아래 목차로 구성되어 있습니다:
LoRA의 문제점은 뭔가?
일반적으로 거대 언어모델을 특정한 작업을 더 잘 하도록 조정하려면, 모델의 ‘파인튜닝’을 하게 됩니다. 파인튜닝을 할 때는 기본적으로 모델의 모든 파라미터를 재학습시키지만, 모델이 커질수록 이 작업에 필요한 비용, 리소스가 기하급수적으로 늘어나죠.
이런 제약 조건을 해결하기 위해서 PEFT (Parameter-Efficient Fine-Tuning)라는 방법이 개발되었는데, 그 중의 하나가 LoRA (Low-Rank Adaptation)입니다. 위에서 간단히 LoRA의 개념은 설명드렸구요. 그런데 아무래도 LoRA는 모든 파라미터를 다시 학습시키는 Full Fine-Tuning과 비교하면 성능이 아무래도 떨어집니다. 왜 그럴까요?
엔비디아, 그리고 홍콩과기대 (HKUST) 연구자들이, Weight Normalization (가중치 정규화) 개념에서 영감을 받아 LoRA와 Full Fine-Tunin을 비교했는데요: ‘가중치 정규화’는, 가중치의 행렬을 ‘크기 (변화의 크기)'와 ‘방향 (파라미터 공간에서 변화가 일어나는 위치)’의 두 가지 구성 요소로 분리합니다. 이렇게 분리하면, 각각의 방법이 모델의 가중치를 업데이트하는 메커니즘을 더 잘 이해할 수 있어서, LoRA와 Full Fine-Tuning의 유연성이랄지 정밀도를 더 자세히 비교할 수 있다고 합니다.
연구진은 두 가지 방법이 모델을 서로 다른 방식으로 업데이트한다는 걸 발견했는데요:
LoRA는, 모델을 ‘비례적으로 (Proportionately)’ 업데이트하는데, 즉 가중치의 ‘크기’와 ‘방향’을 일관되게 변경한다는 뜻입니다.
반면에, Full Fine-Tuning은 조금 더 복잡한 업데이트 방식을 보여주는데요. 가중치의 ‘방향’은 미세하고 미묘하게 변경하는 반면에, ‘크기’는 그 정도가 클 수도 있고 그 반대의 경우도 있습니다. 이런 ‘유연성’ 때문에 Full Fine-Tuning이 좀 더 특정한 작업에 필요한 정밀한 반응을 보이도록 모델을 조정할 수 있는 것으로 판단됩니다.
바로 LoRA 기법이 Full Fine-Tuning 대비 이런 유연성이 부족해서, Full Fine-Tuning 같은 정밀한 조정과 업데이트가 항상 되는게 아닌 거죠. 물론, 반복해서 언급하지만 Full Fine-Tuning에는 모든 파라미터를 한꺼번에 다시 학습시키는데 따르는 자원이 더 필요하죠.
DoRA (가중치 분해 LoRA)의 등장
이렇게, AI 모델의 파인튜닝을 둘러싼 ‘효율성’과 ‘성능’, 두 가지 사이의 간극을 좁히겠다는 목적으로, 엔디비아와 홍콩과기대 연구자들이 DoRA (가중치 분해 LoRA; Weight-Decomposed Low-Rank Adaptation)라는 새로운 방법을 개발한 겁니다.
*재미있게 보고 계신가요? 프리미엄 플랜에 가입해 주시면, 튜링 포스트 코리아의 컨텐츠를 제작하는데 큰 도움이 됩니다!
DoRA는, 연구자들이 Full Fine-Tuning을 진행할 때 일어나는 일을 분석한 결과에서 힌트를 얻어서, 사전 훈련된 가중치를 ‘크기’ 요소와 ‘방향’ 요소로 분리하고, 이 두 부분을 별도로 파인튜닝합니다. 이렇게 해서 더 파인튜닝을 쉬우면서 안정적으로 할 수 있다고 합니다.
DoRA의 적용 범위를 확인하기 위해서, 기본적인 NLP 뿐 아니라 언어나 시각을 모두 포함하는 다양한 작업에 이르기까지 테스트를 했는데, 추가적인 추론 시간 없이도 LoRA 보다 일관적으로 더 나은 성능을 보여주었습니다.
DoRA는 NLP부터 언어와 시각을 모두 포함하는 작업에 이르기까지 다양한 작업에서 테스트되었으며, 추론 시간을 추가하지 않고도 LoRA보다 일관되게 더 나은 성능을 발휘합니다.
