

12일간 이어져 온 ‘오픈AI의 혁신’에 대한 발표, 그 마지막은 o3, 그리고 o3 mini가 장식했습니다.
마지막 발표가 어떤 거까 궁금했던 분도 계셨을 테고, 일부에서는 o1의 다음 버전일 거다라는 예상도 있었는데요. ‘o2’라는 이름은 영국의 통신사 O2와의 브랜드 충돌 때문에 바로 ‘o3’로 갔다고 합니다.
2025년의 이맘때쯤, 그리고 그 후에, 오픈AI의 이번 발표는 어떤 모습으로 기억되고 회자될까요?
12개 발표의 마지막을 장식한 o3. 그만큼 오픈AI에서도 o3가 이 모든 것을 종결하는 화룡점정 (畵龍點睛)이라고 생각했다는 뜻일 텐데요. 오늘 Community Twist에서는, 지난 12월 21일 공개된 o3에 대한 전문가들의 초기 반응과 의견, 그리고 생각을 간단히 공유해 볼까 합니다.
잠깐, 그 전에 지난 12일간 이어졌던 오픈AI의 발표를 한 번 흝어볼까요?
[1일차]
수학 및 과학적 추론을 더 잘 하고 더 정확한 답변을 제공하는 새로운 LLM, ChatGPT o1 출시로 ‘12가지의 발표’가 시작되었습니다. 더불어 200달러짜리 ChatGPT Pro 구독 프로그램도 발표했네요.
[2일차]
AI 모델이 답변을 만드는 과정에서 추론을 더 잘 할 수 있도록 하는 기법, ‘AI Reinforcement Fine-Tuning’ 출시했습니다 - 개발자 커뮤니티에 큰 의미가 있는 날이었네요.
[3일차]
이 날의 발표도 큰 화제가 되었는데요, 바로 AI 비디오 생성 도구 ‘Sora’를 출시한 날입니다. (그 사이에 구글의 Veo 2가 나오면서 그 둘 사이의 비교가 한창이긴 합니다).
[4일차]
‘Canvas’라는 이름으로 ChatGPT의 멋진 업그레이드를 발표했습니다. Canvas는 글쓰기 도구 등을 추가해서 코딩이라든가 텍스트 작업을 더 쉽고 원활하게 할 수 있게 해 줍니다.
[5일차]
ChatGPT - 애플 인텔리전스 연계 발표가 있었고, iOS 18.2 기능의 일부로 출시되었습니다. 그런데 출시 직후에 ChatGPT가 다운되는 일이 있었네요.
[6일차]
ChatGPT 고급 음성 모드에 비전 기능이 추가되어서, 화면에 있는 것을 볼 수 있고 사용자도 볼 수 있게 되었습니다.
[7일차]
ChatGPT 세션을 구조화하고 정리할 수 있게 해 주는 ‘Projects’ 기능을 추가했습니다. 개인적으로 꼭 필요한 기능이라고 생각해요.
[8일차]
대화형 검색 기능 ‘ChatGPT 검색’을 모든 ChatGPT 계정에 제공하고 고급 음성 모드에도 추가했고, 모바일에서 더 빠르게 작동하도록 했습니다.
[9일차]
다시 한 번 ‘개발자의 날’이었네요. 새로운 개발자 도구, 더 강력한 모델, 개발자에게 쓸모있을 성능, 유연성, 비용 효율성 관련 업그레이드를 발표했습니다.
[10일차]
일반 소비자의 영역으로 돌아와서, WhatsApp을 통해서 ChatGPT에 접근할 수 있도록 하는 기능을 발표했습니다 - WhatsApp에서 직접 ChatGPT에 문자를 보내고 미국 전화번호로 전화해서 음성 모드로 대화할 수 있습니다.
[11일차]
맥 버전의 ChatGPT 앱 관련된 발표가 있었죠. BBEdit, MatLab, Nova, Script Editor, TextMate 등 많은 새로운 앱을 지원하게 되었고, 데스크탑에서 다른 앱으로 작업을 하면서 고급 음성 모드를 사용할 수 있게 되었습니다.
[12일차]
지금까지의 모든 것을 마무리하는, 두 개의 새로운 모델이 발표되었죠 - o3, o3 mini입니다. 이 두 모델은 2025년 1월에 공식적으로 사용 가능하게 풀릴 것 같습니다. 두 모델 모두 추론 작업에서 뛰어난 성능을 발휘하게 설계되었고, 오픈AI가 보여준 자료에 따르면 기존의 다른 모델들을 훨씬 능가하는 성능을 보여줍니다 - ARC-AGI 벤치마크에서도 최상위 수준이네요.
자, 세 사람의 전문가들이 o3에 대해서 어떻게 생각하는지 한 번 알아볼까요? 조금 길지만, 천천히 같이 보시죠! 아래에 이어지는 내용은 다음과 같습니다:
Nathan Lambert의 평가
Nathan Lambert는 글로벌 선도 연구기관인 AI2 (Allen Institute for Artificial Intelligence; 앨런 AI연구소)의 머신러닝 연구자이자 AI 전문 미디어인 Interconnects의 설립자이기도 합니다. Nathan의 o3에 대한 (초기) 평가는 이렇습니다:

2024년을 쭉 뒤돌아봤을 때, 올해는 ‘2023년의 GPT-4 발표’ 정도의 임팩트가 있었던 이벤트는 없지 않나 생각하고 있었는데, o3가 연말을 장식했네요. o3는 o1 출시 때보다도 더 예상하지 못한 때에 등장했고, 2025년은 o3 덕분에 한층 더 역동적인 변화를 기대할 수 있는 한 해가 될 듯 합니다.
오픈AI의 o3는, 이제 ‘인터넷에서 모은 텍스트를 가지고 사전 훈련을 하는 방식’으로 더 얻을 만한 효과가 크지 않고, 업계 전체가 그에 대한 대안들 - 이 경우에는 ‘추론 중심의 모델’ - 을 찾기 시작했다는 중요한 신호로 이해해야 할 것 같습니다. o3의 중요한 성과를 아주 간단히 먼저 요약해 보죠:
o3는 ARC-AGI Prize를 대상으로 85%의 임계값을 넘긴 첫 번째 모델입니다. (참고로, 테스트셋이 아닌 퍼블릭셋에서 진행된 거고, 비용 관점의 제약도 초과한 것이기는 합니다)
아주 새로운 벤치마크인 Frontier Math 벤치마크에서도 SOTA 성능을 2%에서 25%로, 극적을 단숨에 끌어올렸습니다.
SWE-Bench_Verified 등의 중요한 코딩 벤치마크에서도 상당한 수준의 성과 개선을 이뤄낸 것으로 보입니다.
이 모든 발전이, 첫 번째 버전 발표 이후 단 3개월만에 이뤄진 일이고, 내년에는 더 빨라질지도 모를 일입니다. 게다가, 시간이 지나면서 추론 비용도 감소할 테니, 최소한 오늘날 우리가 알고 있는 ‘소프트웨어 엔지니어링’이란 건 조만간 전혀 다른 새로운 방식으로 작동할 거라고 생각합니다.
또 하나 중요한 건, 오픈AI에서 발표한 ‘Deliberative Alignment’ 블로그 포스트, 그리고 연구 논문인데요. o1급 모델들이 어떻게 안전성 (Safety)과 Alignment에 대한 연구를 더 잘 하도록 할 수 있는지 보여주고 있죠. 이런 ‘추론 능력’이 객관적으로 검증 가능한 영역 - 코딩이나 수학 - 외에서도 쓸모가 크지 않을까요? 이 부분도 2025년에 많은 관심을 가지고 시도해 볼 부분입니다.
o3 개요
12일간 이어진 이벤트의 마지막 날 발표된 o3, 이 모델은 Gemini 1.5 Pro, Claude 3.5 Sonnet New 등의 SOTA 모델을 크게 앞서는 모습을 보여줍니다.
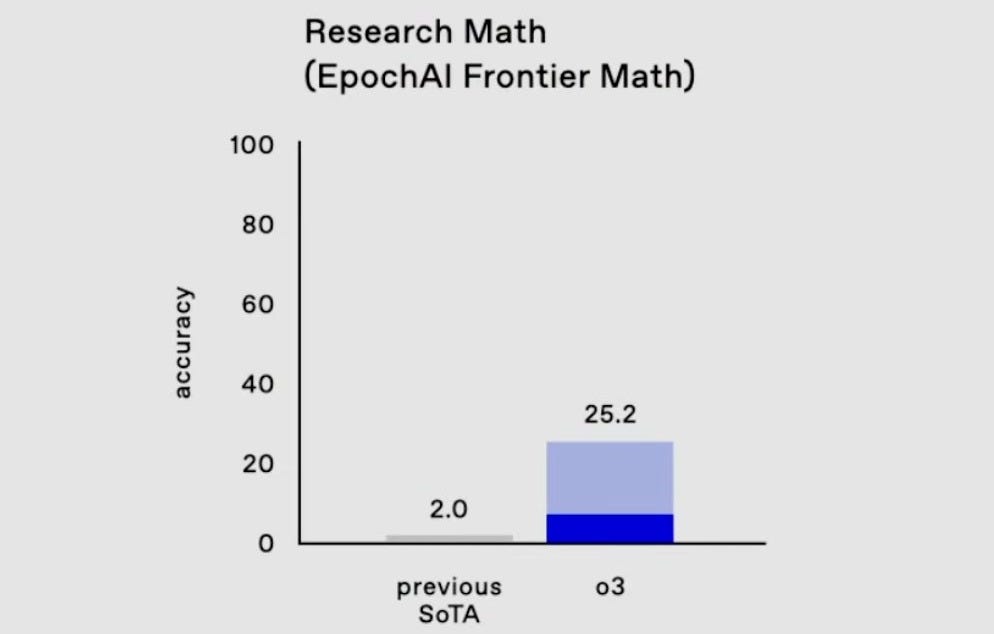
Image Credit: 오픈AI
o3 모델은 Codeforces (고난이도 코딩), GPQA Diamond (박사급 난이도의 과학 문제) 등의 다양한 영역에서 전문가 또는 그 이상의 결과치를 달성하는 모습을 보여줬는데요. 특히 위 그림에서 보듯 Frontier Math 벤치마크에서 기존 SOTA 모델을 압도하는 25%의 수치를 보여줬고, 수일 이상 걸리던 문제풀이를 단시간에 해결해 냈습니다.
그런데, 위 그림에서 명확히 보이지 않지만 잊지 말아야 할 건, 오른쪽 25.2% 바에서 희미하게 표시된 윗부분의 푸르딩딩한 영역이 의미하는 바가 뭐냐는 거예요. 이건 ‘o1 계열’의 모델에서 최상의 성능을 얻으려면 Multi-Pass Consensus (멀티패스 컨센서스)가 중요하다는 걸 보여주는데, 이건 어떤 종류건 ‘Inference-Time Compute’에는 동일하게 적용되는 겁니다. 물론, 꼭 트리 검색 같은 방식을 사용해야 한다는 건 아니지만, o1 Pro 모드나 ARC Prize의 결과도 그 훌륭한 결과의 이면에는 Multi-Pass를 동시에 만들고 이에 대한 합의를 하는 메커니즘이 있습니다.
두 번째로 ‘코딩 분야’를 살펴보면, o3은 SWE-Bench-Verified에서 71.7%, 그리고 Codeforces (경쟁 코딩 사이트)에서도 아주 좋은 성과를 보여줬습니다.

Image Credit: 오픈AI
o3는 컨센서스 투표로 2,727점을 얻었는데, 이건 ‘인터내셔널 그랜드마스터’ 수준으로 전세계의 경쟁 코더들 사이에서 상위 200위권이라고 하네요. o3-mini는 상당히 낮은 비용으로도 이미 o1의 성능을 뛰어넘는 모습을 보여주었는데, 여러 가지를 고려할 때 o3-mini가 일반 대중들이 더 많이 사용하게 될 영향력 있는 모델이 되지 않을까 합니다.
마지막으로 주목할 건, ARC-AGI 챌린지에서 뛰어난 성과를 보인 것인데요.
[*편집자 주: 참고로, ARC-AGI 챌린지에 대해서는 튜링 포스트 코리아의 이전 FOD에서도 말씀드린 적이 있는데요. - 궁금하신 분은 아래 링크를 클릭해 보시기 바랍니다.]

ARC Prize는 2024년 6월에 시작되었고, 특정한 기준에 따라서 비공개로 보관하고 있는 ARC 문제셋을 ‘처음’ 해결하게 되면, 자그마치 100만 달러의 상금을 수여합니다 - 이 과제를 ‘해결’했다고 간주하려면 정확도가 85%를 넘어야 하구요. (정확도만이 유일한 기준은 아니고, 과제를 수행하는데 드는 ‘비용’적 요소, 그리고 ‘오픈 소스로 공개’되어야 한다든가 하는 부가적 기준도 있습니다 - ‘efficient 85% solutioin is open-sourced’라고 주최측은 표현하고 있네요.)