DoRA의 작동 방식, 이점 및 성능
DoRA는 가중치의 ‘방향’ 요소를 업데이트하는데 LoRA를 사용해서 효율성을 유지하면서도, 모델의 전반적인 학습 능력을 향상시켜서 결과적인 성능이 Full Fine-Tuning에 가깝게 나오도록 합니다.
DoRA의 작동 방식
아래는 DoRA의 작동 방식을 단계적으로 보여줍니다:
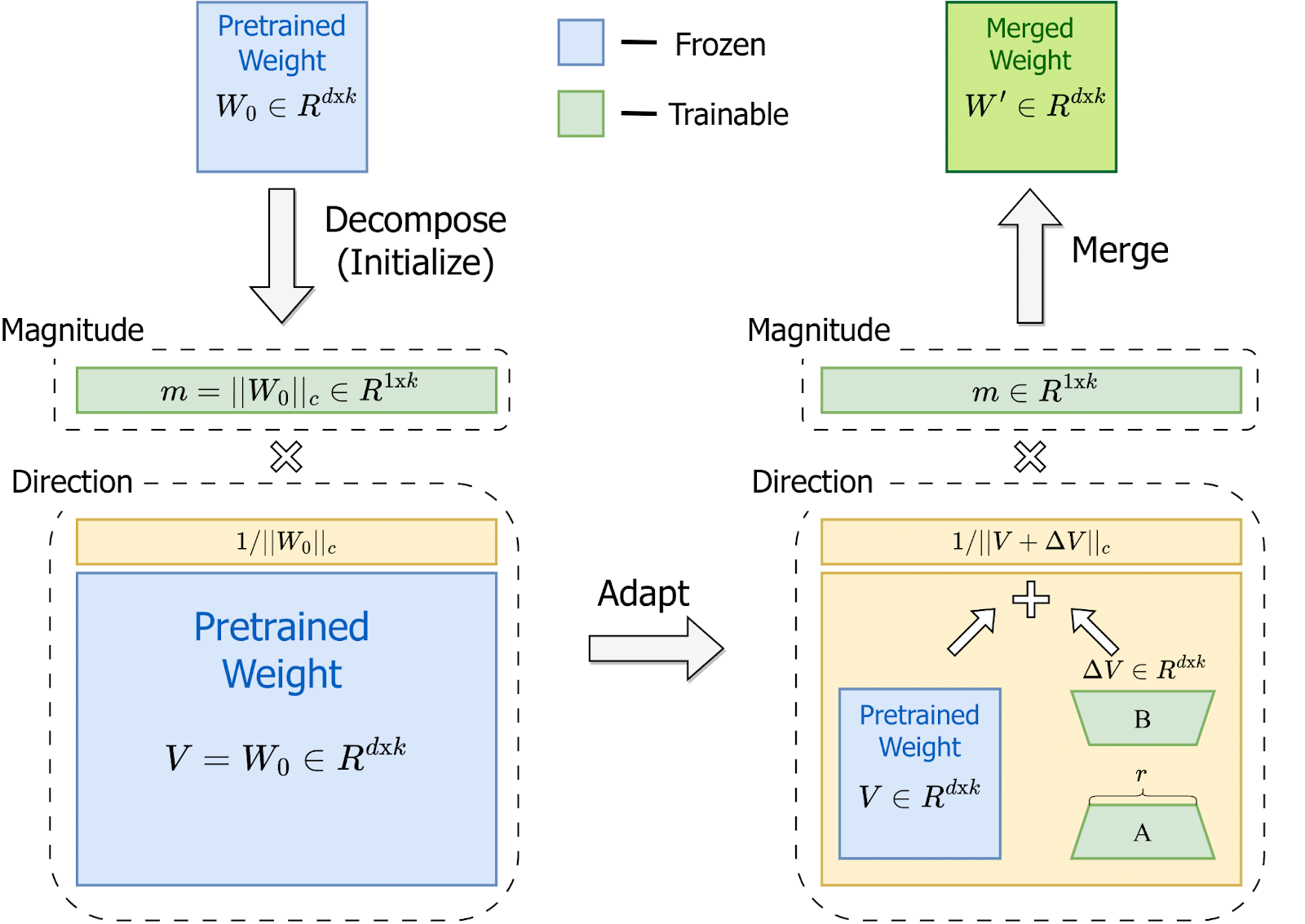
Image Credit: DoRA 논문
가중치를 분해하기: DoRA는 사전 학습된 가중치를 두 부분으로 분할하는 것으로 시작합니다.
크기 (Magnitude): 가중치가 얼마나 크냐, 또는 강하냐를 나타냅니다.
방향 (Direction): 트레이닝 중에 가중치가 어떻게 변화 또는 움직이냐를 나타냅니다
가중치 분해 후에, DoRA는 분해된 ‘크기’, ‘방향’을 개별적으로 파인튜닝합니다.
‘크기’는 직접적으로 파인튜닝을 하고, 훈련 중에 조정할 수도 있습니다.
‘방향’ 부분은 상대적으로 훨씬 큰 대상이라서, LoRA를 활용해서 처리하는데요. LoRA는 훈련 가능한 파라미터를 너무 많이 추가하지 않으면서 더 작고 관리하기 쉬운 업데이트의 단위로 나눕니다.
파인튜닝을 한 이후에, DoRA는 업데이트를 원래의 가중치와 병합해서, 예측을 위한 추가 계산을 하지 않고도 모델을 효율적으로 유지합니다.
DoRA의 이점과 성능
DoRA 기법은 LoRA의 한계를 해결하기 위해 만들어진 기법이라고 했으니, 그 장점을 살펴봅시다:
작업의 간소화: DoRA는 가중치 업데이트를 두 부분으로 나눠서 진행하니까, 파인튜닝을 좀 더 쉽게, 안정적으로 진행할 수 있습니다.
효율성 제고: 비교적 복잡한 ‘방향’ 요소의 업데이트를 위해서 LoRA를 사용하기 때문에, 학습해야 하는 파라미터의 수가 줄어듭니다. 즉, 방향 요소 업데이트에만 집중하니까 LoRA의 작업이 간소화된다는 거죠.
Full Fine-Tuning에 필적하는 성능: DoRA는 계산 비용이 과도하게 들거나 과부하가 걸리지 않고, 모든 파라미터를 다시 트레이닝하는 경우에 가까운 성능을 발휘하게 해 줍니다.
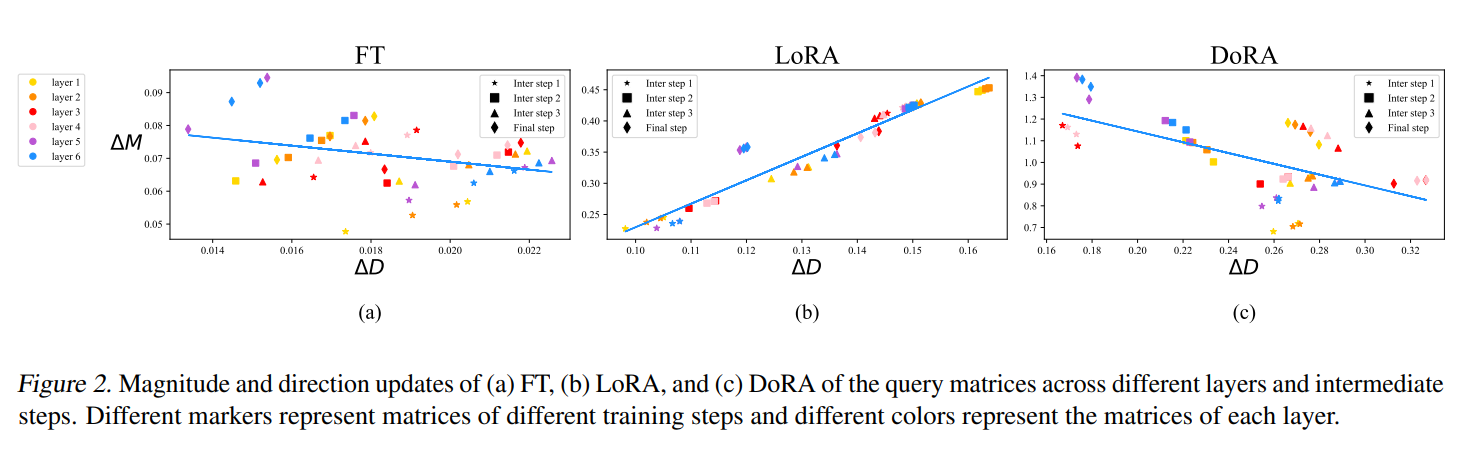
Image Credit: DoRA 논문
DoRA의 성능을 알아보기 위해서 연구자들이 다양한 벤치마크, 다양한 작업을 가지고 테스트해 본 결과는 다음과 같습니다:
LLaMA 모델 제품군(7B, 13B, LLaMA2-7B, LLaMA3-8B)을 가지고 8가지 상식 추론 (Commonsense Reasoning) 데이터셋으로 테스트한 결과, DoRA는 LoRA 기법을 사용한 경우보다 14.4% 더 나은 성능을 보여줬습니다.