이번 o3 모델에 대해서 오픈AI와 ARC Prize 측은 아래와 같은 결과를 공개했죠:
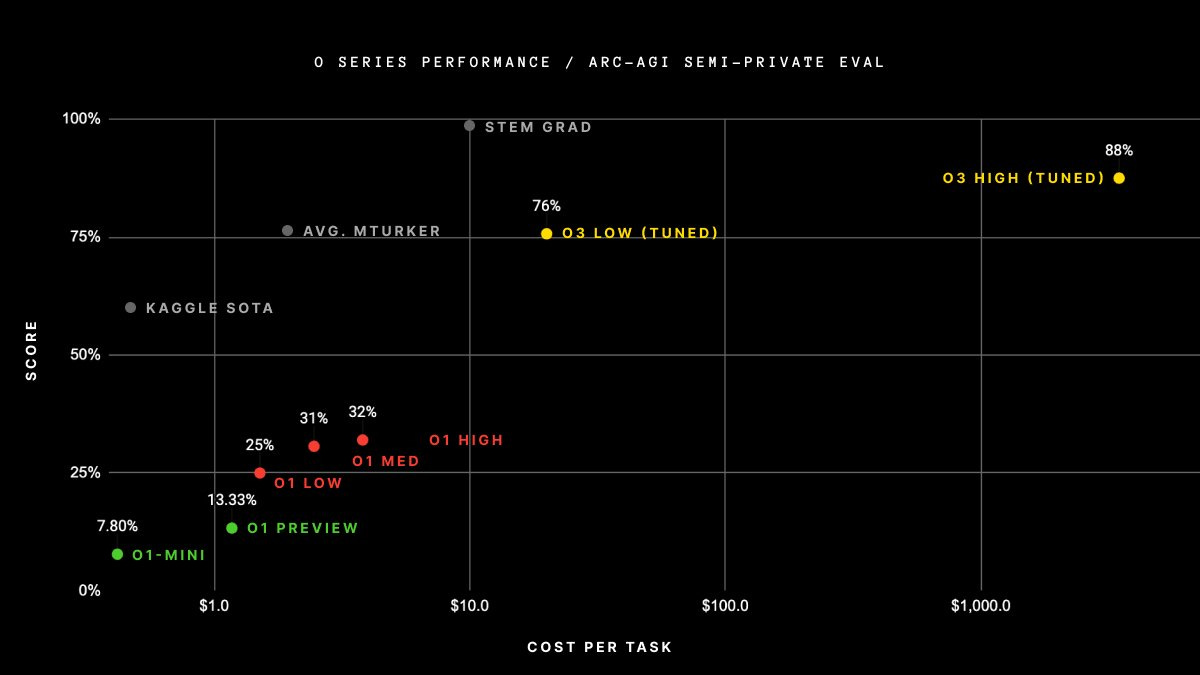
Image Credit: ARC Prize
위 그림에서 x축은 ‘(계산하는데 필요한) 비용’을 뜻하는데, 이건 논외로 하구요.
o1급 모델이 나오기 전에는 오픈AI의 최고 모델인 GPT-4o도 정확도가 5% 수준에 불과했어요. ARC Prize의 공동 설립자인 Mike Knoop가 ARC Prize를 기준으로 한 모델들의 발전 속도를 간단히 정리한 것을 살펴보면 놀랍습니다:

Image Credit: Mike Knoop의 X 포스트
지난 6월에만 해도, ARC-AGI 문제 해결은 극도로 어렵다는 이야기가 지배적이었는데, 이제 상황이 많이 바뀌게 됐죠. 아마 Q*를 비롯한 다른 ‘추론’ 기법에 대해 관심을 가지고 낙관적으로 보던 사람들도 이 정도 수준의 발전을 예상하진 못했을 거예요.

Image Credit: ARC Prize
Francois Chollet가 공유한 좀 더 상세한 내용을 간단히 살펴보면 아래와 같습니다:
오픈AI와 ARC Prize가 함께 두 가지의 ARC-AGI 데이터셋으로 o3를 테스트했습니다:
Semi-Private Eval: 과적합을 평가하기 위한 100개의 비공개 과제
Public Eval: 400개의 공개된 과제
오픈AI가 제공한 가이드에 따라, ARC Prize는 6개 (고효율 모드), 1024개 (고성능 모드, 약 172배의 컴퓨팅 사양)의 샘플 사이즈에 대해서 테스트를 진행했고 그 결과는 다음과 같습니다

주: o3의 고성능 컴퓨팅 비용은 가격 책정이라든가 기능의 가용성 등이 결정되지 않아서 제공되지 않음. 컴퓨팅 사 양 관점에서는 대략 저성능 컴퓨팅 구성의 약 172배임. Image Credit: ARC-AGI Prize 웹사이트
여전히 (사람에게는 쉽지만) o3가 풀지 못한 문제들이 있고, 아래에 그 예가 있습니다:
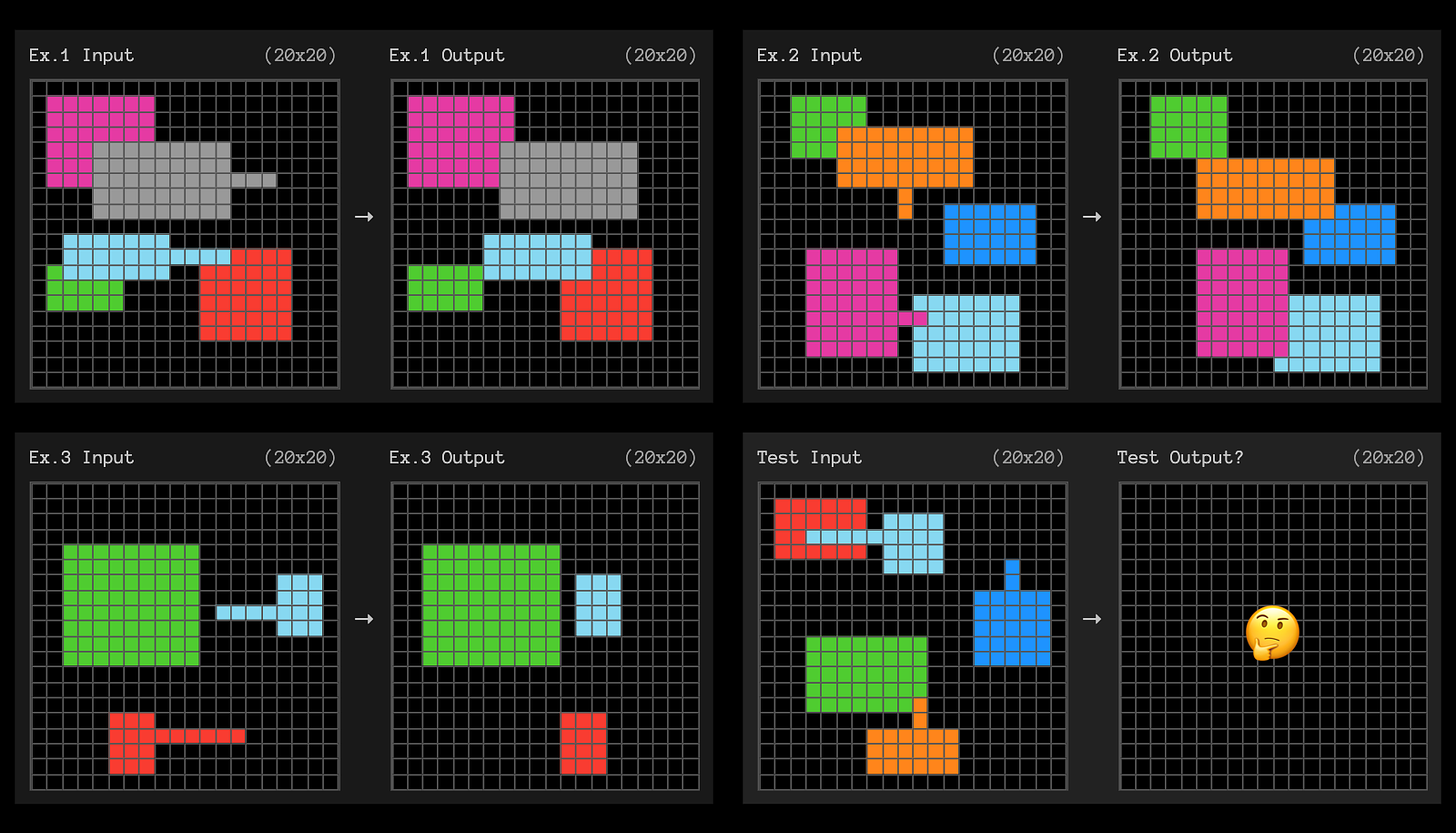
Image Credit: ARC-AGI Prize 웹사이트
위 그림은, 예시 1번에서 3번까지의 ‘입력’ - ‘출력’ 이미지 간 관계를 보고 마지막 입력에 대해서 출력이 어떻게 될지 맞춰보는 건데요. 사람이 보기에는 아주 직관적으로 풀 수가 있는 건데도 o3는 실패하는 패턴을 보여주고 있습니다.
(위에서 잠깐 언급한 것처럼) 기술적으로는, 비용 임계값을 초과했기 때문에 o3에 ARC Prize의 상금은 수여되지 않겠지만, 추론을 둘러싼 진짜 경쟁이 이제 시작되었다고 봅니다. 앞으로 몇 년 안에, 이런 종류의 ‘추론’ 능력은 사실상 거의 공짜에 가깝게 제공되는 상황이 전개될 것으로 봅니다 - 물론 여기서 ‘공짜’란 건 사용자의 광고 데이터가 가지는 금전적 가치 대비 추론 실행 비용이 저렴하게 된다는 뜻이죠.
o3 아키텍처, 비용, 훈련 방식
오픈AI와 직접 협력하면서 o3를 테스트한 ARC-AGI 팀은 o3 모델의 사용에 따라오는 비용을 추정해 보기도 했는데요. ‘Interence Scaling Law (추론 스케일링 법칙)’에 따라서 모델 운용 비용이 빠르게 줄어드는 추세가 나타났기 때문에, ARC-AGI에서는 비공개 평가를 하기 위해 솔루션을 제출할 때 새로운 비용 기준을 추가했어요. (참고로, ARC-AGI의 게시물을 보면, 총 비용과 작업 - Task - 당 비용을 FLOP, 즉 직접적인 컴퓨팅 자원 사용량의 프록시로 사용하고 있습니다)
500개의 태스크/작업 (Public Eval 셋 400개 + Semi-Private Eval 셋 100개)을 해결하는데, 최대 $10,000 USD까지 - 상업용 API 호출 비용 포함 - 허용
o3는 이 한도를 크게 초과한 비용을 사용했을 뿐 아니라, 쿼리 당 $1K를 훨씬 넘는 걸로 나타났습니다.
이 o3 모델 아키텍처나 운용 방식의 핵심적인 내용에 대해서는, 공개된 바가 없어 추측만 가능할 뿐인데요. Francois Chollet는 o3의 핵심 메커니즘이 ‘토큰 공간 내의 자연어 프로그램 검색/실행’인 것 같고,아마 알파제로 스타일의 MCTS (몬테카를로 트리 검색) 비슷하지 않을까 생각한다고 했습니다.
o1나 o3 모델이 하나의 언어모델로 순방향 패스만으로 구현한다는 건 많은 사람들에게 사실상 충격에 가까운 일일 테니, 그런 추측도 이해가 안 되는건 아니지만, 대규모의 강화학습 훈련을 잘 한다면 가능하다고 생각합니다 - 이런 관점에서, o1 모델과 공개했던 성능 그래프에서 ‘추론 시간에 사용되는 컴퓨팅 자원’ 부분은 오해의 여지가 있습니다. (이 내용에 대한 자세한 내용은 여기를 참고해 주세요.)
어쨌든, ARC Prize의 결과를 액면 그대로 받아들이고, 오픈AI의 o1 모델 가격이었던 ‘백만개 출력 토큰 당 60달러’ 비용을 기준으로 살펴봅시다.
ARC Prize에서 제시한 그래프에서, o3를 ‘완전히’ 사용할 때 쿼리 당 약 5,000달러의 비용이 발생하고, 총 비용을 토큰 당 가격으로 나누면 답변 당 8천만 토큰을 생성한다는 건데, 이건 Long-Context 모델의 혁신 없이는 불가능한 수치죠 - 그래서 ‘혹시 다른 검색 아키텍처를 사용하는게 아닌가’ 하는 추측이 나온 거겠죠.
SemiAnalysis의 분석에 따르면, o1 pro는 동일한 쿼리에 대해서 만들어진 여러 개의 답변 중에 가장 공통적인 답변을 선택하는 ‘Self-Consistency’ 기법 또는 consensus@N 체크 기법을 사용한다고 합니다. 여기서 짐작해 볼 수 있는 건, o3가 o1 pro에 해당하는 구성에서 고객이 사용할 수 있는 일반적인 세팅, 6배의 계산량을 사용하는 세팅, 그리고 문제 당 1024배 계산량을 사용하는 고성능 구성으로 만들어진 것이 아닌가 하는 겁니다. 대규모의 추론은 물론 일반의 유료 사용자들에게는 당분간 제공되지 않을 것 같구요.
‘백만개 출력 토큰 당 60달러’라는 동일한 가격을 가정하고 1024 스트림으로 나누면, 모델이 답변 당 약 7.8만개의 토큰을 생성하는 셈이죠. 실제로는 오픈AI가 라이브 스트림에서 보여준 모든 로그 계산 x축에서 o1 모델보다 계산 비용이 크게 증가한 것을 보면, o3는 아마도 파운데이션 모델 자체가 더 대형으로 만들어진 거라고 봐야겠죠. 그렇다고 가정하면, 이 결과치들은 나름 합리적으로 볼 수 있는 정도고, Francois가 추측한 것 같은 추가적인 ‘검색’ 요소는 필요하지 않다고 생각합니다.