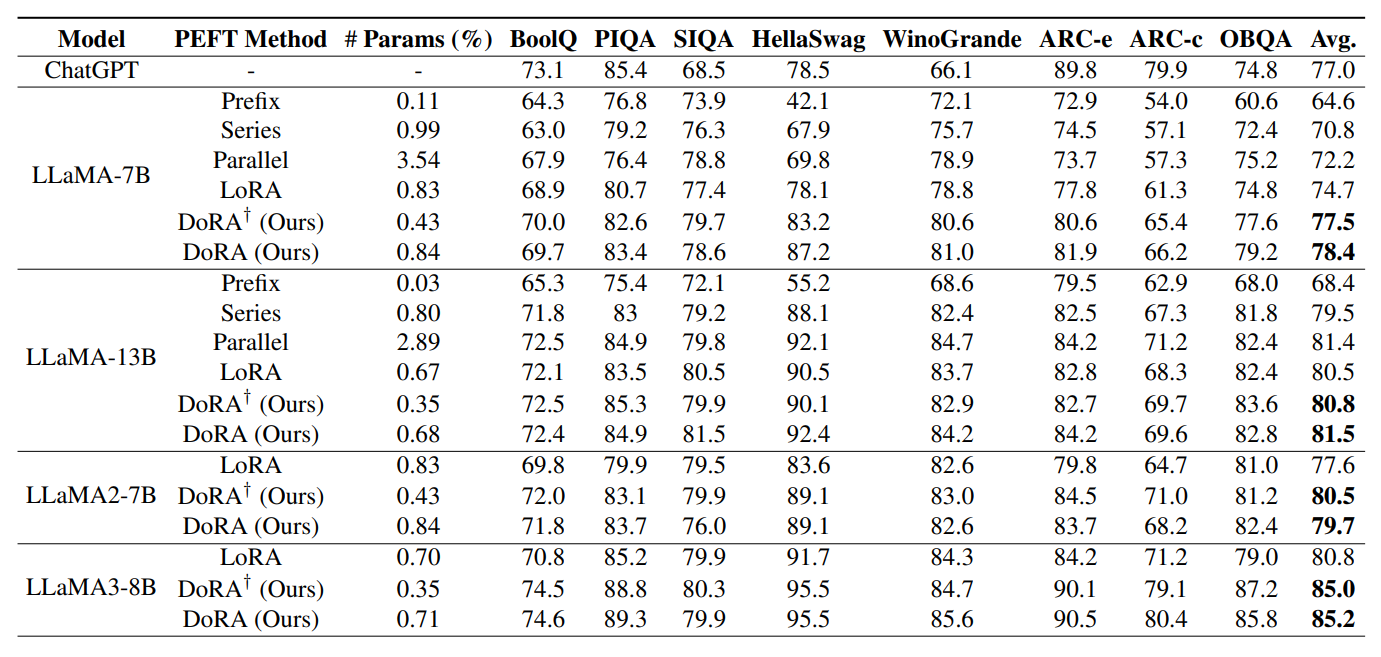
Image Credit: DoRA 논문
이미지-텍스트 작업: DoRA가 LoRA를 약 1% 앞지르는 성능을 보여줬습니다.
비디오-텍스트 작업: DoRA가 LoRA보다 2% 정도 더 나은 성능을 보여주면서, Full Fine-Tuning에 가까운 정확도를 달성했습니다.
LLaVA-1.5-7B 모델로, Visual Instruction 작업을 대상으로 테스트한 결과, DoRA가 LoRA보다 0.7%, Full Fine-Tuning보다는 1.1% 더 높은 정확도를 보였습니다.
메모리 효율성: DoRA 기법을 사용했을 때 트레이닝에 필요한 메모리는, 수정하지 않은 버전에 비해 LLaMA의 경우 24.4%, VL-BART의 경우 12.4% 감소했습니다.
가중치를 업데이트할 때 가중치의 ‘크기’와 ‘방향’을 분리해서 파인튜닝할 수 있는 DoRA의 기능은, 특히 특수한 다운스트림 태스크를 위해 정밀한 조정이 필요한 경우에 파라미터를 효율적으로 유연하게 파인튜닝할 수 있는 가능성을 열어주었습니다.
그렇지만, DoRA도 거대 모델을 파인튜닝하는데 있어서 ‘메모리 사용량 관리’라는 또 다른 중요한 과제가 남아 있는데요 - 여기서 바로 QLoRA가 등장합니다.
QLoRA는 뭐고, 왜 사용하는가?
자, 워싱턴 대학교의 연구자들이 650억 개 수준의 파라미터를 가진 거대한 LLM을 파인튜닝하면서도 메모리는 더 적게 사용하는 방법이 없을까 고민하다가 개발한 것이, 바로 QLoRA입니다. 논문은 여기서 보실 수 있구요. 논문을 보면, QLoRA를 적용해서 메모리 필요량을 780GB에서 48GB 미만으로 대폭 - 정말 엄청나죠? - 줄여서, 일반인이 쓰는 고사양 컴퓨터의 메모리 수준 - 단일 48GB GPU - 으로도 실행할 수 있습니다. 이렇게 메모리를 적게 사용하면서도, 일반적인 파인튜닝 방법에서 보여주는 수준의 성능을 유지하고, 속도 저하도 발생하지 않습니다. QLoRA의 핵심은, ‘양자화 (Quantization)’에 있습니다.
QLoRA의 작동 방식과 성능
QLoRA는 어떻게 작동하나
양자화 (Quantization)는 앞에서 잠깐 이야기한 PEFT (Parameter-Efficient Fine-Tuning)의 방법론 중 하나인데, 언어모델의 파라미터를 ‘실수형 (32비트 부동 소수)’에서 ‘정수형 (8비트 정수)’으로 바꿔서 비트 수를 줄이는 과정을 말합니다. 데이터를 더 간단한 형태로 변환해서 모델 사이즈를 줄이는 거죠. 이렇게 하면, 세부 정보는 좀 덜 저장되지만 여전히 원본에 가깝게 유지되고, 데이터는 새로운 범위에 적절히 맞도록 크기가 조정됩니다.
QLoRA는 그 적용 과정에서 몇 가지 메모리 절약 기술을 활용합니다:
NF4 (4-bit NormalFloat) 양자화 (Quantization): 이 기법은 대량의 정보를 더 작고 관리하기 쉬운 덩어리로 변환해서 데이터를 단순화합니다 - 고해상도 이미지를 촬영한 후에, 화질을 크게 떨어뜨리지 않으면서도 원본에 가깝게 크기를 조정하는 것과 비슷하다고 생각하면 됩니다.
이중 양자화 (Double Quantization): 이건 데이터를 저장하는 방식을 단순화해서 메모리를 더욱 줄이는 일종의 트릭 같은 기법입니다. 이 방법이 메모리 사용량을 더 줄이기 위한 두 번째 단계로, 정확도를 잃지 않고 더 적은 비트를 사용해서 데이터를 더욱 단순화합니다. ‘양자화 상수를 양자화’해서, 파라미터 당 평균 약 0.37비트(65B 모델의 경우 약 3GB)를 절약해 준다고 합니다.
Paged Optimizer: 이건 스마트한 메모리 관리자라고 볼 수 있습니다. GPU의 메모리가 부족하면 옵티마이저 (Optimizer)가 자동으로 데이터를 CPU로 이동시켰다가 필요할 때 다시 가져옵니다. 이렇게 하면 메모리 스파이크로 인한 시스템 충돌이나 속도 저하를 방지할 수 있습니다.