최근 몇 년을 되짚어 보면, AI (생성 AI)의 발전을 이끈 첫 번째 물결은 ‘인터넷 그 자체 규모의 데이터를 활용한 사전 훈련’이었죠. 이제 오픈AI는 강화학습 훈련, 그리고 Long-Context 기반의 추론 스케일링을 통해서 새로운 발전의 경로를 찾은 것이 아닌가 합니다. o3가 o1 출시 후 약 3개월만에 나온 모델이니만큼, 가장 간단한 설명은 ‘동일한 아키텍처, 동일한 훈련 방법론'을 확장한 것일 거다라는 거겠죠.
궁금한 건, o3의 파운데이션 모델이 GPT-5가 될 걸로 예상되는 Orion인지, 아니면 새로운 파운데이션 모델이 훈련하는 시점에 기존에 있었던 Orion의 혜택을 받은 건지 하는 거네요.
아직 o3의 구체적인 실체에 대해서는 불확실한 점이 많이 있습니다만, ‘발전의 방향성’이라는 관점에서는 ‘o1급 모델이 앞으로 계속 발전할 것’이라는 점만은 분명합니다.
Gary Marcus의 생각
Gary Marcus는 세계적인 인지과학자로 뇌과학, 진화심리학, 언어학을 넘나들면서 ‘마음의 기원’을 연구하는 학자인데요. 뉴욕대학교 심리학·신경과학 명예교수이기도 하고, Rebooting.AI (포브스지 선정 ‘AI 영역 7대 서적’)를 포함한 다양한 책을 쓴 작가이자 우버가 인수한 Geometric Intelligence의 창업자/CEO이기도 합니다. 더불어, 얀 르쿤, 제프리 힌튼 등을 포함하는 유수의 AI 전문가들과 격렬한 논쟁을 벌이기로도 유명한 대표적인 ‘AI 회의론자’이기도 합니다. (*편집자 주: 사실 AI 회의론자라기보다는, ‘현재의 AI는 진정한 생각이나 추론을 하는 기계가 아니다’라는 강한 입장을 가지고 있는 ‘AI 실용주의자’라고 저는 생각합니다.)
Gary의 o3에 대한 (초기) 평가는 이렇습니다:
.

12월 21일은 AI의 역사에 한 획을 긋는 중요한 날이었습니다 - 어쩌면 아닐지도 모르구요 ^.^;
오픈AI가 25분짜리 라이브 데모를 통해서 o3를 공개한 후, AI 열성론자들은 이 ‘데모’가 AGI다, AGI에 아주 근접했다, AGI로 가는 중요한 단계를 보여줬다고 이야기하고 있습니다.
가장 좋은 수치들로만 본다면, 상당히 인상적입니다 - 예를 들어서, Francois Collet의 ARC-AGI 챌린지라든가, FrontierMath 같은 고도의 수학 벤치마크 등에서 큰 진전을 보여준 걸로 보입니다.
그렇지만, 다른 모든 것처럼, 보이는 것 뒤에서 ‘보이지 않는 것’도 그만큼 중요하죠. 오픈AI가 보여준 건 ‘아주 조심스럽게 선별한 데모’였고, 일반 대중은 실제로 이걸 시험해 볼 기회가 - 적어도 아직 - 주어지지 않았죠. 보여지지 않은 것들에 대해서는 아래에서 다시 논의할께요.
오픈AI의 데모 전에, 제가 ‘세 가지의 예측’을 했었는데요:
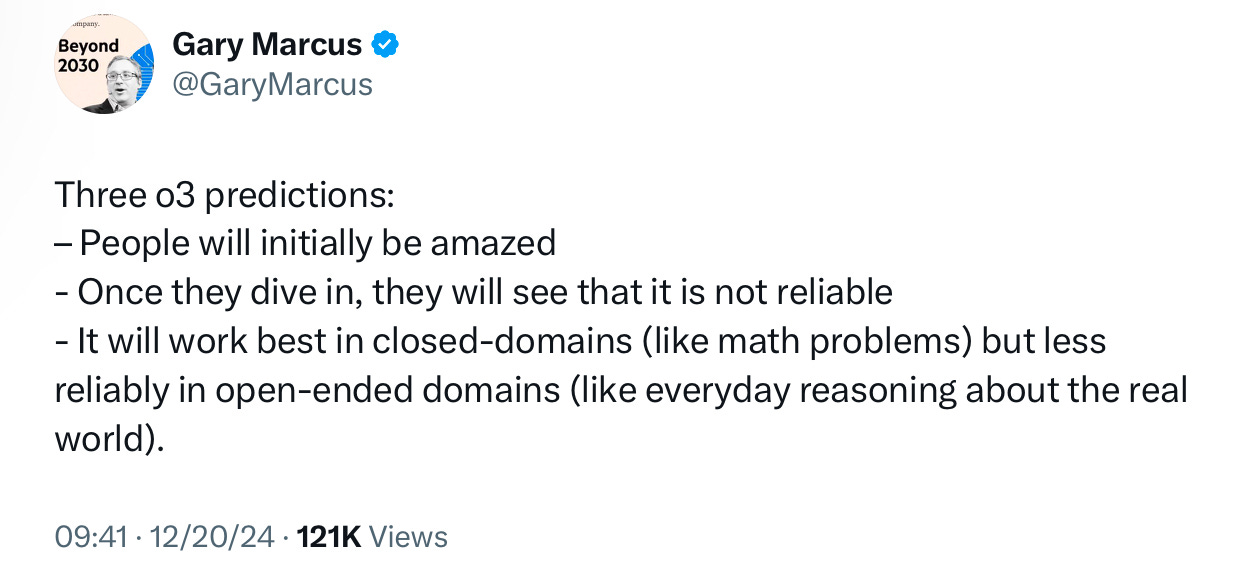
Image Credit: 게리 마커스 X 포스트
사람들이 놀란 (Amazed) 건 분명하죠? 그렇지만 o3에 딥다이브해 볼 기회는 (아직) 없었죠. 아직까지 우리가 본 아주 조심스럽게 선택된 데모였을 뿐입니다.
이 ‘제품’은 아직 일반 대중에게 공개되지 않았고, 과학계의 제대로 된 검증도 받기 전입니다. 오픈AI가 o3에 대해서 뭘 강조해서 이야기할지 선택했고, 외부 전문가들이 그 범위를 시험해 볼 수 있도록 허용하지 않았어요. (Francois Chollet를 포함한 ARC-AGI 팀이 하나의 과제를 놓고 시험한 것만 빼면요)
돌이켜 보세요. 이전에도 우린 여러 가지 오픈AI의 데모들을 봤는데, 그것들 중 아직 실현되지 않은 것들도 많아요. 예를 들어서, 지난 5월에 Sal Khan이 시연한 ‘GPT-4 기반 튜터’는 아직 어떤 형태의 테스트도 공개적으로 할 수가 없어요. 2019년 Rubik’s Cube 데모도 일반인들이 시도해 볼 만한 어떤 걸로 연결되지 않았구요.