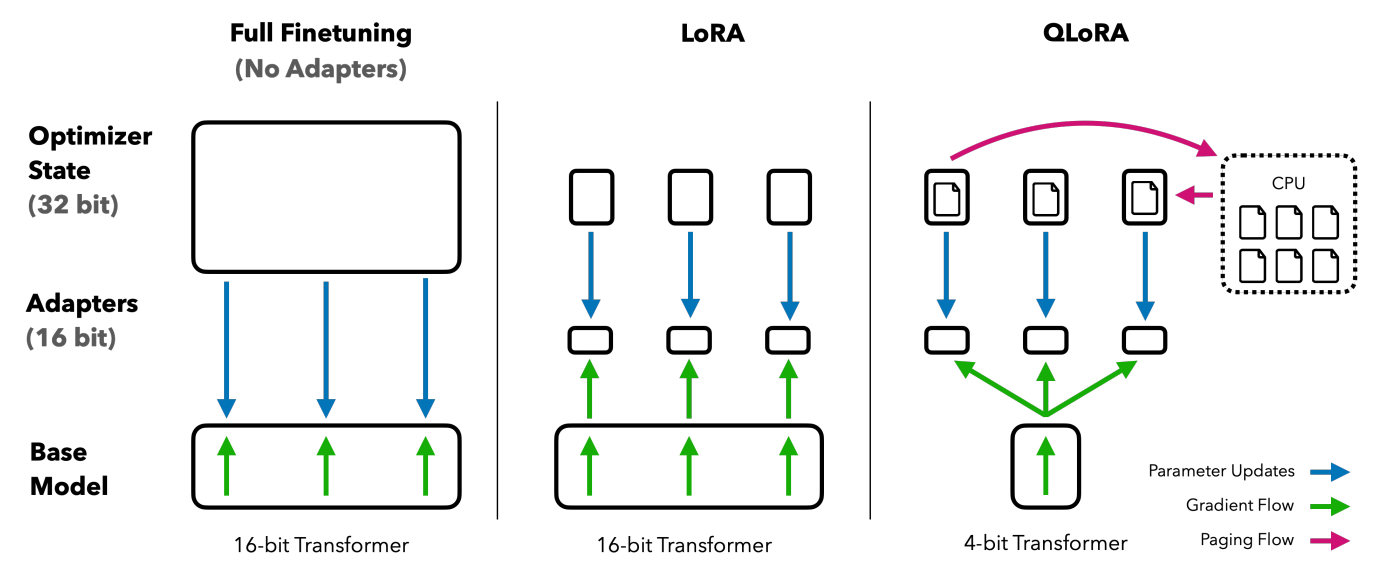
Image Credit: QLoRA 논문
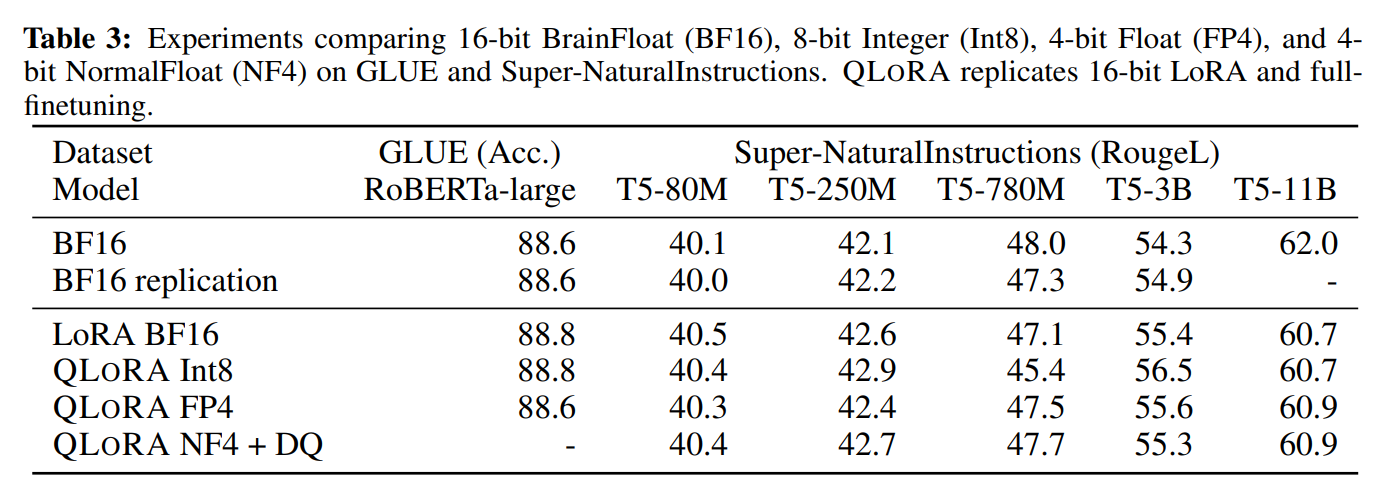
Image Credit: QLoRA 논문
QLoRA의 성능
워싱턴 대학교의 연구자들이 LlaMA 모델을 기반으로 만들고 QLoRA를 사용해서 파인튜닝한 오픈소스 모델, ‘Guanaco’ 모델 제품군은 뛰어난 성능을 보여줍니다:
Guanaco 65B 모델은 Vicuna 벤치마크에서 ChatGPT가 보여주는 성능의 99.3%를 달성해서, 단 24시간의 파인튜닝 만으로 ChatGPT와의 격차를 좁혔습니다.
Guanaco 33B 모델도 아주 우수한 성능을 발휘해서, ChatGPT 성능의 97.8%를 달성했습니다.
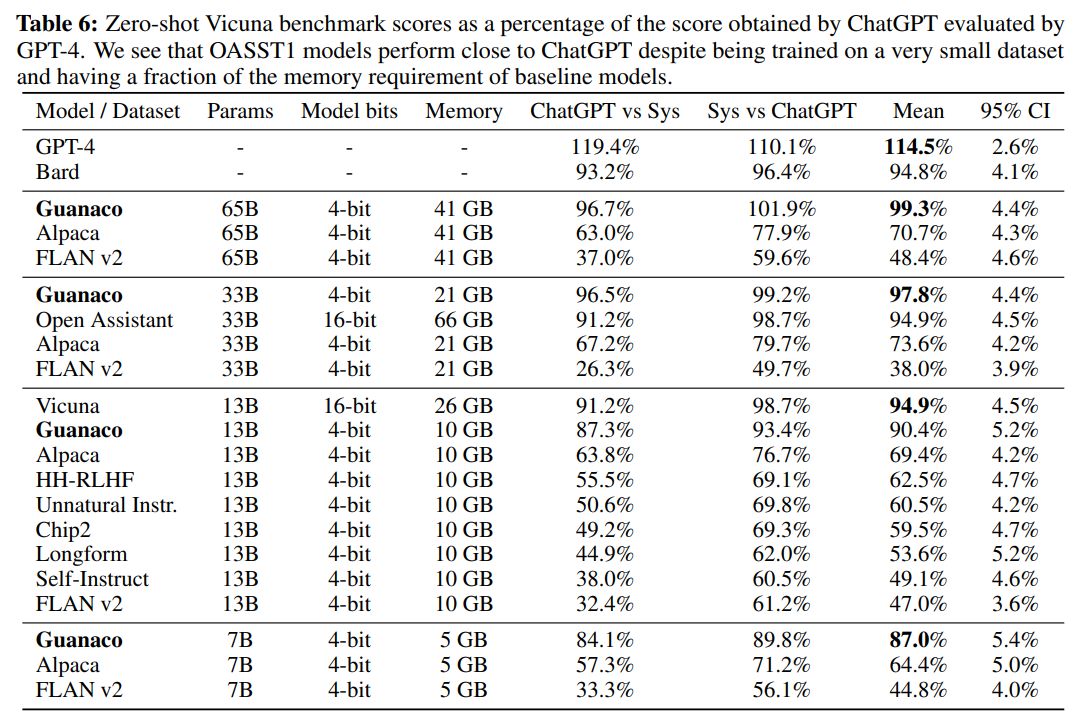
Image Credit: QLoRA 논문
“그런데 말입니다”…QLoRA를 사용하더라도, 모델을 GPU에 로드하는 데는 여전히 많은 메모리가 필요합니다. QLoRA보다 메모리 사용량을 줄이는 데 더 효과적인 방법이 있을까요?
그래서 나온 게 ‘QDoRA’입니다.
QDoRA는 QLoRA를 어떻게 개선한 건가?
‘QDoRA’는 아마도 예상하시다시피 QLoRA 프레임웍에서 LoRA를 DoRA로 대체해서, 가중치 행렬을 ‘크기’와 ‘방향’이라는 두 가지 요소로 분해하고 파인튜닝을 하는 고급의 기법입니다. 이 기법은 어도비의 머신러닝 엔지니어인 Kerem Turgutlu가 주도한 최근의 프로젝트 “Efficient Finetuning of Llama 3 with FSDP QDoRA”에서 소개되었는데, FSDP (Fully Sharded Data Parallel) - FSDP는 파운데이션 모델의 최적화 기술로, 튜링 포스트 코리아에서도 소개한 적이 있습니다 - 기법을 사용해서, 모델을 분할하고 여러 GPU에서 훈련해서 훨씬 더 효율성을 높여줍니다.
일률적으로 변경 사항을 적용하는 QLoRA와는 다르게, 파인튜닝을 할 때 좀 더 정밀하게 가중치를 조정할 수 있도록 하는 게 QDoRA입니다. 이렇게 Decomposition 기법과 Quantization 기법을 결합한 QDoRA는 QLoRA의 메모리 효율성을 유지하면서도 전체 파인튜닝의 유연성을 향상시켜 줍니다.
테스트 결과를 보면, QDoRA는 Orca-Math 데이터셋에서 LLaMA2-7B 및 LLaMA3-8B를 파인튜닝해서, 적은 메모리 사용양으로도 QLoRA로 파인튜닝한 버전 및 Full Fine-Tuning한 버전 모두를 능가하는 성능을 보여줬습니다. GPU 자원이 제한되어 있는 환경에서 QDoRA는 이상적인, 꼭 한 번 고려해 볼 만한 기법이라고 생각합니다.