많은 사람들이 o3를 다양한 종류의 과제에서 시도해 보기 전까지는, 이게 ‘신뢰할 만한 결과’라고 가정할 필요도 없고, 그래서도 안됩니다. 지금 다시 예측해 보자면, 기껏해야 일부 종류의 문제에서는 쓸만하지만 다른 많은 문제들에서는 그렇지 않을 겁니다.
핵심은, ‘아직 보여지지 않은’ 것들이 있고, 거기에 주목해야 한다는 겁니다. 21일 우리가 본 건 본질적으로 수학, 코딩, 그리고 Francois의 ARC Prize가 강조하는 특정한 스타일의 IQ 퍼즐 같은 종류에 대한 o3의 선별된 성능 결과예요. o3가 정확히 어떻게 작동하는지, 훈련은 뭘 가지고 어떻게 했는지 우리는 모릅니다. 그리고, 사전에 문제를 합성해서 대규모로 Data Augmentation을 할 수 없는 ‘개방형 (Open-Ended)’ 문제에 적용되는 것도 못 봤구요. ‘가장 중요한 질문은 실제로는 하지 않은’ 거예요.
또 하나, o3는 엄청나게 비싸요. 적어도 지금은, 평균적인 사람보다 훨씬 더 비싸다는 뜻이에요. 제가 본 한 추정치에 따르면, 시스템 한 번 호출하는데 1,000달러가 들고, 다른 추정치로는 Francois의 테스트에서 가장 정확한 - 고성능의 - 버전의 비용은 Amazon Mechanical Turk 작업자를 고영할 때보다 약 1,000배 더 비쌌다고 합니다.
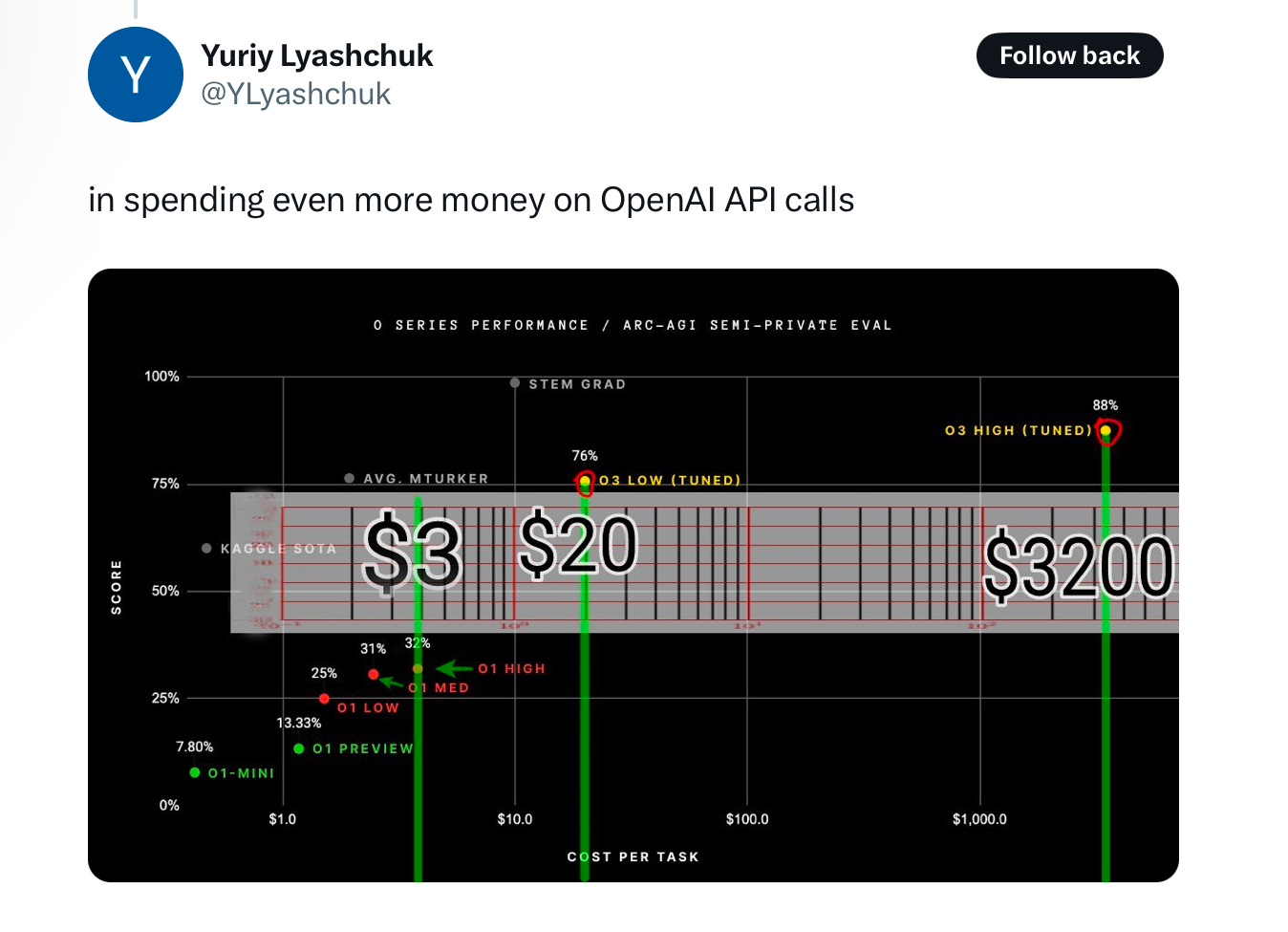
평균적인 사람(이 작업할 때 드는 비용)보다 1,000배 더 비싼 뭔가를 만들려고 ‘25조 달러’를 쓰는 것은, 글쎄요, 좋은 방향일까요?
미래에, 그 비용이 1,000배 정도 줄어든다고 합시다. 그래도 상위권의 STEM 졸업생만큼 좋지도 않고, 여러 면에서 그만큼 다재다능하지도 않을 거라고 생각합니다.
결국, o3를 둘러싼 ‘경제성’을 저는 이해하기 어렵습니다. 또 하나, 이 모든 게 환경에 미치는 영향도 엄청날 거예요.