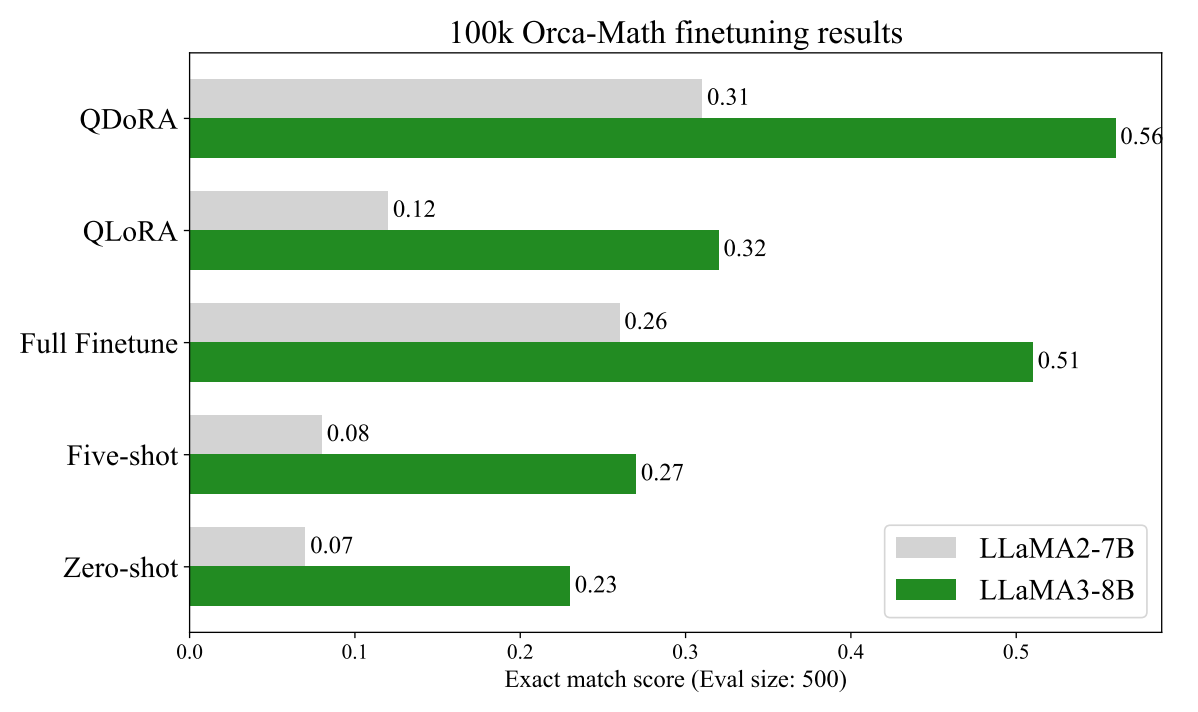
Image Credit: DoRA 논문
요약하자면, QDoRA는 메모리를 효율적으로 사용하게 하면서 더 유연하게 적응할 수 있고 성능을 높여주는 파인튜닝을 할 수 있도록 해 주는 기법입니다.
맺으며
오늘은 거대 모델을 파인튜닝해야 하는 경우에, 널리 알려진 LoRA 기법보다 더 효과적이라고 알려진 몇 가지 방법에 대해서 알아봤습니다:
DoRA는 LoRA 대비 더 유연한 접근 방식으로, 파인튜닝을 좀 더 쉽고 안정적으로 할 수 있게 도와줍니다.
양자화 (Quantization)를 활용하는 QLoRA 기법은 더 적은 메로리로도 거대 언어모델을 파인튜닝할 수 있도록 해 줍니다.
QDoRA는 DoRA와 QLoRA 기법을 결합한 기법이라고 볼 수 있는데, Full Fine-Tuning에 매우 근접하거나 그 이상의 성능을 발휘할 수 있도록 하는 효율적인 파인튜닝 기법입니다.
거대 언어모델을 사용할 때 하고자 하는 작업의 특성에 따라서, 어플리케이션을 최적화하기 위한 다양한 기법을 적용해야 합니다. 그 중 중요한 하나의 방법인 ‘파인튜닝’을 해야 하는 경우, 일반적으로 LoRA 기반의 파인튜닝으로 충분할 수도 있지만, 더 큰 모델을 효율적으로 메모리 사용량을 줄여 가면서 파인튜닝을 해야 할 경우에는 DoRA, QLoRA, QDoRA 등 다양한 파인튜닝 기법을 검토해 볼 필요가 있습니다.
보너스: 자료 소스
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!