소셜 미디어 포스팅에서, 이전에 제가 o3 같은 ‘데모’를, 오도되지 않고, 잘 이해하고 생각하는 방법에 대해서 몇 가지 조언을 적어놓은 적이 있는데요:
철학의 기본 개념: ‘필요 조건’이 곧 ‘충분 조건’인 건 아니예요. 예를 들어서, ARC-AGI라는 챌린지를 통과하는 게 AGI를 달성하는데 ‘필요’한 과정일 수는 있지만 분명히 ‘충분’한 조건은 아닙니다. (Francois Chollet도 이 점을 명확히 했습니다.)
인지과학과 공학의 기본 개념: 어떤 메커니즘은 특정한 영역에서는 효과적이지만 다른 영역에서는 효과가 그보다 못하거나 아예 없을 수도 있습니다. o3의 경우, 대규모의 Data Augmentation이 가능한 문제에서는 작동할 수 있지만, 그렇지 않은 다른 문제에서는 작동하지 않을 수 있는 거죠.
제가 보는 대부분의 o3 논평은, 이 두 개의 개념들 중 하나, 또는 둘 다를 생각조차 하지 않고 있습니다.
‘1,000배의 비용’은 제쳐두더라도, 오픈AI 외부의 어느 누구도 다양한 유형의 문제들에 걸쳐서 o3가 얼마나 견고하게 작동하는지 평가한 적이 없습니다.
자, 만약 o3가 모든 문제 - 적어도 대부분의 문제 - 에서 정말 견고하게, 잘 작동했다면….저는 오픈AI가 이걸 o3가 아니라 GPT-5라고 불렀을 거라고 생각합니다. 그렇지 않다는 건, 사실 o3의 작동 범위가 중요한 한계를 가지고 있다는 강력한 암시예요.
o3 데모에서 보여준 결과에 흥분한 많은 팬들이, 너도나도 Francois가 쓴 글에서 ‘긍정적인’ 표현을 인용하고 있죠. 하지만 그 글의 가장 중요한 부분까지 자세히 읽어본 사람은 거의 없는 것 같습니다.
ARC-AGI가 ‘AGI가 달성되었는지를 확인하는 완벽한 시험이 아니’라는 점을 주목하는 것이 중요합니다 - 올해 수십 번 반복해서 말한 것처럼요. ARC-AGI 챌린지는, AI가 가장 어려워하는, 해결되지 않은 문제들에 모두의 주의를 집중시키기 위해서 설계된 연구 도구예요. 그리고 지난 5년 동안 이 역할을 잘 수행해 왔습니다.
‘ARC-AGI 챌린지를 통과한다’는 것과 ‘AGI를 달성했다’는 건 같은 말이 아니고, 사실 저는 o3가 아직 AGI라고 생각하지 않습니다. o3는 여전히 아주 쉬운 일부 과제들도 풀지 못하는데, 이게 바로 o3가 사람의 지능과 근본적인 차이가 있다는 걸 보여줍니다.
더불어서, 지금 볼 수 있는 초기의 데이터를 보면, 곧 출시될 ARC-AGI-2 벤치마크가 o3 관점에서 상당한 도전 과제가 될 거라는 걸 알 수 있습니다. 고사양의 컴퓨팅 성능에서도 o3의 점수가 30% 미만으로 떨어질 수 있습니다 (똑똑한 사람이라면 훈련이 없이도 여전히 95% 이상의 점수를 낼 수 있을 겁니다).
장담하건데, 2025년에는 수많은 AI 인플루언서들, 그리고 일부 AI 기업들이 ‘드디어 AGI를 달성했다’고 주장할 겁니다 - 도대체 AGI가 뭐라고 생각하는지, 그 정의를 명확하게 제시하지 않은 채로요.
저는 개인적으로 2022년에 AGI에 대한 몇 가지의 정의, 그리고 그 정의를 뒷받침하는 예시를 제시한 적이 있습니다. 올해 초에도 예시를 추가했구요. 각각의 경우에 대해서 제 예측에 대해서 꽤 큰 금액이라도 베팅을 걸 생각이 있었고, 지금도 그 생각은 변함이 없습니다.

2024년 4월 게리 마커스가 예측한, ‘2025년에 일어나지 않을 일들’
AGI에 대해서 진지하게 생각을 하거나, 관련된 일을 하는 다른 분들, 기업들도 명확한 기준선을 제시하기를 바랍니다 - 실제로 그렇게 할 거라고 생각하지는 않지만요. 결국, ‘소비자가 눈을 부릅뜨고’ 조심해서 상품을 살펴봐야 할 거예요. (Caveat Emptor!)
몇 달 전에 제가 ‘AI 추론의 한계’에 대한 애플의 논문, 그리고 이게 제가 26년 전부터 이야기하기 시작한 핵심적인 요점과 어떻게 관련되는지 글을 쓴 적이 있는데요: 신경망은 ‘Outside Distribution’보다는 ‘Within Distribution’ 일반화를 더 잘 하는 경향이 있다는 겁니다. Qin, Saphra, Alvarez-Mellis가 최근에 발표한 새 논문에서도 이 점을 다시 한 번 지적하고 있습니다.

Image Credit: 오리지널 논문
적어도 제가 볼 때는, 지난 21일의 o3 발표에서는, 수십 년 된 이 핵심적인 문제가 조금이라도 해결되었다는 걸 시사하는 내용이 전혀 없었습니다.
물론, 제가 ‘우리는 AGI에 절대 도달하지 못할 거예요’라고 말하는 게 아닙니다. 다만, 수많은 기본적인 문제들이 아직 해결되지 않았다는 점을 강조하는 겁니다. 그리고 전세계의 모든 로봇공학자들이 잘 알고 있듯이, 제품이 실제로 출시되고 외부의 적절하고 완전한 검증을 받기 전까지는 ‘데모를 심각하게 받아들여서는 안 된다’는 말을 하는 겁니다.
어제 X에서 TauLogicAI라는 ID를 가진 분이 우아하게 표현한 것처럼요:
‘AGI에 도달했는지 확인하는 기준’을 낮추는 건, AGI를 향한 우리의 진전과 노력을 혼란스럽게 할 뿐입니다. 진정한 AGI는 정확성, 적응성, 논리적 일관성을 보장하는 추론 프레임웍을 필요로 합니다. AGI의 꿈은 통계적인 트릭으로 실현되는 것이 아니라, 진정한 논리적 추론이 가능한 시스템을 구축함으로써 실현될 것입니다.
저도 전적으로 동의하지 않을 수 없네요. 21일 오픈AI의 데모, 그리고 살짝 우리에게 보여준 결과가 아무리 인상적이었다고 하더라도, 원칙을 변화시킬 수는 없습니다.
Jim Fan의 의견
‘오픈AI의 첫 번째 인턴’으로 알려져 있는 Jim Fan은 엔비디아의 시니어 리서치 매니저이자 GEAR Lab (Embodied AI)의 리더로, 휴머노이드 로봇이나 Physical AI 영역에 많은 관심을 가지고 인사이트를 제공하는 연구자인데요.
Jim Fan이 o3를 바라보는 관점은 이렇습니다:

다른 분들이 많이 언급하신, 훌륭한 추론 능력과 점수 등에 관련된 이야기는 건너뛸께요. 제가 보는 관점에서 o3의 본질은, ‘Single-Point RL Superintelligence (단일 지점 강화 학습 초지능)’을 잘 만져서, 의미있고 유용한 문제 공간 (Problem Space)에서 더 많은 지점 (Point; 즉, 더 많은 영역의 문제)을 다루게 된 거라고 생각합니다.
이미 AI 학계와 업계에서는 ‘강화 학습 (RL)’이 사람을 넘어서 거의 ‘신급’의 성과를 내는 걸 본 적이 있죠:
알파고는 어떤 의미로 ‘초지능 (Superintelligence)’이었습니다. 보통 바둑기사들의 99.999% 이상을 뛰어넘고 세계 챔피언을 이겼습니다.
알파스타도 ‘초지능’이었죠. 스타크래프트에서 최고의 e-스포츠 챔피언 팀들을 이겼습니다.
보스턴 다이나믹스의 e-Atlas도 일종의 ‘초지능’이었다고 생각합니다. ‘완벽한 백플립’을 항상 해내죠. 대부분의 사람의 두뇌는, 자신의 팔과 다리에 그렇게 정밀한 제어 신호를 보내지 못합니다.
AIME, SWE-Bench, FrontierMath 등의 벤치마크에 대해서도 비슷하게 이야기할 수 있겠죠 - 이 각각의 영역이, 바둑같이 평균적인 사람들의 99.99…% 이상의 전문성이 필요한 영역입니다. o3는, ‘이런 영역’에서 작동할 때 ‘초지능’의 모습을 보입니다.
핵심적인 차이점은, 알파고가 아주 단순한, 거의 시시하다고 할 만큼 단순하게 정의된 ‘보상 함수’를 최적화하는데 ‘강화 학습 (RL)’을 사용한다는 거예요. 반면에, 정교한 고도의 수학이라든가 소프트웨어 공학 영역에서의 ‘보상 함수’를 학습하는 건 훨씬 더 어렵습니다.
o3는 오픈AI가 우선시하는 이 영역에서 ‘보상 문제’를 해결하는 혁신을 이뤄낸 겁니다. 더 이상 ‘단일한 작업을 위한 강화 학습 전문가’가 아니라, ‘더 큰 범위의, 여러 가지의 유용한 작업들을 위한 강화 학습 전문가가 되었다는 거죠.
그렇지만, o3의 ‘보상 엔지니어링’이, 사람이 인지하는 영역에 해당하는 ‘Distribution’을 커버하지는 못했다는 것 또한 명백합니다 - 여전히 우리는 ‘모라벡의 역설’에 갇혀 있는 거죠. o3가 필즈상 수상자들을 감탄하게 할 수는 있겠지만, 아래 그림같이 5살 짜리 어린아이도 풀 수 있는 퍼즐을 풀지 못합니다. 알파고가 바둑이 아닌 포커 게임에서 승리할 거라고 뜬금없이 기대하지 않잖아요? 놀랄 일은 아닙니다.

Image Credit: ARC Prize 웹사이트
o3, 의미있는 거대한 이정표를 보여줍니다. 앞으로 우리가 걸어야 할 길도 명확하죠. 할 일이 많습니다.
맺으며
지난 12월 21일, 2024년의 대미를 장식하면서 많은 사람들의 관심과 반응을 이끌어내고 있는 오픈AI의 o3. 여기에 대해서 다양한 관점을 가진 전문가의 생각과 의견을 공유드렸습니다. 앞으로 균형잡힌, 그리고 사실에 기반한 AGI에 대한 논의, o3에 대한 평가가 생산적으로 이루어지면 좋겠다고 생각합니다.
제대로 된 o3에 대한 평가는 내년 초부터 더 구체적으로 진행되기를 기대하고, 여기 현실에 있는 우리는 o3에 대해서 지나친 상찬을 할 필요도, 또 반대로 완전히 부정을 할 필요도 없을 겁니다. 과연 o3 같은 파운데이션 모델을 우리가 직접 만드는게 좋으냐 아니냐, 만들 수 있느냐 없느냐 하는 ‘소버린 AI’에 대한 논의는 차치하구요. o3와 같은 모델도 - 다른 수많은 형태의 모델들과 함께 - 근미래에 우리의 문제를 해결할 하나의 ‘도구’로 자리잡으리라는 전제 하에 이걸 ‘어떻게 활용할까’에 대한 고민을 하는 분들도 많이 생겼으면 좋겠습니다. 그러기 위해서라도 Gary Marcus가 유지하는 태도처럼, o3 - 그리고 이를 비롯한 ‘추론 중심의 모델’ - 에 대한 냉정하고도 객관적인 관찰, 평가가 더 중요하구요.
o3가 ‘Step-Change (한 단계를 돌파하는)’에 해당하는 혁신이라는 건 분명해 보입니다. Jim Fan이 이야기한 것처럼, o3는 ‘단순한’ 보상 함수를 기반으로 한 ‘단일한’ 작업에 제한되지 않고, 비록 완전한 커버리지는 아니라 하더라도 ‘복잡한’ 보상 함수를 엔지니어링해서 ‘다수의’ 작업에서 사람에 가까워지고, 때로는 넘어섰다고 할 만한 성능을 보여줍니다.
o3의 극적인 등장과 함께 ‘추론' 경쟁에 참여하는 사업자, 모델들도 연이어 등장할 것으로 예상됩니다. 이미 구글은 Gemini 2.0 Flash Thinking을 공개했고, 오픈소스 진영에서도 빠른 움직임을 보여주면서 아마 내년 상반기 중에는 ‘추론’ 중심 모델을 발표하는 모습을 보게 되리라 생각합니다.
Nathan Lambert와 Jim Fan이 공통적으로 지적한 것처럼, 이 혁신의 기반에 ‘강화 학습’이 자리하고 있습니다. 2016년 알파고와 이세돌 9단의 대국을 통해서 우리, 그리고 전세계를 놀래켰던 ‘강화 학습’이 다시 한 번 무대에 본격적으로 등장하는 2025년이 될 것 같습니다. 특히, 생성AI, 멀티모달, 그리고 물리적인 세계를 포함하는 월드 모델과 강화 학습을 어떻게 잘 통합하느냐가 내년, 그리고 그 이후 AI의 발전 속도를 결정짓는 하나의 중요한 가늠자가 되지 않을까 합니다.
리차드 서튼의 책을 다시 꺼내봐야 하려나요? ^.^;
읽어주셔서 감사합니다. 친구와 동료 분들에게도 뉴스레터 추천해 주세요!